同城刘德华标签推荐与猜你想找算法实践

分享嘉宾:刘德华博士 58同城 架构师
编辑整理:吴祺尧
出品平台:DataFunTalk
导读: 58本地生活搜索推荐场景具有同质化、人群结构复杂、决策周期复杂,以及多行业、多场景、多种类、多目标的特点。针对以上特点,58本地服务提出了针对性的解决方案。本次分享内容为58本地生活搜推算法的演进。
今天的介绍会围绕下面四点展开:
- 58本地服务推荐场景与特点
- 58本地服务标签推荐演进
- 58本地服务帖子推荐演进
- 未来展望
01 58本地服务推荐场景与特点
首先和大家分享下58本地服务推荐场景。
本地服务涉及的行业种类特别多,目前涵盖了200多个行业,它们各自有各自的特点,可以分为长周期和短周期、重决策和轻决策等。此外,由于行业类目特别多,导致用户很难找到自己想要的东西,使得本地服务的用户触达较难。
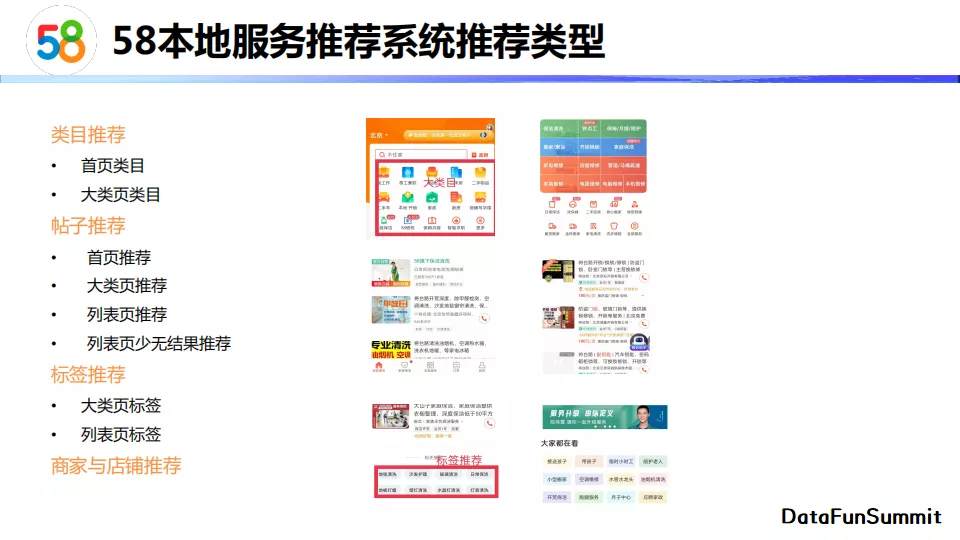
58 app大致有四类推荐场景。首先,首页包含大类目推荐。点开大类目后进入大类页。大类页中包含二级类目的推荐和热门帖子、热门服务的推荐以及标签推荐。在点击进入具体帖子后会进入详情页,详情页下方有相关服务和商家的推荐。
我们的推荐场景具有以下一些特点:
- 信息同质化 :很多帖子区分度较差,信息堆叠比较严重;
- 人群结构复杂 :存在未登录用户、新用户、低活用户等;
- 决策周期问题 :长周期和短周期共存,轻决策和重决策共存,大部分存在短期、低频的特点;
- 多行业、多场景、多种类、多目标 :我们目前有200多个行业,十几个场景位,推荐种类有帖子、商家、店铺、类目、标签,优化目标有ctr、cvr、call/uv等。

针对类目、行业繁多的问题,我们采用如上图所示的解决方案。具体地,我们会进行分场景、分类型、分类目推荐,即将推荐问题不断进行切分,使得场景更为细粒度。在每一个特殊推荐场景下我们可以制定独特的推荐策略。此外,推荐决策信息需要多元化。特征的来源有用户行为信息,用户长期行为和短期行为,帖子信息和标签信息。用户行为信息有搜索词、浏览信息、点击和筛选。帖子是推荐的重要内容,包含标题文本、类目、标签、图片、帖子质量、评论等。标签信息有标签的来源、所述的类目、类型。多目标决策主要有两个目标:CTR和CVR。
02 58本地服务标签推荐演进
首先介绍一下标签推荐。

标签推荐和一般推荐算法一样分为召回和排序。我们现在使用的是多路召回策略,包括了上下文信息、统计信息、用户长期行为和短期行为。上下文信息由搜索词和用户点击标签组成。根据搜索词和用户的点击标签,我们可以计算它们和标签库中的标签的相关性来做召回。统计信息是指热门点击标签词和热门搜索词。用户长期行为主要包含用户历史点击行为。

召回模型的演进是由简单模型到复杂模型的过程。首先我们使用了基于统计信息的召回策略,即取top点击的标签以及用户的热搜词。随后,我们加入了文本相关性召回,从最简单的词袋模型到考虑权重的tf-idf特征,再演变为使用词向量来计算相关性。最后,我们使用基于用户行为的召回模型,经历了从Bi-lstm到ATRank模型的演进过程。
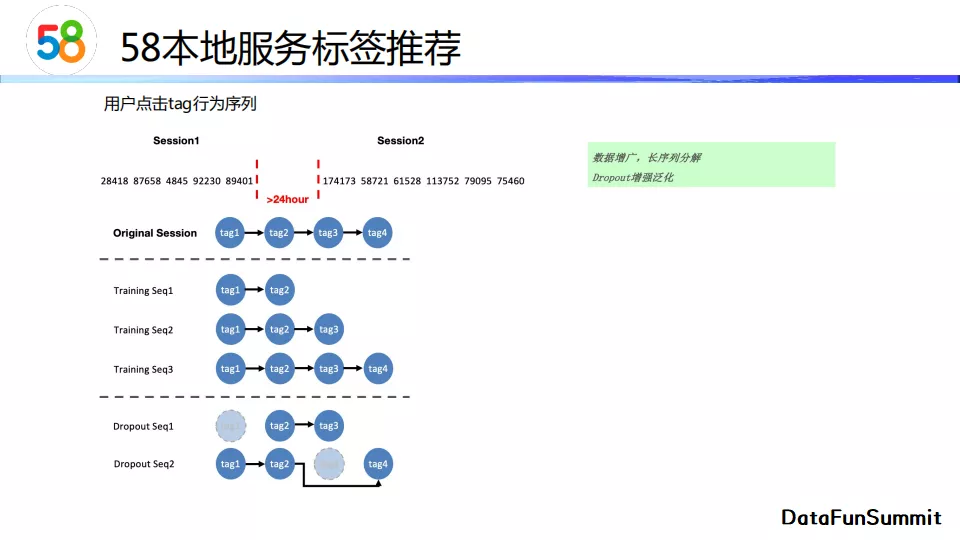
下面介绍基于用户行为的召回模型。我们将用户点击行为以24小时为时间间隔进行切分,如果一个用户在这个间隔内没有交互行为,那么我们可以认为24小时前和后的行为序列属于两个不同session。训练数据就是将session序列对应的标签收集起来。另外,我们会对数据进行增强,例如选取一个序列的子序列作为样本,或者采用dropout的方式去除中间的一些点击标签形成新的样本。
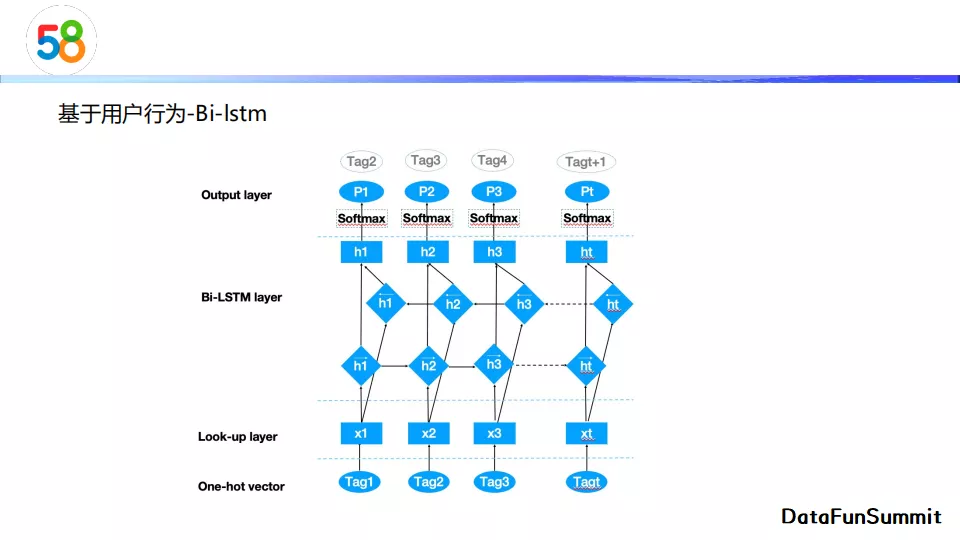
上图展示了Bi-lstm的模型结构,它在输入标签序列的embedding层上加上了双向的lstm层输出隐向量,再通过一个softmax输出层进行标签预测。
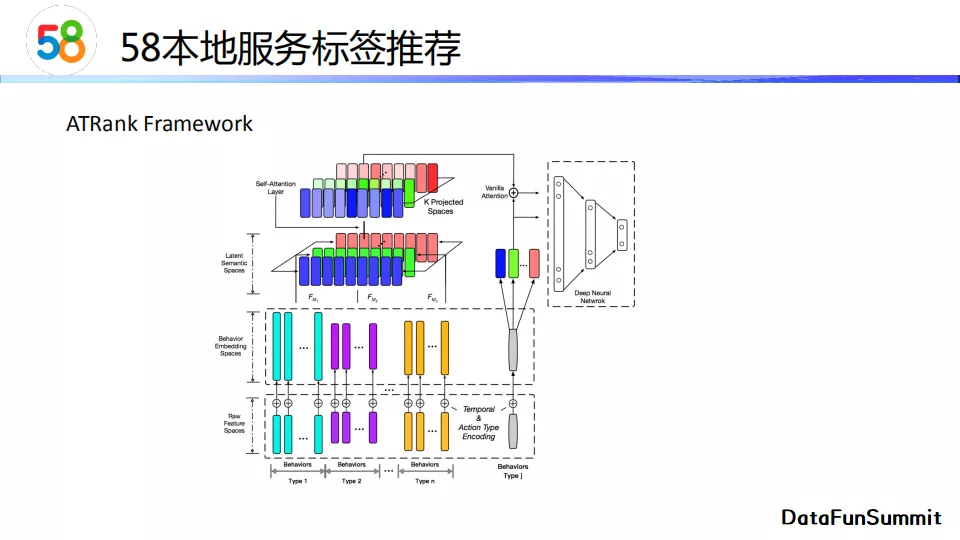
ATRank模型如上图所示。它将用户的行为序列分成多个类型,每个类型单独做embedding。我们的标签推荐场景只考虑了点击这一种行为类型,但是在其他场景,如淘宝做商品推荐时会考虑更多的用户行为(点击、筛选、收藏等)。ATRank的特点是将lstm模型的序列串行关系转换为attention并行计算关系。Embedding向量可以被映射到一个隐式语义空间中,经过一个self-attention模块。之后,模型将得到的隐向量与当前行为隐向量做vanilla attention后,接上一个多层神经网络进行标签预测。
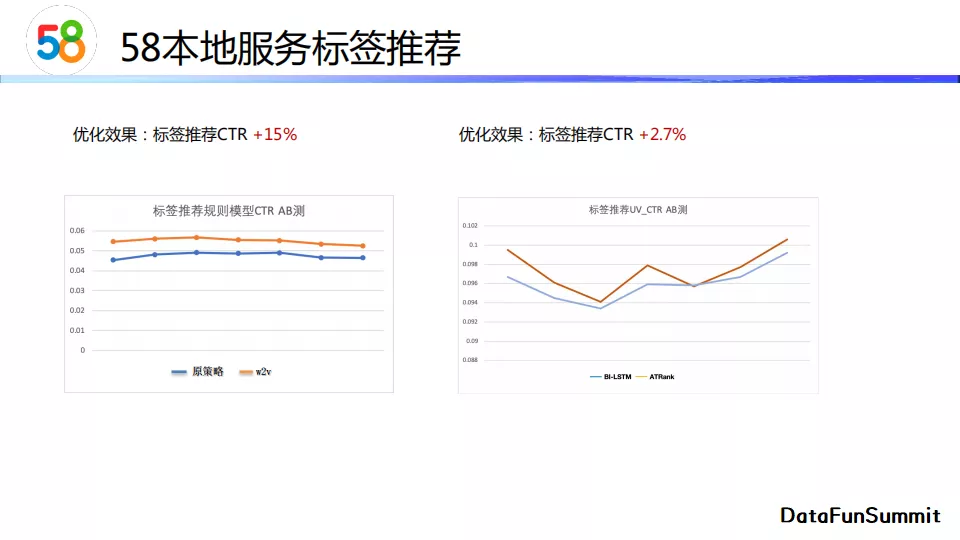
上图展示了升级后的ATRank召回模型的优化效果。原策略指的是词袋模型,即把用户搜索词经过切词后得到的词向量和标签库中的词向量做相关性匹配。我们使用的评价指标是标签词的点击率,目标是观察点击率的提升情况。结果表明优化模型相比原策略有15%的CTR提升。同样的,我们将ATRank与Bi-listm模型进行了对比,发现ATRank相对于Bi-lstm有大约2.7%的提升。
03 58本地服务帖子推荐演进
1. 整体介绍
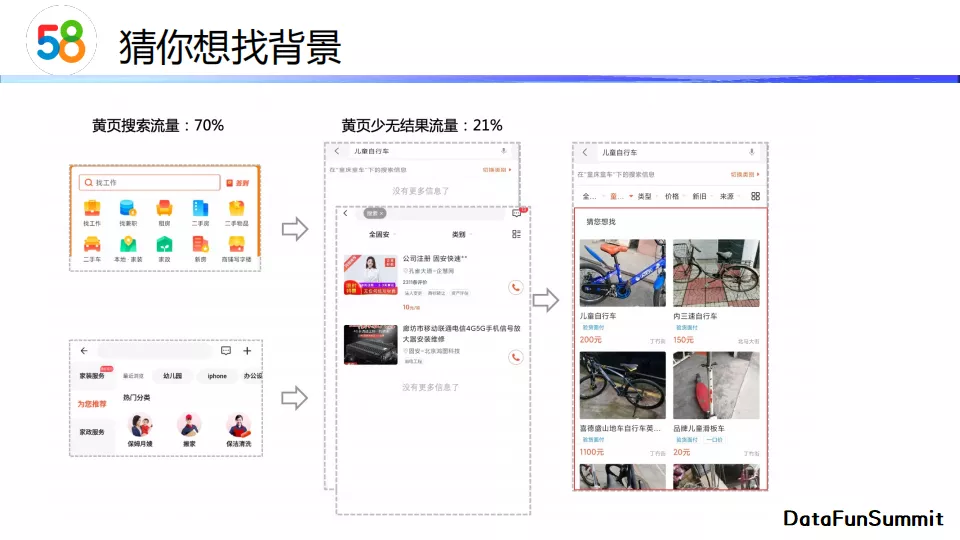
58本地服务帖子推荐的典型场景是列表页的猜你喜欢,这一需求来自黄页搜索。黄页搜索是一个搜索场景,承载了70%的流量,但在一场景下会出现一些搜索词没有结果或者结果比较少的情况。如果搜索结果不能够展示完整的一页的话就认为是“少无结果”,我们在结果下面增加一个“猜你喜欢”模块为用户展示更多内容。
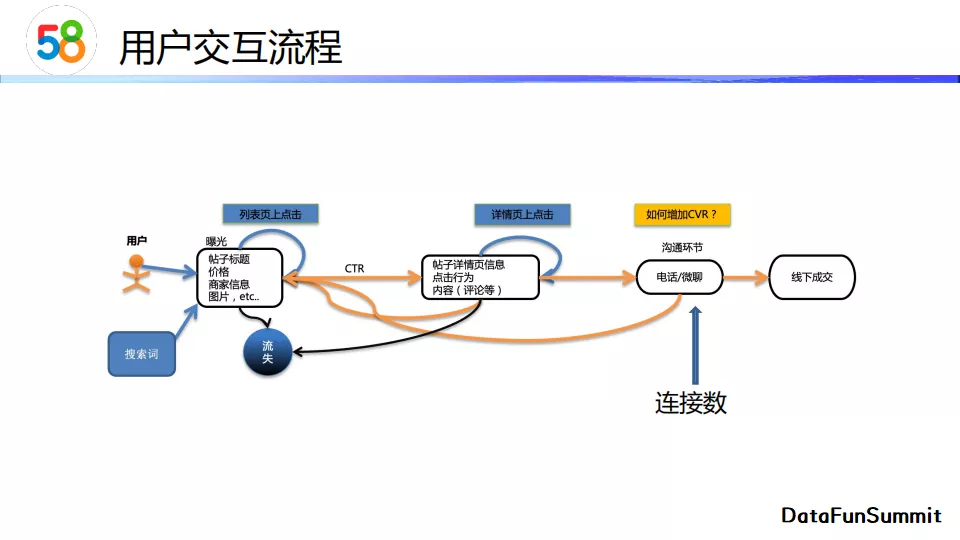
用户的交互流程如上图所示。首先用户输入一个搜索词,系统会曝光召回帖子的标题、价格、商家信息、图片等。如果用户对一些帖子感兴趣的话就会进行点击,进入帖子的详情页。进一步,如果用户对帖子内容有兴趣的话就会通过打电话或者微聊的方式进行沟通。我们的主要目标是提高连接数,即电话的数量,也可以被看作转化率cvr。同时,我们也希望降低搜索结果的少无结果率。
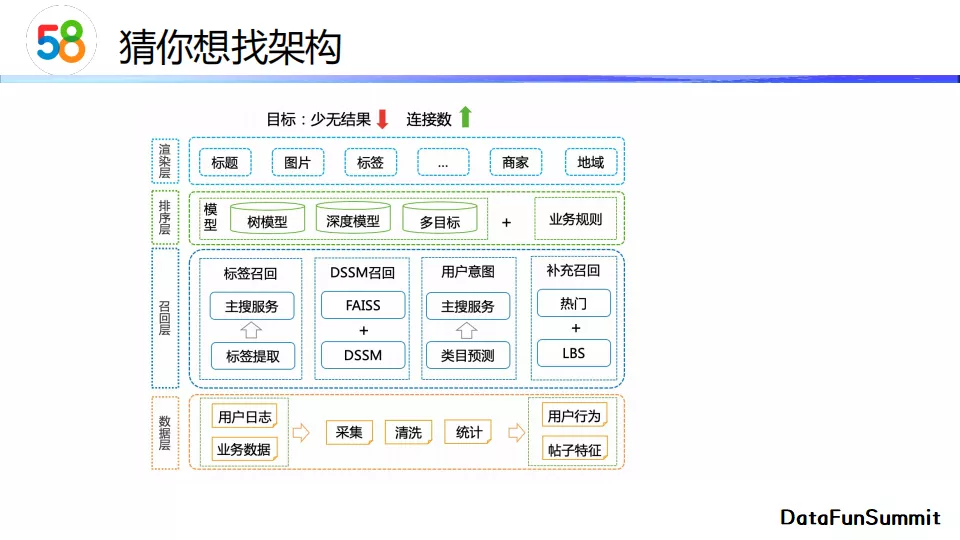
猜你想找架构分为数据层、召回层、排序层和渲染层。
- 数据层 一方面需要获取用户的行为,另一方面需要获取帖子的特征。
- 召回层 采用了多路召回,包含标签召回、向量召回、用户意图召回和补充召回。
- 排序层 经历了从线性模型、树模型、深度模型到多目标的深度模型的迭代过程。与此同时,排序模块会叠加一些业务规则进行约束。
- 渲染层 的作用是决定如何向用户展示排序结果。
2. 召回策略
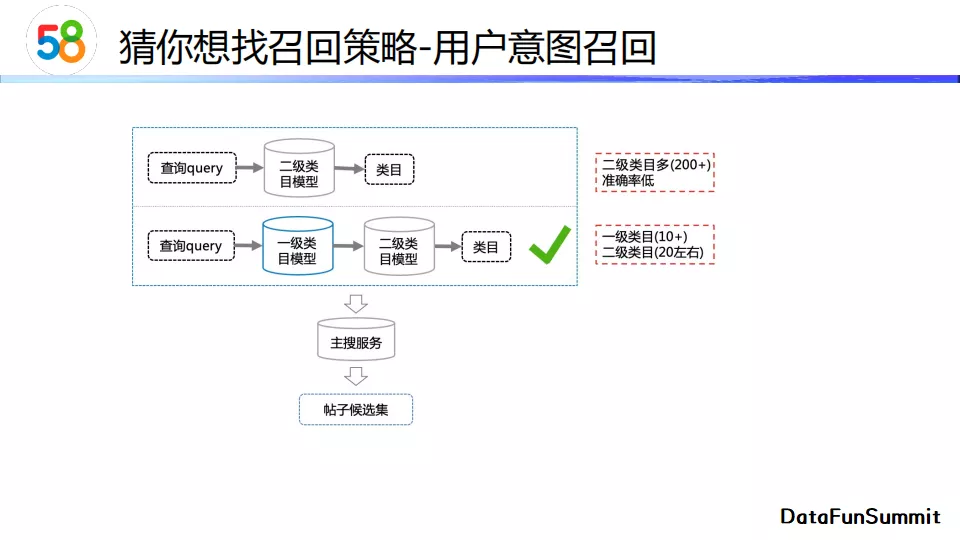
首先介绍 用户意图召回 。用户输入一个查询词后,我们需要对其进行类目预测。我们现在有200多个类目,直接进行分类预测准确率不满足要求,所以我们分成两级进行分类预测。首先我们对query进行一级类目预测,之后再进一步进行二级类目预测。在得到二级类目后,我们再去调用主搜服务来获取这一类目的候选帖子。
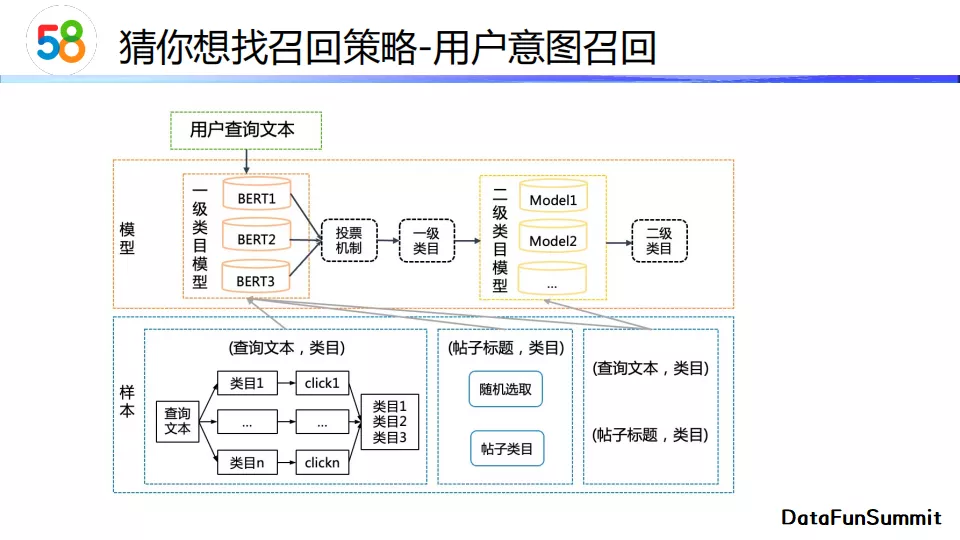
在一级类目和二级类目的预测模型中,我们都采用了bert作为基模型来训练用户的查询文本和类目词的相似度。在离线训练的时候,我们需要搜集大量用户(查询文本,类目)对以及(帖子标签,类目)对。我们还需要打标签来判断这两类数据对是否相关。值得一提的是,在一级、二级类目预测中,我们可以直接使用多分类预测进行建模,例如有十个类目那就建模为十分类问题;也可以将其建模为文本对是否相关的二分类问题。我们在实践中采用了二分类建模方式,它比起多分类的准确率更高。此外,如果后续类目出现变动,多分类预测的训练样本与模型需要很大的改动,而二分类模型对变动的影响较小。
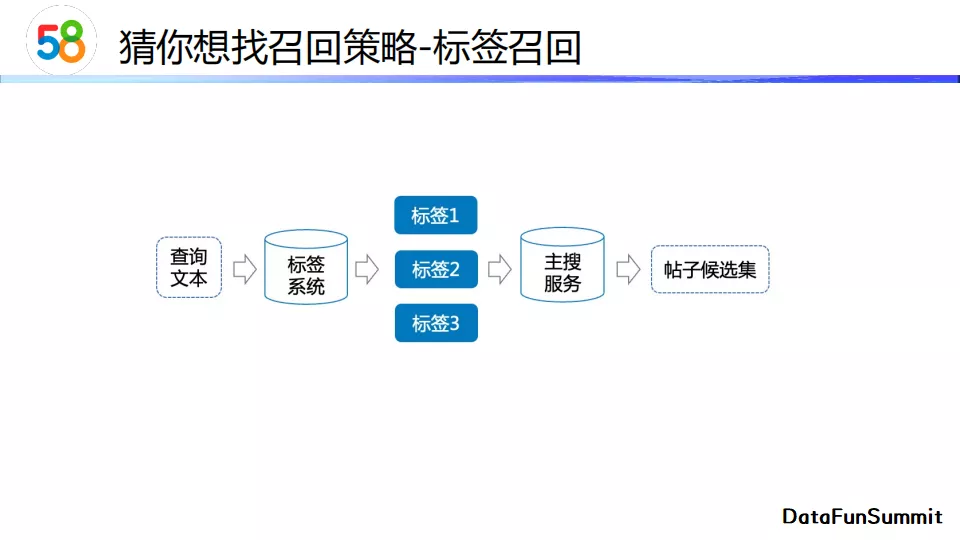
标签召回 中会从标签系统中抽取与查询文本相关的标签,随后再调用主搜服务来获取包含这一些标签的候选帖子。
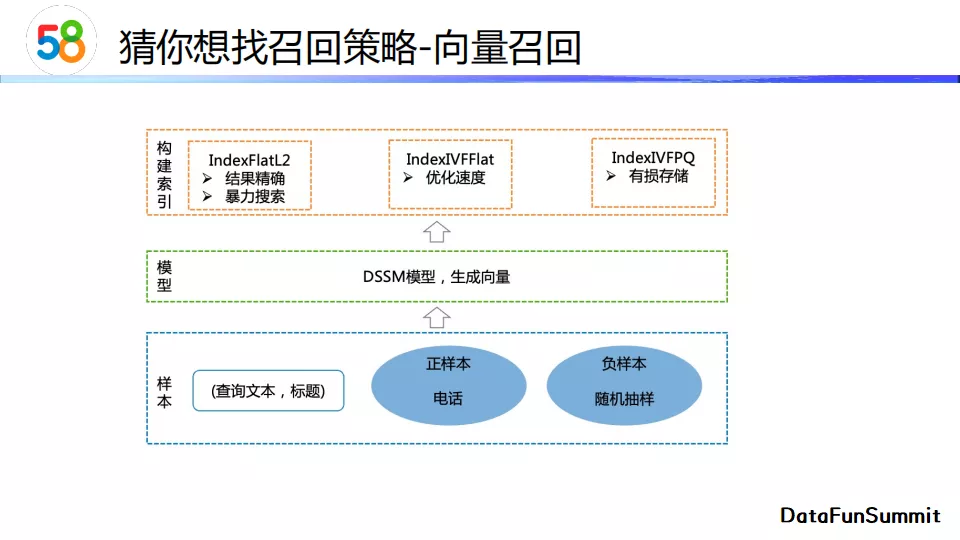
向量召回 使用DSSM模型生成每个帖子的向量和查询词的向量。我们对帖子向量建立索引,其中包含三种方式。第一种是IndexFlatL2,它是一种暴力搜索的方式,其特点是结果最精确,但是查询速度较慢。第二种是IndexIVFlat,它通过计算向量中心点来进行优化,我们在查询时只需要对向量中心点做相似度计算找到最近邻类,再进入这一类中进行召回即可。第三种是IndexIVFPQ,它会对向量进行有损压缩,损失一定的计算精度,但是这一方法的计算速度是最快的,是应对超大规模向量集合的解决方案。
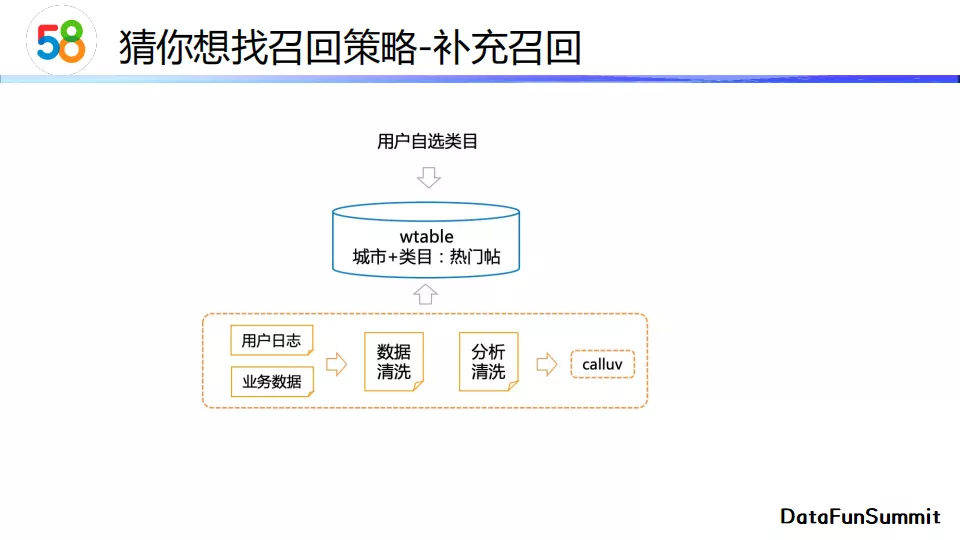
补充召回 通过用户的自选类目进行召回。我们会根据用户所在城市和所选类目召回热门帖子。
3. 排序策略
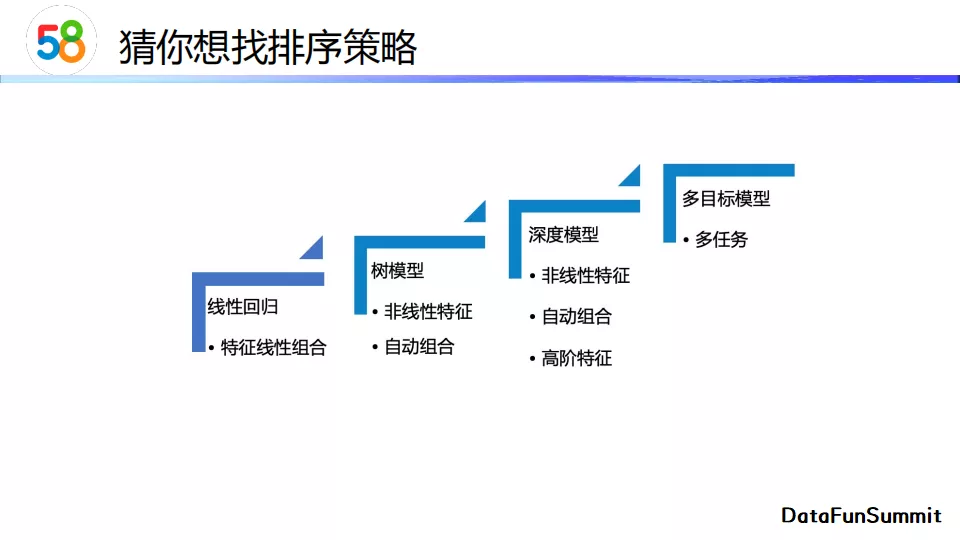
接下来介绍一下猜你想找的排序策略。排序经过了从线性回归、树模型、深度模型到多目标模型的演进过程。树模型相较于线性模型增加了非线性特征,并且可以对特征进行自动组合。深度模型除了加入非线性特征以外还提取了高阶特征。多目标模型通过设定多个相关目标来增强模型的鲁棒性和泛化能力。
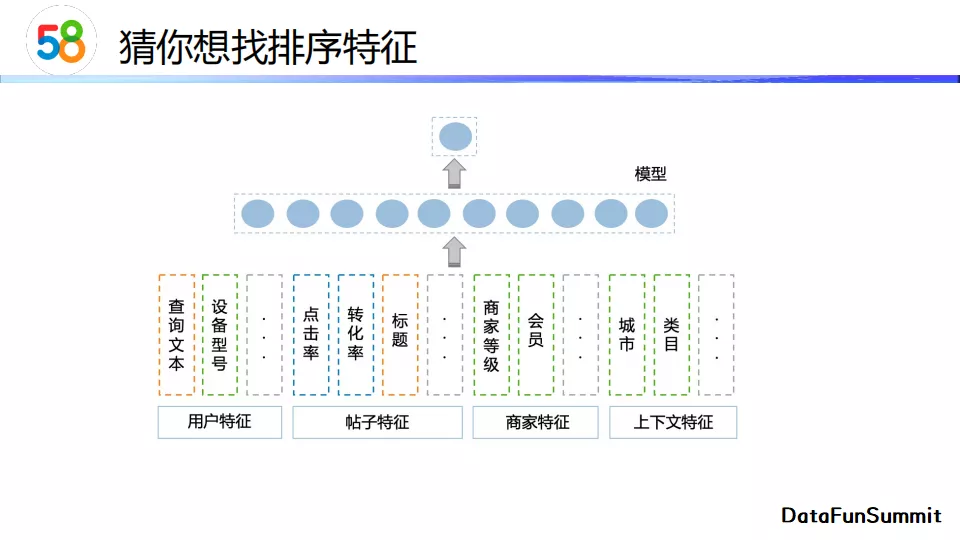
排序特征有:
- 用户特征 :包括查询文本、设备型号等;
- 帖子特征 :包括点击率、转化率、标题等;
- 商家特征 :包括商家等级、是否是会员等;
- 上下文特征 :包括城市、类目等。
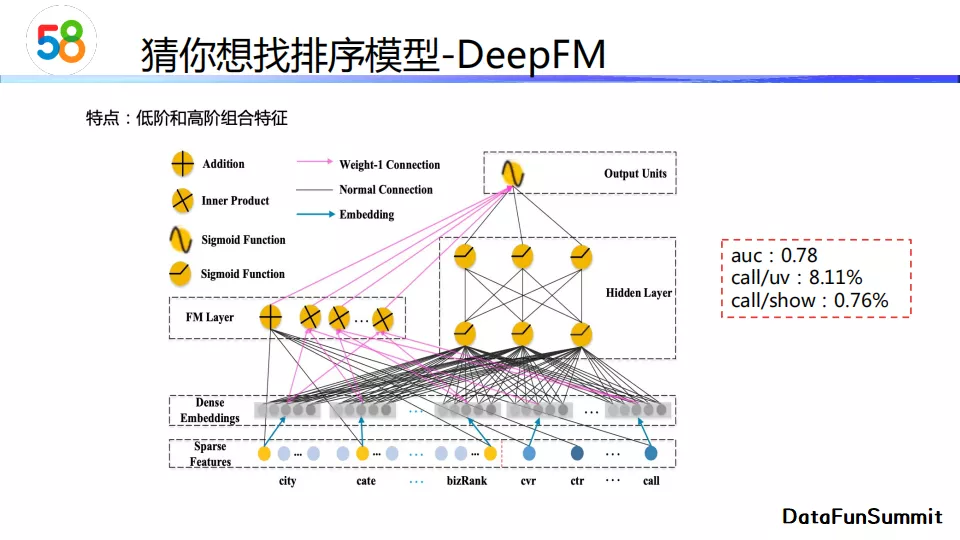
我们这里主要介绍深度排序模型。首先是DeepFM模型。它是将FM和DNN组合起来的一个排序模型。FM主要进行了二阶特征组合,DNN主要用来产生高阶特征,最后这两部分得到的特征向量组合在一起进行预测,得到最终结果。
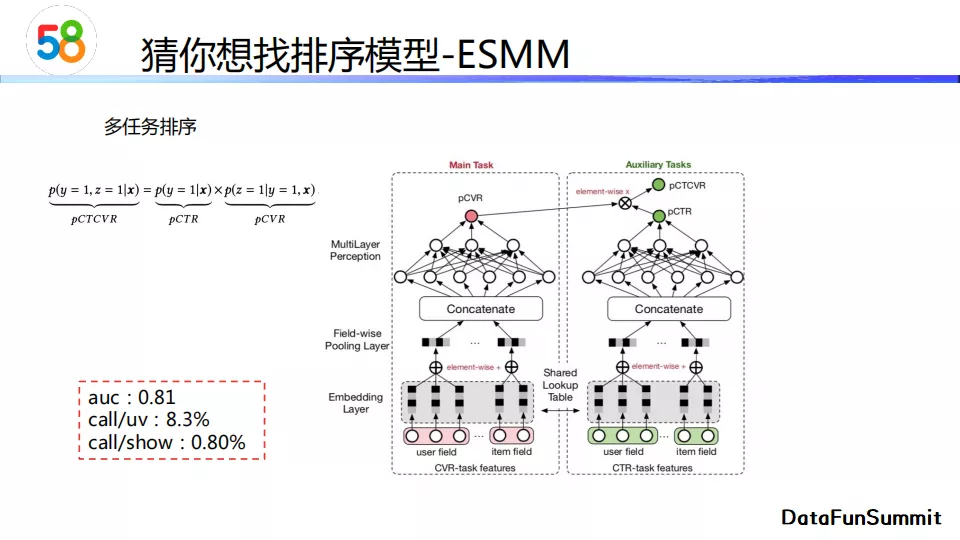
第二个模型是ESMM。它是一个多目标排序模型,我们设定的第一个目标是cvr,第二个目标是ctr。在原论文中,它设置的主要优化目标是cvr,辅助目标是ctcvr(可以分解为点击率乘以转化率)。我们没有直接使用这种方式进行建模,原因是我们考虑的是对任意一个帖子的最终转化率,也就是用户的连接数。
实验表明DeepFM的离线auc指标是0.78,线上call/uv(连接数除以用户访问数)是8.11%,线上call/show(连接数除以曝光帖子数)是0.76%。而使用ESSM这一多目标模型,我们在auc和线上两个指标上都有一定程度的提升。
04 未来展望
最后做一下展望。后面的工作目标是进一步提升推荐的效果,我认为有以下几方面工作可以进行尝试:
- 基础数据的建设 :比如标签系统的准确度提升,因为标签推荐、帖子推荐中需要每个候选帖子都打上相应的标签。此外,我们还需要加入帖子的结构化信息,包括类目、标签等。
- 基础服务能力 :包括分词、同义词、词向量等。
- 深度学习中准确率和效率 :一般来说更复杂的模型效果会更好,但是线上推理对于时间延迟要求较高,复杂模型可能不满足要求。此时我们需要采取一些手段,如模型蒸馏、模型压缩、使用更小的模型、裁剪神经元数目或者网络层数目等。我们还可以借鉴推荐系统相关的前沿算法以及其他领域的算法来对准确率和效率进行更好的平衡。
05 精彩问答
Q:DSSM召回模型的正负样本如何构建?模型是增量更新的吗?DSSM模型两个塔使用的特征分别是什么?
A:正样本来源于查询后点击的帖子是否被转化,即出现“打电话”的行为,此时查询文本和帖子标题可以构成一个正样本。负样本则是随机抽取的。因为召回阶段和排序阶段不同,我们只关注查询文本和帖子标题是否相关即可。DSSM的查询文本和标题文本都属于短文本,我们首先会对它们进行分词和embedding映射,随后连接的神经网络可以选择dnn、cnn或者lstm。如果使用的是lstm模型,那么可以使用最后输出的隐向量或者所有隐向量的和作为最终的文本向量表示。每次训练所用的样本数据是从最近三个月的用户行为日志中收集,每周自动训练并更新一次模型。
Q:点击率特征是如何做归一化的?
A:一般来说点击率是一个特别小的数字,绝大部分在小于0.1的范围内。这里有很多归一化的方式。我的做法是根据数据分布来设定一个经验值,比如统计发现90%的点击率都小于0.1,那么可以将大于0.1的点击率都设为1,小于0.1的点击率都除以0.1,使得其数值范围能相对均匀的分布在[0,1]内,避免出现极端分布。
Q:多个应用场景下是使用同一个模型的吗?
A:在不同的场景下,我们的模型会有所差别。比如在猜你喜欢的场景下我们使用了DeepFM和ESMM模型,但是在类目推荐中我们不使用这么复杂的模型。因为类目推荐通常以热门类目为主,用户个人兴趣和偏好是作为辅助特征来加入模型的。所以在每个场景下选取的模型区别还是比较大的。
Q:如何评估生成的词向量?词向量如何应用至召回和排序模块?
A:我们主要采用人工的方式来进行向量评估。具体地,我们会构建一些常用搜索词,通过观察模型生成的词向量召回的一系列相关词来判断相关性是否满足要求。在召回阶段,我们会使用词向量将与query语义相似的帖子标题通过计算词向量相关度来进行召回。在排序阶段,我们会将召回阶段计算的相关度作为一个特征加入,相较于召回阶段每一路考虑的特征较少,排序阶段会把所有特征都考虑进来。
Q:标签系统是如何构建的?
A:标签分为行业标签和通用标签。对于行业标签,我们可以从帖子标题中抽取代表行业信息或者行业类目信息的特征词。具体地,我们会将帖子标题进行分词,然后从生成的词序列中抽取关键词。关键词还需要经过进一步的筛选来得到行业相关的词进入标签词库。这个过程需要人工参与。通用标签数目较少,可以人工总结。
Q:query搜索中一级类目搜索和二级类目搜索是怎么实现的?
A:对于�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E5%88%98%E5%BE%B7%E5%8D%8E%E6%A0%87%E7%AD%BE%E6%8E%A8%E8%8D%90%E4%B8%8E%E7%8C%9C%E4%BD%A0%E6%83%B3%E6%89%BE%E7%AE%97%E6%B3%95%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


