同义变换在百度搜索广告中的应用

分享嘉宾:连义江博士@百度
编辑整理:王成林
出品平台:DataFunTalk
导读: 关键词匹配位于整个搜索广告系统的上游,负责将query和keyword按照广告主要求的匹配模式连接起来。该问题面临着语义鸿沟,匹配模式判定和可扩展性方面的挑战。在本文,我们会就同义变换这个主题展开讨论,讲述如何用数据驱动的方式做同义变换,如何将知识推理融入到变换中,以及如何用这些技术解决匹配问题中的核心挑战。
01 背景介绍
1. 搜索广告
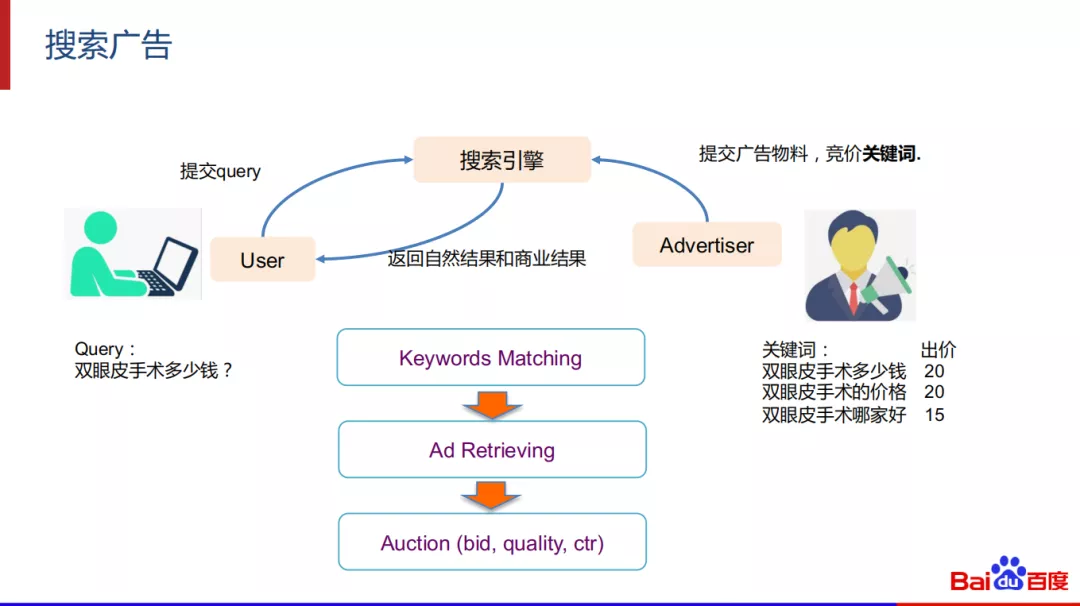
搜索广告中有三个角色,分别是用户、广告主、搜索引擎。
- 广告主侧会向引擎提供物料,同时竞价关键词。比如一个做双眼皮的美容机构,会买例如“双眼皮手术多少钱”、“双眼皮手术的价格”、“双眼皮手术哪家好”等关键词。这些关键词会被提交到搜索引擎。需要指出的是,这里说的关键词不是我们通常所说的关键词,而是指广告主购买的query。
- 用户侧会提交query,比如“双眼皮手术多少钱?”。
- 搜索引擎在收到query之后,会对query和关键词进行匹配,把广告主的广告创意拉取出来,综合考虑 ( bid, quality, ctr ) 等因素选取有限的广告进行下一轮的拍卖,最终胜出的广告会被展示出来。
2. 广告主的竞价语言:匹配模式
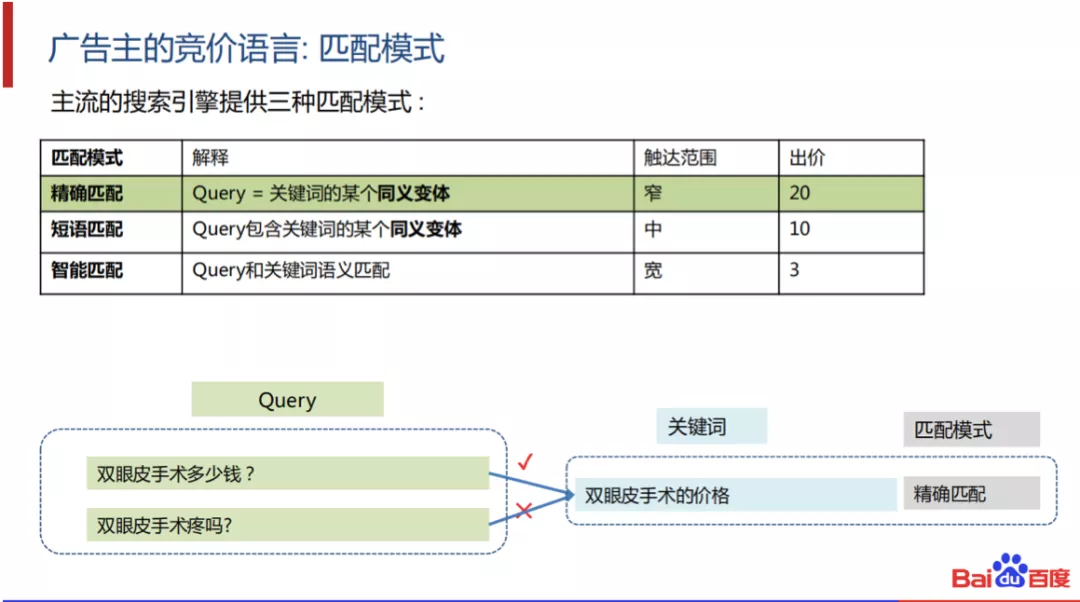
和其他广告不一样的是,搜索广告会提供特定的竞价语言,即匹配模式。广告主可以控制这些关键词对应的匹配模式来控制竞价的精准度。主流的搜索引擎一般提供三种匹配模式:精确匹配、短语匹配和智能匹配;其定义如图所示。一般的,这三种匹配模式,从上到下,触达范围由窄到宽,精准度也从高到底,相应的,出价也会从高到低。
举一个例子,如果广告主购买的关键词是“双眼皮手术的价格”,并且指定其匹配模式是精确匹配的话,当query是“双眼皮手术多少钱?”时,广告主的关键词会被匹配到,而“双眼皮手术疼吗”则不会被匹配到。
3. 广告主的账户结构
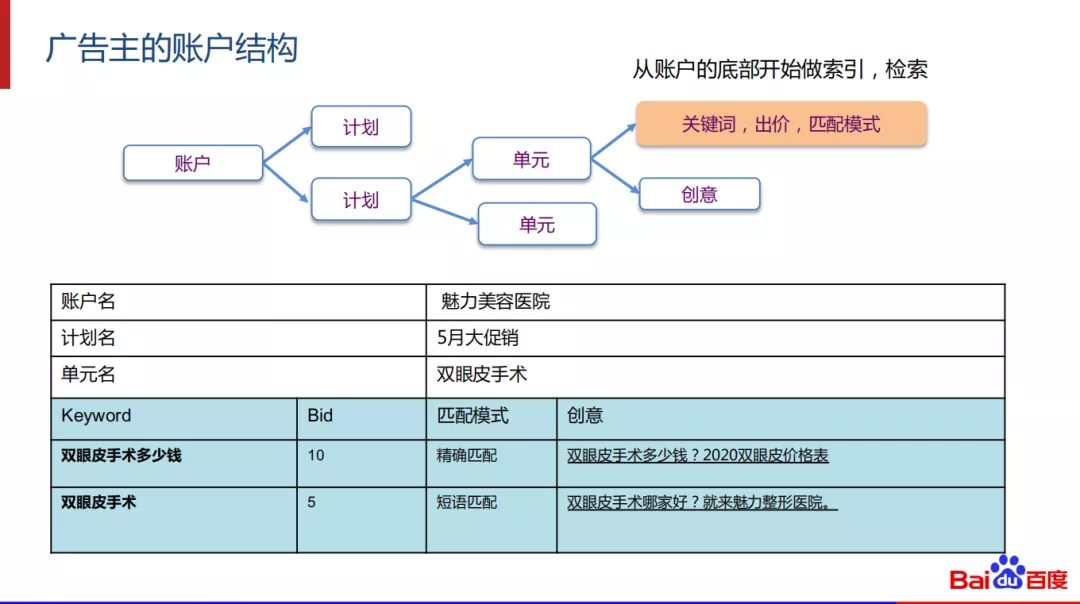
再举广告主的账户结构的例子给大家看一下,广告主会投放若干计划,在计划下有多个投放单元,在投放单元中,有关键词、出价和匹配模式,在单元下广告主会提交若干创意。可以看到关键词是处于整个树形账户结构的底部, 我们匹配的工作会从这个账户底部开始进行,包括索引和匹配。
4. 搜索广告系统概览
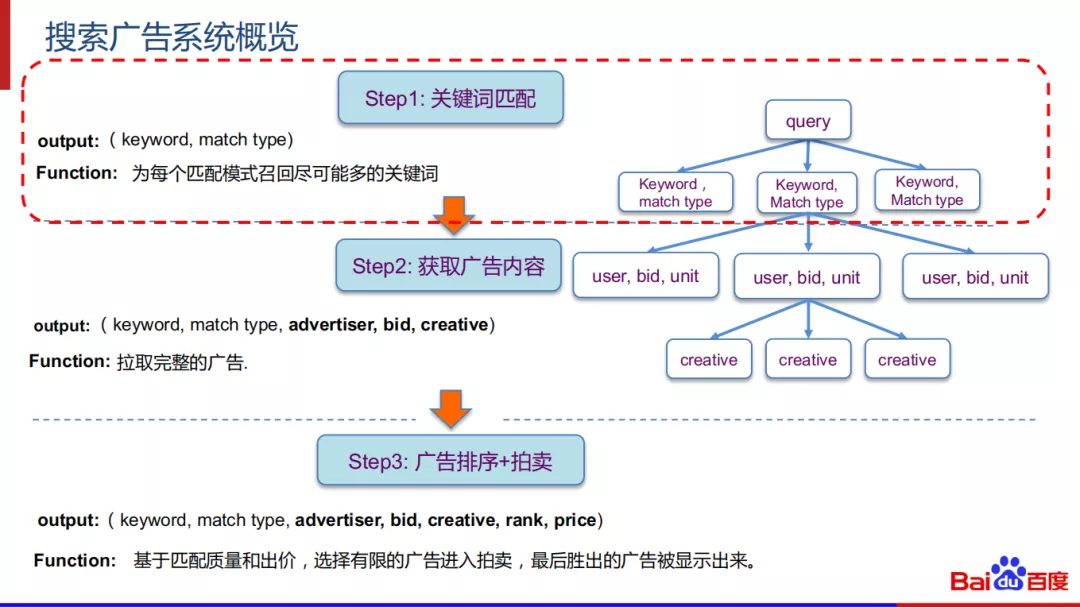
在搜索广告系统中,广告的触发分三步走:
- 第一步是进行“关键词匹配”,目标是为每个匹配模式召回尽可能多的关键词。
- 第二步是在关键词匹配成功后获取广告内容,确定广告对应的广告主、出价和广告创意。
- 第三步是广告排序阶段,基于匹配质量,出价和点击率等因素,选择有限的广告进入拍卖,最后胜出的广告被展现出来。
5. 关键词匹配问题
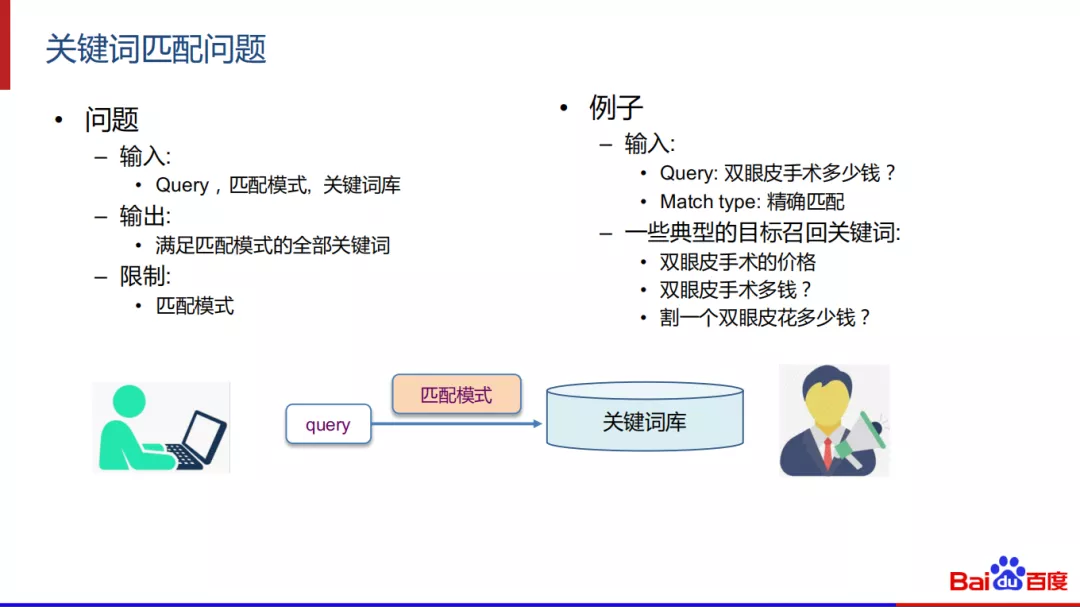
本次分享的重点是“关键词匹配问题”,抽象来说,这个问题的输入是query、匹配模式、关键词库,输出是满足匹配模式的全部关键词,限制是匹配模式。例如输入是“双眼皮手术多少钱”,在精确匹配模式下,产生的典型目标召回关键词是“双眼皮手术的价格”、“双眼皮手术多少钱”、“割一个双眼皮花多少钱”等。
6. 问题挑战

关键词匹配问题的挑战有:
**Semantic Gap:**用户和广告主用不同的方式来表达同样的意图。例如“双眼皮手术的价格”和“双眼皮手术多钱?”是同一个意思,但是他们会用不同的字面来表达。这也是NLP中一个基础又很重要的问题。
**匹配模式的判定:**是搜索引擎广告面临的独特问题,用来判定是精确、短语还是智能匹配。这是产品的根基,由产品对广告主的契约保障。
**工程性能:**可扩展性,由于query和关键词的量都非常大, 无论在线还是离线,计算资源都非常有限,这给很多功能实现带来了挑战。
02 同义变换的应用场景
同义变换的应用场景主要有:
1. 同义匹配

首先是产品定义的同义匹配问题,在刚刚提到的三个匹配模式中精确匹配和短语匹配与其是直接相关的。一般情况下,一个query可以有无数个同义变体。例如一个query是“双眼皮手术多少钱”,简单的变体是“双眼皮手术多少钱呢?”,一个更为复杂的变体是“拉一个双眼皮大概需要多钱?”。如果在一个开放域中变换的话,一个query可能有无穷无尽种同义的变体,而我们主要关心的是在封闭集合上的变换能力,即将query同义变换为bidword集合中的某一个。
2. Keyword端
队列压缩:
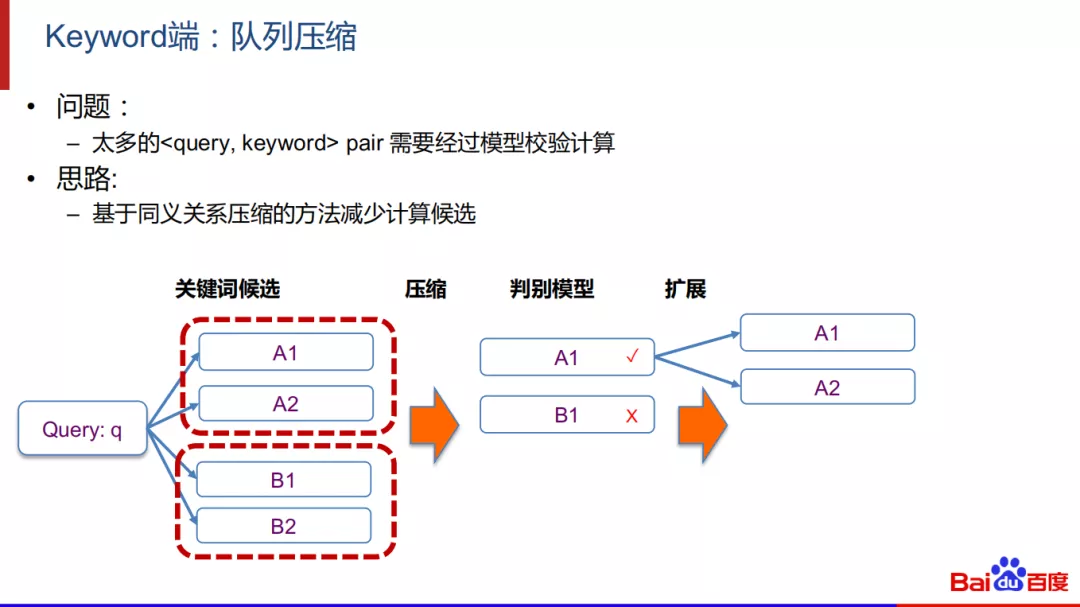
另外一个应用场景是在Keyword端,在关键词匹配中,给定一个query,我们通常会触发得到大量的候选关键词,这些候选为了保证质量,都需要经过模型校验计算来确认。我们的思路是基于同义关系压缩的方法减少计算候选。在上图的例子中,一个query触发4个关键词候选,通过离线计算A1和A2是同义,B1和B2是同义,那么线上只需要校验A1和B2,当A1通过校验后再扩展回去。这样可以极大地减少判别模型的计算压力。
基于代表元来触发:
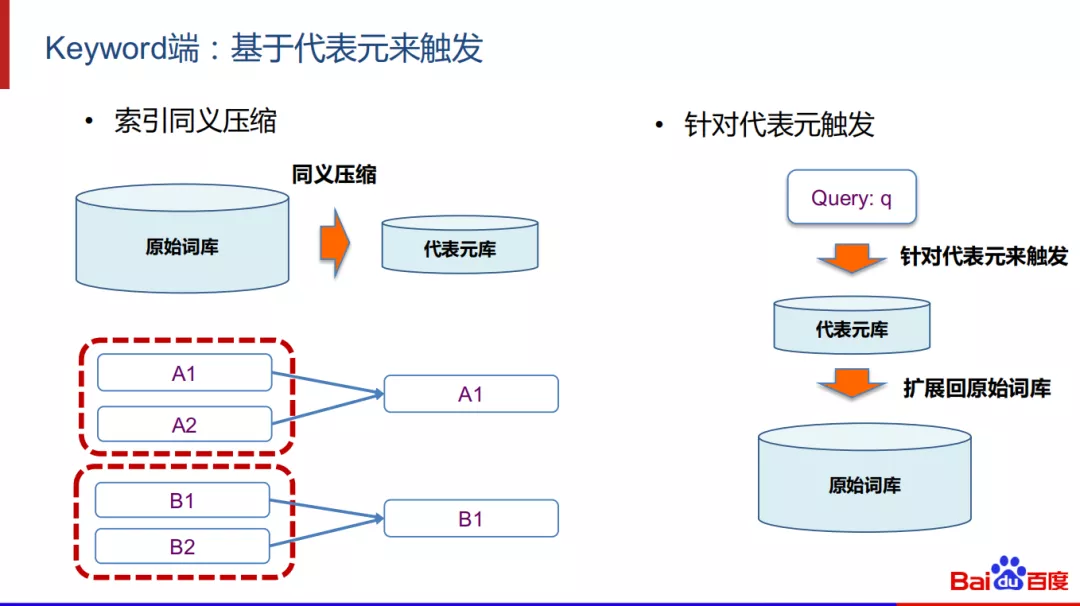
更为激进一点,我们可以用基于代表元来触发。通过对原始词库进行同义压缩,例如对A1,A2和B1,B2进行同义压缩成A1和B1,可以降低keyword端的量,只需针对A1和B1进行触发。在线上使用中,我们采用基于代表元来触发,然后再扩展回原始词库。
3. Query端:规范化+改写
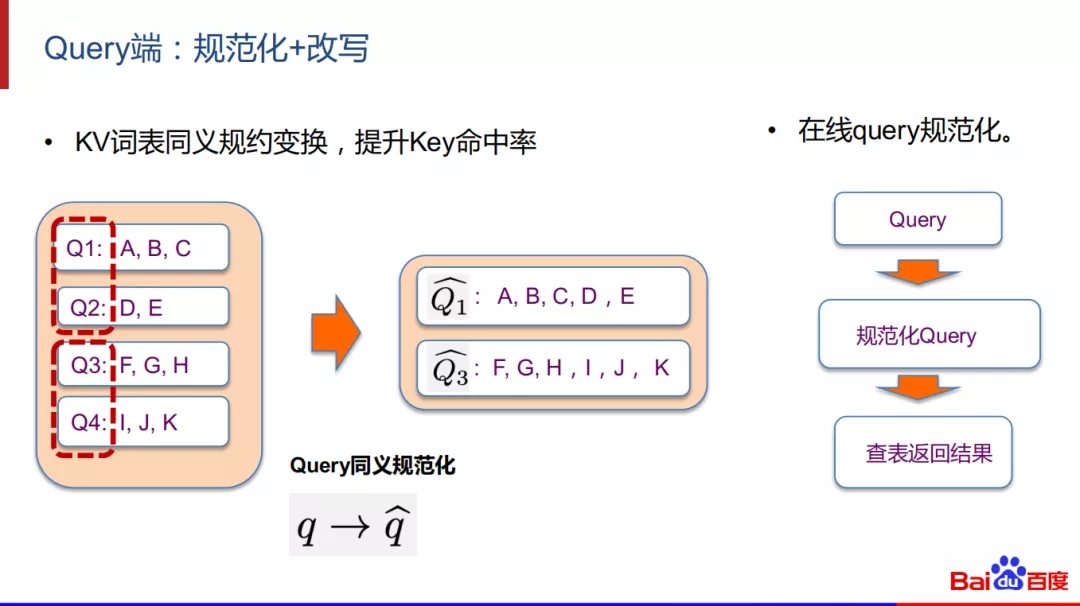
在query端,我们可以进行规范化和改写。一般的搜索广告都会针对高频query做离线的充分计算放到一个高频词表。当query来了之后,先去查表来看是否有结果命中。我们可以针对高频KV词表中的key做同义规约变换,从而提升key的命中率。KV词表中,K就是关键词,V就是触发的结果。例如Q1原来的触发结果是A、B、C;Q2的触发结果是D和E,在同义规约后,Q1和Q2的触发结果是A,B,C,D,E。相对于原来Q1只命中A,B,C而言,规约之后提升了命中率,同时整个词表只需存储规约Q^1和Q^3来减少key的量级。
03 如何做同义匹配?
—— 以精确匹配场景为例 ——
同义匹配的方案:
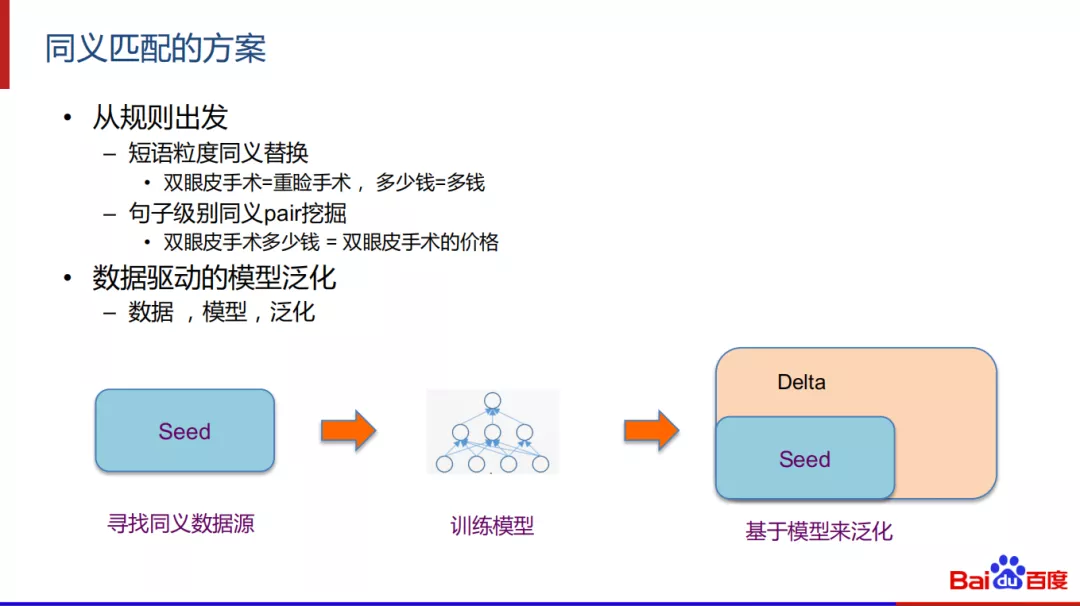
在同义匹配中,以精确匹配场景为例,首先可以从规则出发,进行短语粒度的同义替 ( 例如双眼皮=重睑手术,多少钱=多钱 ) 或者进行句子级别的pair挖掘。今天分享的主要内容是通过数据驱动的模型来提高泛化。主要为三步走:寻找同义数据源、训练模型并基于模型来泛化。
第一步:寻找大型同义数据源

在如何选择大型同义数据源方面,一方面可以利用系统外部数据,例如搜索点击日志、Session日志、协同过滤和规则替换。另一方面可以使用系统内部数据,例如商业点击日志。
① 数据选择的困惑:
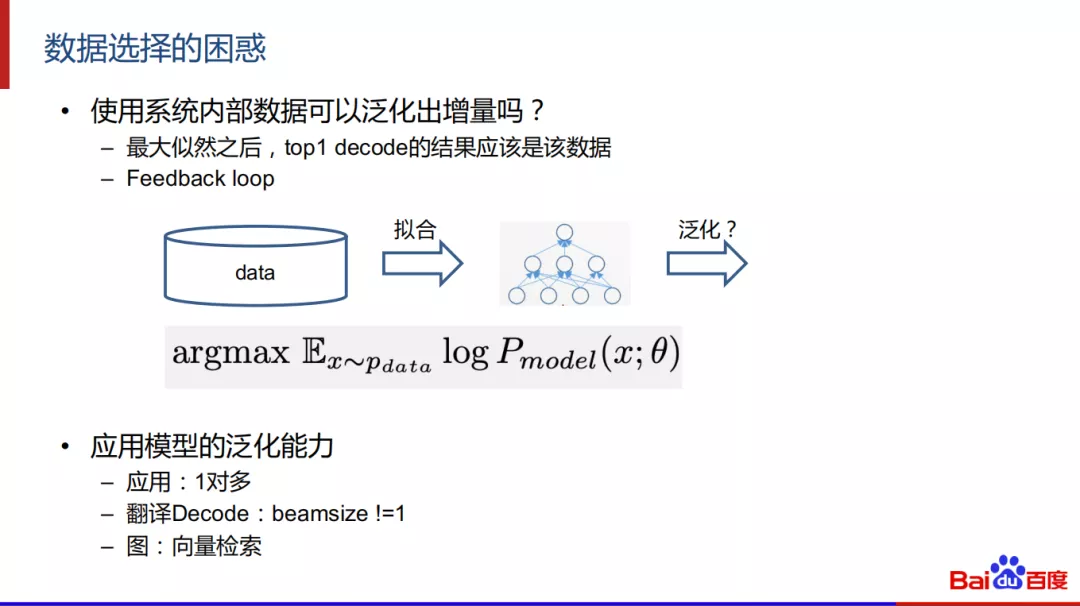
在数据选择方面会产生一些困惑,使用系统内部数据可以泛化出增量吗?因为使用最大似然的方式求解就是使用模型来拟合数据,例如使用翻译模型或者图模型,top1 decode的结果就是该数据,这个过程好像无法产生增量数据,会陷入feedback loop中。事实上可以使用系统内部数据也可以泛化出增量,因为我们实际应用中是做1对多的decode,在图模型中我们会近邻检索出不止一个候选。下面举例来说明泛化带来的delta。
② 泛化带来的delta:
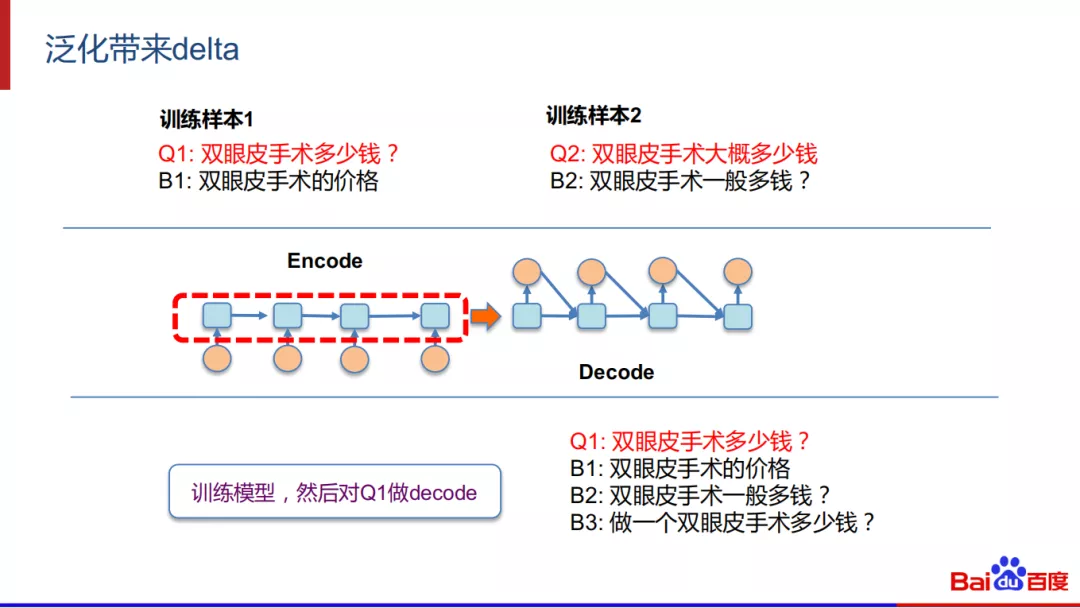
在上图中,训练样本1的Q1是“双眼皮手术多少钱?”,B1是“双眼皮手术的价格”。训练样本2的Q2是“双眼皮手术大概多少钱”,B2是“双眼皮手术一般多钱?”。使用S2S模型来对样本进行训练,然后对Q1做Decode,由于Q1、B1是在训练样本1中,所以首先能够得出B1,同时由于Q1和Q2相似度比较高,所以也能够获取结果B2,如果模型的泛化能力足够强的话,说不定能得出B3。
第二步:训练模型
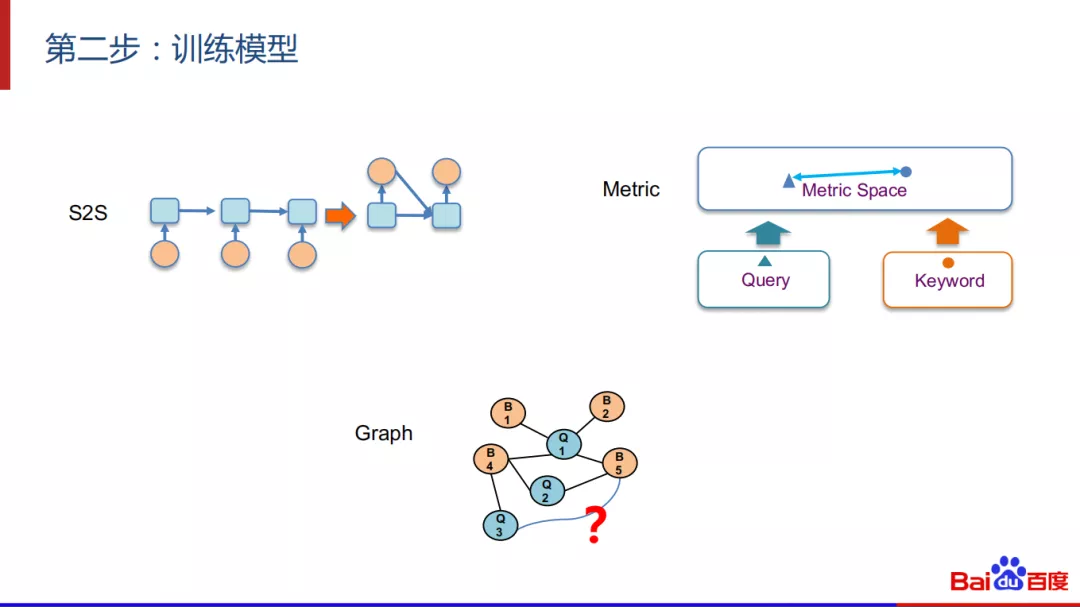
在训练模型中可以选择S2S模型,双塔模型 ( 即语义的度量模型 ),或者图模型。
第三步:基于模型来泛化召回
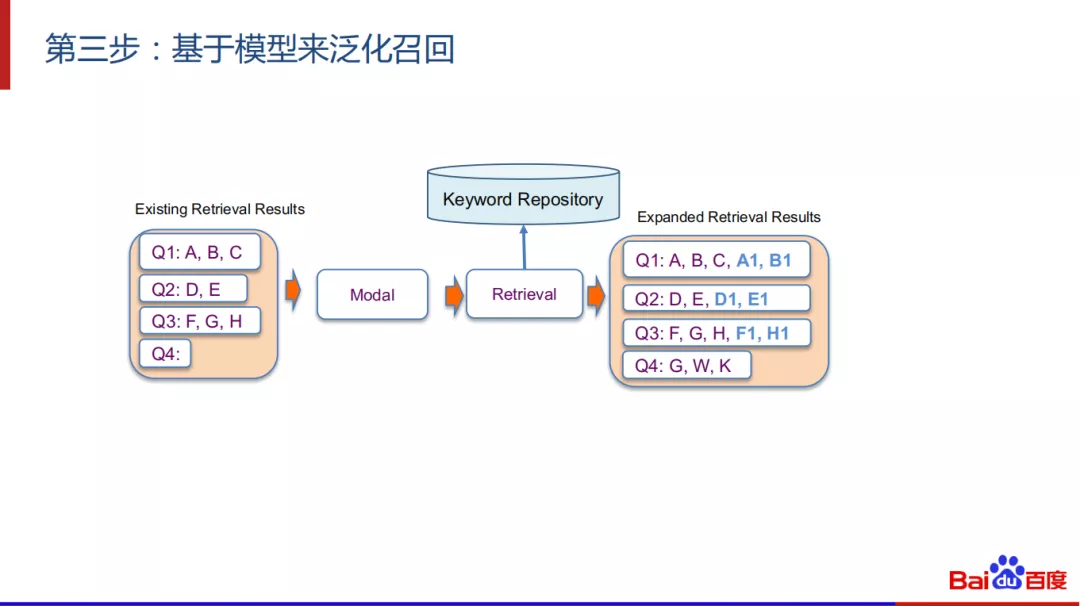
最后是基于模型来泛化召回,使用模型的自反馈来进行泛化,以前Q1有3个召回的结果A,B,C。基于模型,定向在关键词库中做召回,有可能把A1和B1也召回出来。图中的蓝色标记都是泛化出来的结果。
04 基于S2S来泛化
1. 思路
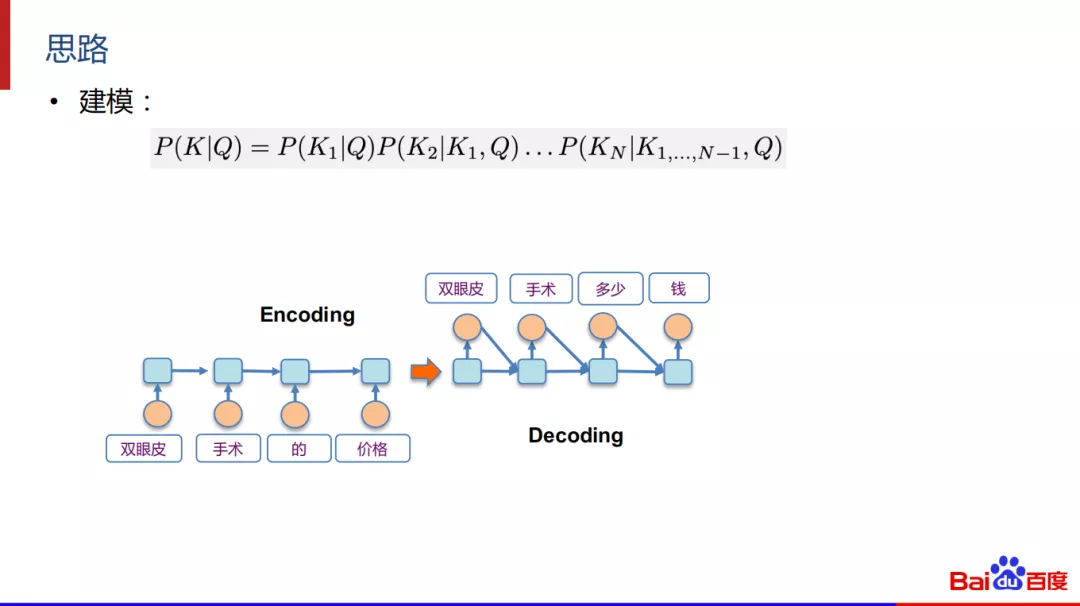
基于S2S的泛化,建模本质就是一个翻译模型,进行逐词翻译,对Query进行编码使用embedding来作为输入。
2. 该建模的优缺点

该建模的优缺点:
优点:
- 采用端到端的建模,尤其是在语料充分的情况下,质量会非常好,同时简单,只需要获得一些正例即可。
缺点:
- 效率比较低,因为是用翻译的方式来做检索的工作,逐词生成。一个query通常有上千种同义变体的关键词,纯靠decode几乎不可能完成。同时如果数据不作清洗的话,冗余度会非常高。
- 定向翻译,因为翻译本身是开放式的,不能保证decode出来的东西都是关键词。
- 训练和预测是不一致的,训练时一对一,目标是一对多。
3. 解决效率问题:同义规约
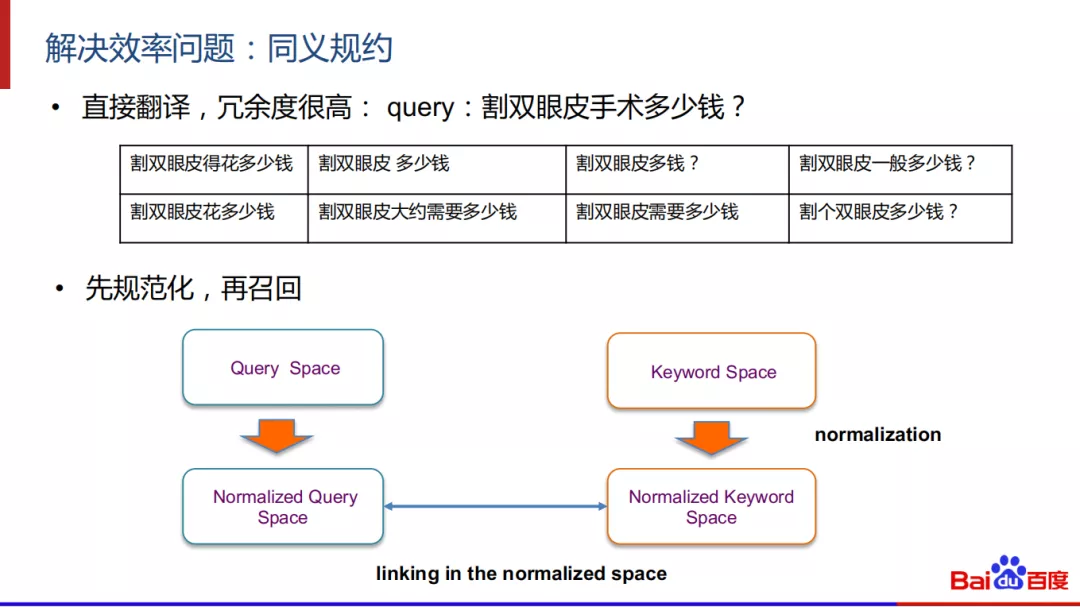
解决效率问题,可以使用同义规约的方式来解决,直接翻译的话,冗余度是很高,如果query是“割双眼皮手术多少钱”,类似的query有很多,例如多一些空格,少一些空格,多一个标点符号,多些副词,感叹词等。所以我们可以对Query和Keyword空间,先都进行归一化, 然后在规范化的空间中来做匹配。
4. 如何做规范化
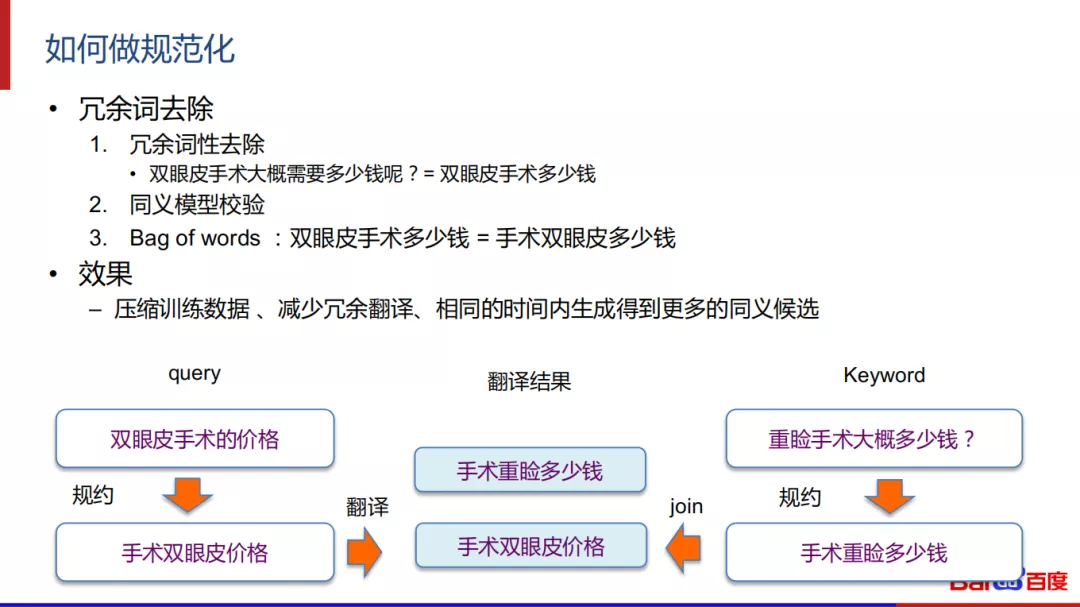
具体进行规范化的步骤是,基于冗余词性的去除。例如副词、标点符号的处理;还可以采用同义模型来进行校验;更进一步的是做bag of words的处理。其效果是可以极大的压缩训练数据、减少冗余翻译、相同的时间内生成更多的同义候选。
5. 解决效率问题:同义扩展
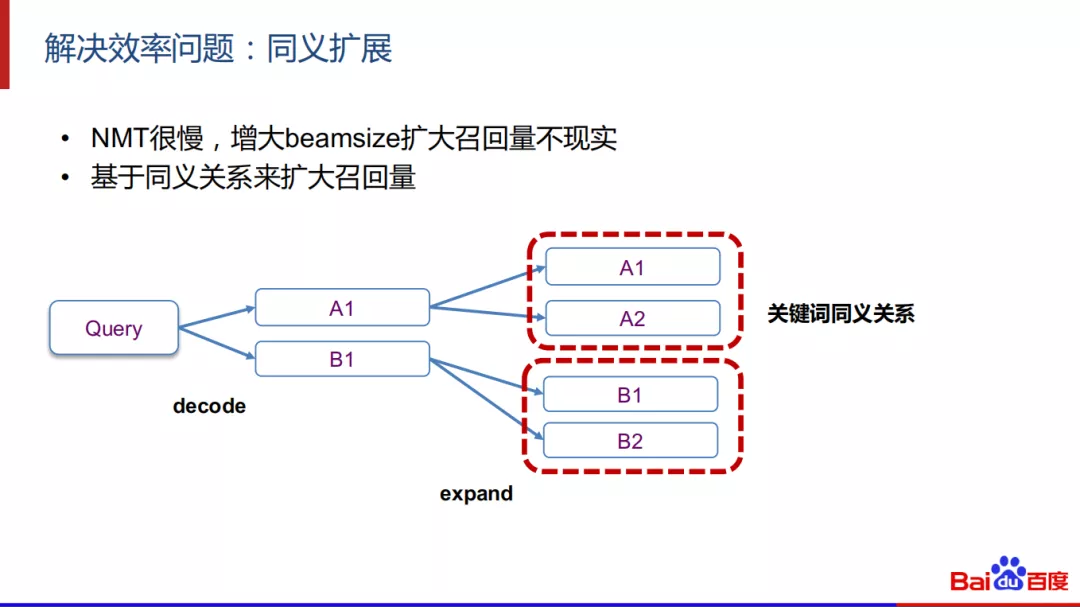
还需要解决的一个问题是同义扩展,因为NMT很慢,增大beamsize来扩大召回量是不现实的。可以采用基于同义关系来扩大召回量。
6. 更好的泛化:基于概念来泛化

我们知道,数据驱动有自己的硬伤:那就没有数据就驱动不了。我们的模型最后往往只学到了数据上的共现,却缺乏概念抽象的推理功能。例如对于样本“北京双眼皮手术的价格=在北京做个双眼皮手术大概多少钱?”直接训练DNN模型,我们很难泛化出这样的case:乌鲁木齐修眉的价格=在乌市做个修眉大概多少钱?。而我们希望模型是有一定的能力来抽象知识并做推理泛化的。
一些解决的思路:
解决的思路有UNK问题,使用copyNet和pointerNet。还可以做一些概念实体识别的事情如下图所示:
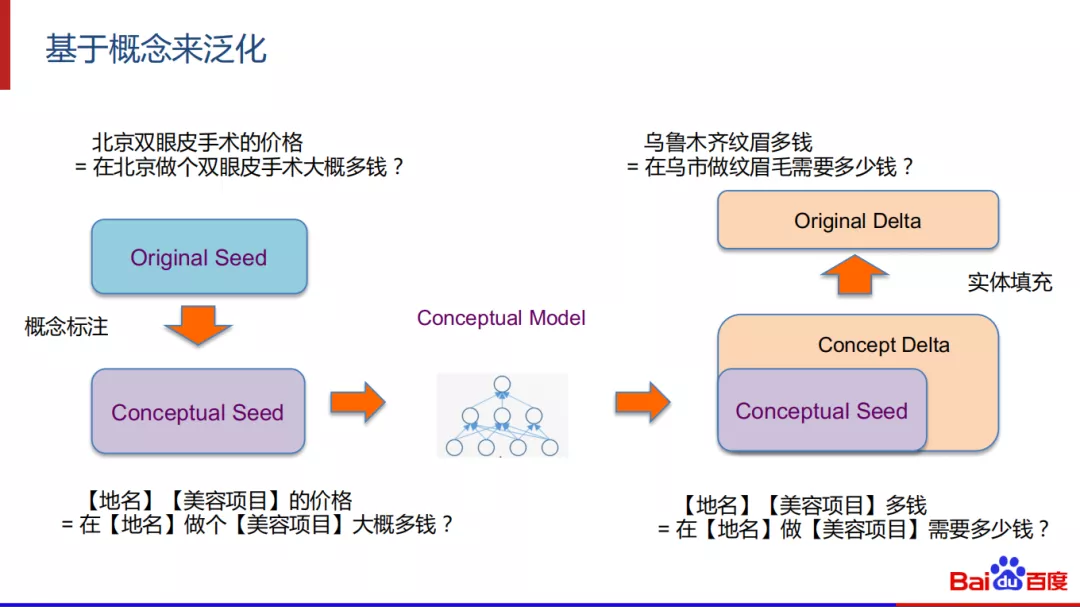
我们首先把原始的数据先转换到概念空间中去,然后在概念空间中做泛化,然后对泛化后的概念模板填充实体,得到最后的召回结果。
具体流程:
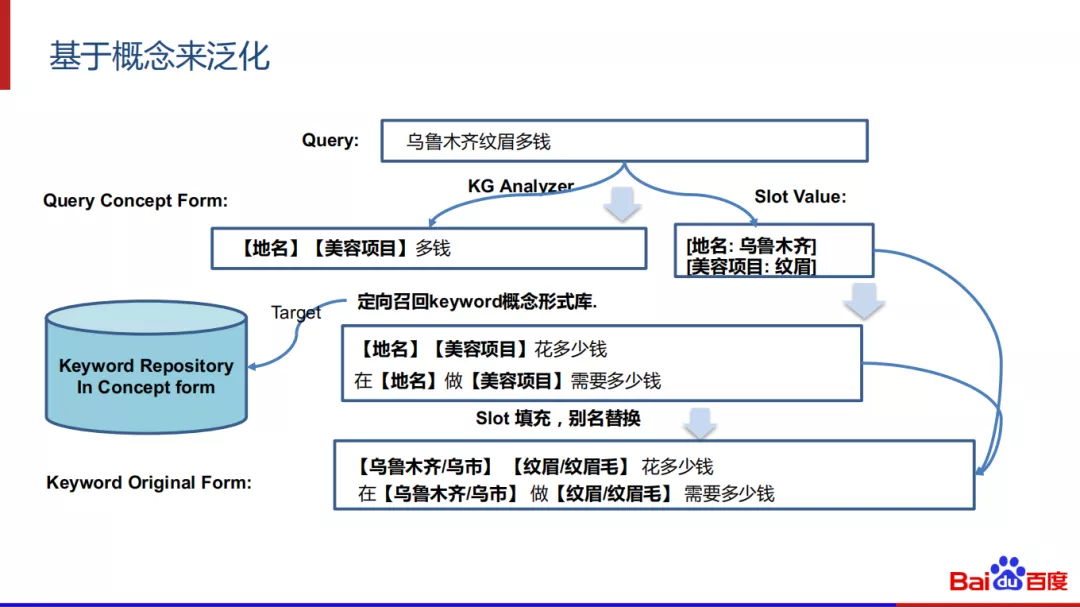
在线上一个query来了之后,我们先对query做标注,然后得到这个query的概念形式,和概念对应的填充值,然后我们定向对keyword概念库来召回同义的概念形式,最后填充概念值得到最后的结果。比如query是“乌鲁木齐纹眉多钱”,可以分析得到对应的概念形式是“【地名】【美容项目】多钱”,我们在关键词概念库中可以召回“在【地名】做【美容项目】需要多少钱”的概念候选,填充完实体后可以召回在【乌市】做【纹眉】需要多少钱。
05
基于度量模型来做同义泛化
1. 基于语义度量来做同义泛化
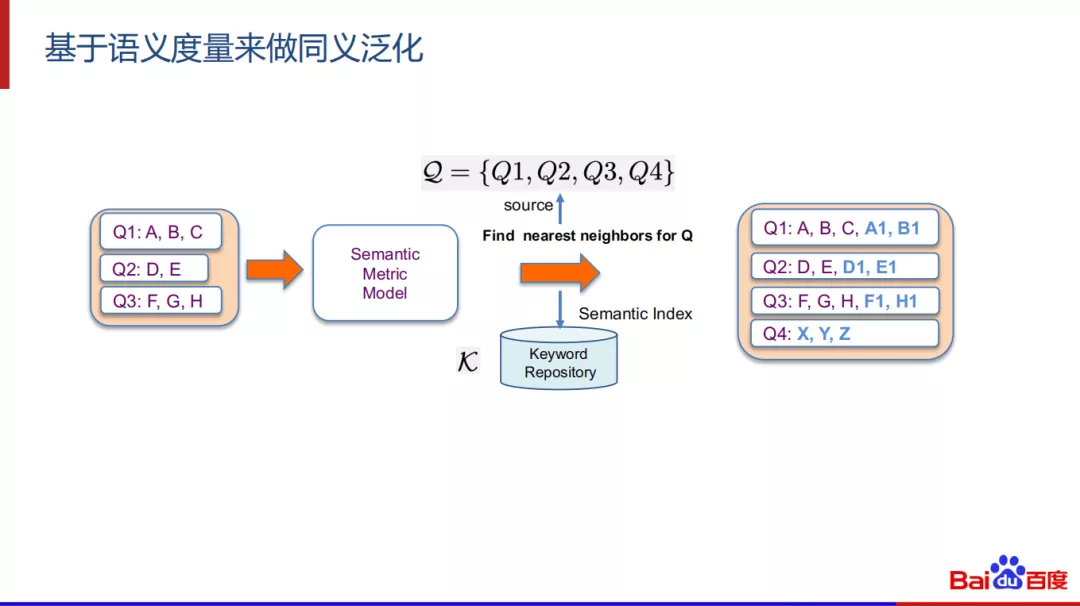
还有一种方式是基于语义度量模型来进行同义泛化,大致的意思就是把翻译模型换成语义向量模型,检索过程是在语义向量空间中寻找K近邻。
2. 在度量语义空间中召回同义变体
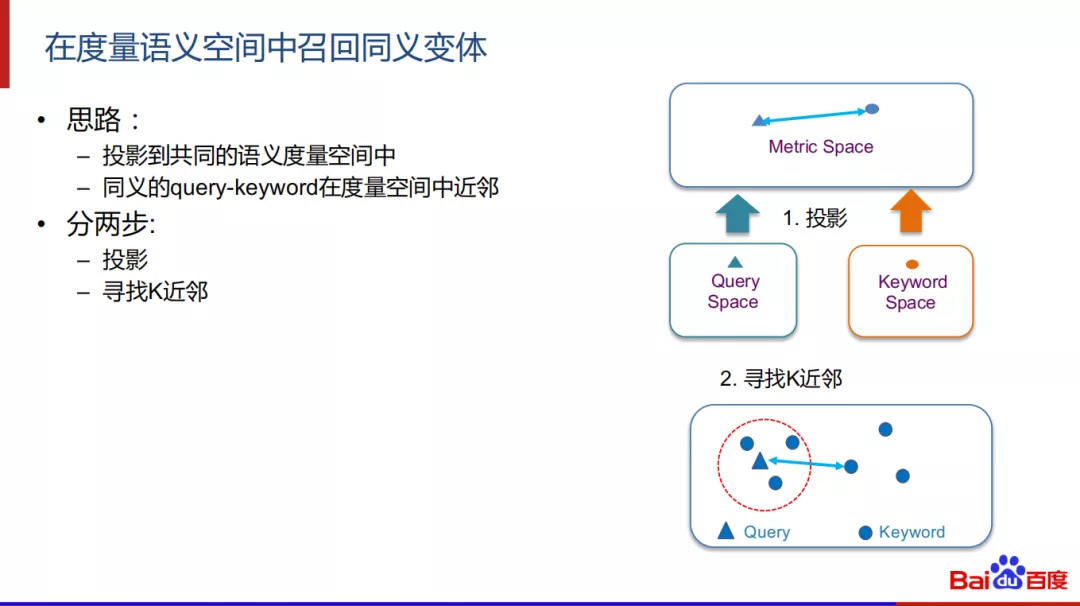
方法的实现思路是:
- 投影到共同的语义度量空间中
- 寻找同义的query-keyword在度量空间中的近邻
分两步来实现:
- 投影
- 寻找k近邻
获得投影算子:
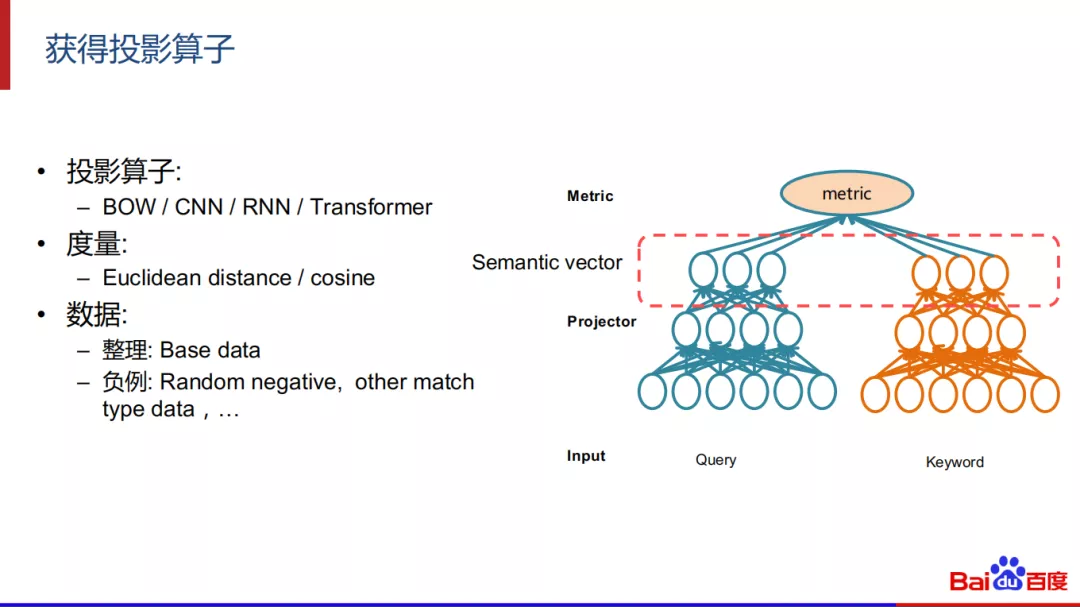
投影算子有很多,例如BOW、CNN、RNN或者Transformer;度量口径可以考虑欧式距离或者余弦相似;在数据方面,因为最后我们会在整个全量空间中做语义检索,和之前的翻译模型不同,我们需要同时考虑正例和负例,并且要精心的去设置负例。
寻找近似K近邻:
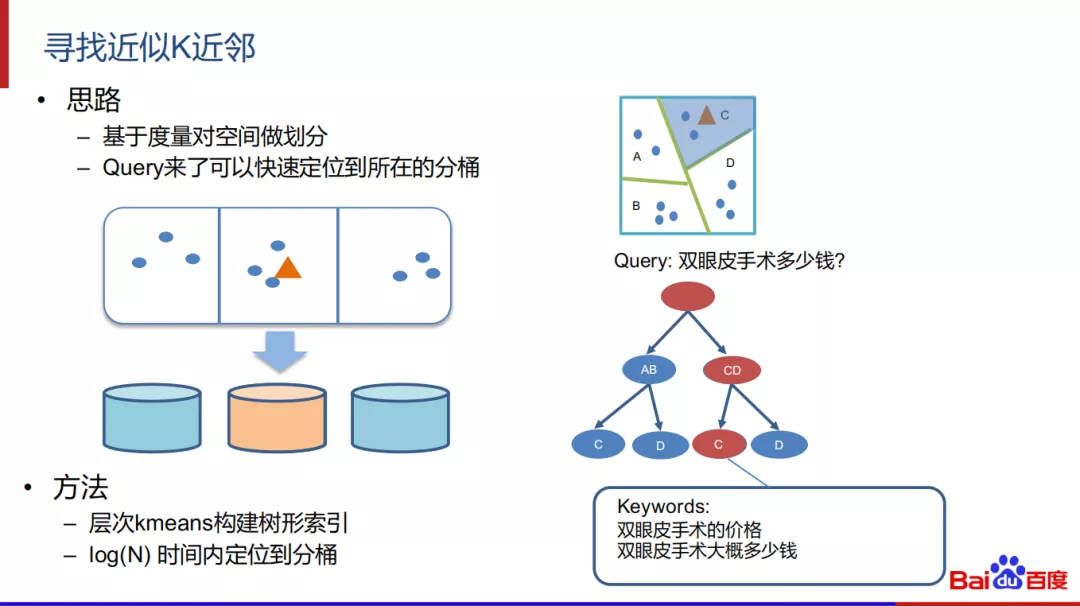
在投影模型训练出来之后,进行K近邻的查找。首先是基于度量对空间做划分,在query来了之后,可以快速定位到所在分桶。在此过程中可以用层次kmeans构建树形索引,然后query来了可以在log(N)时间内定位到分桶。
06 基于图模型来做同义泛化
1. 匹配问题可以看做是Link Prediction问题
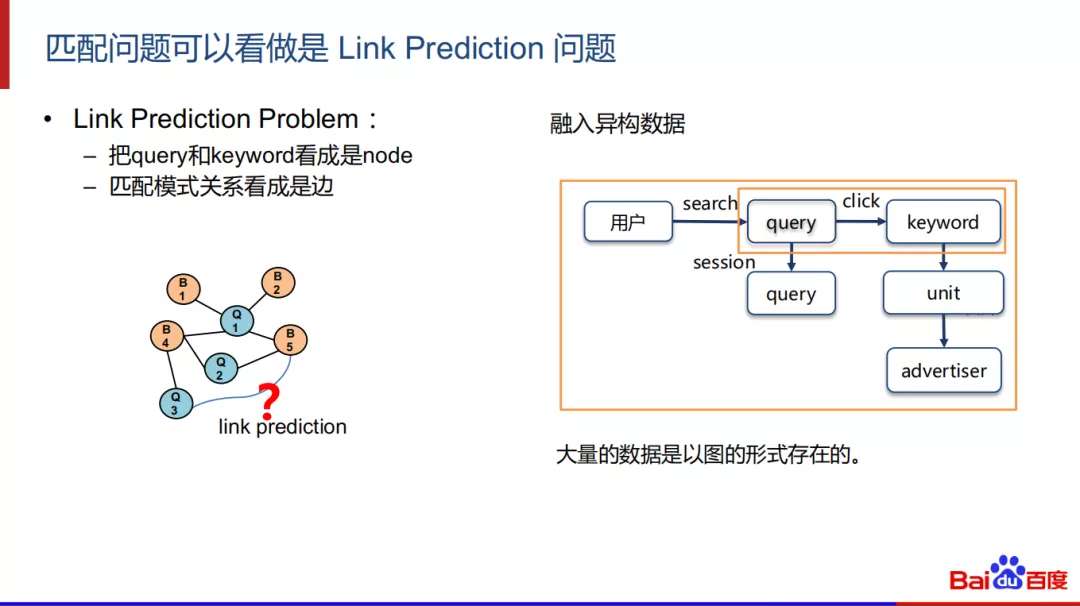
基于图模型来做同义泛化也是一个很好的方案,可以把匹配问题看作link prediction问题,把query和keyword看成node,匹配模式关系看成边。用图来求解匹配问题,我们可以引入更多的数据,因为平时我们使用最多的都是一些简单的线性数据,如用户点击数据,其实更为海量的数据是以图的形式存在的,如用户的seesion日志和广告的购买账户层级数据等等,这样融合在一起形成一个很大的图,我们可以把数据都融入到网中进行训练。
2. 基于图表示来做匹配
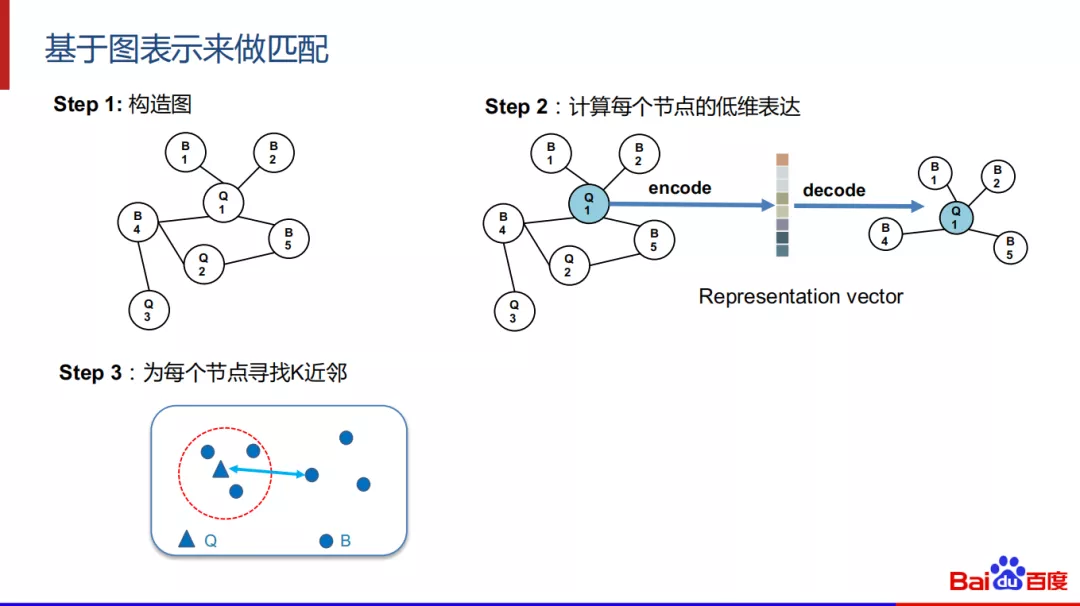
基于图表示来做匹配分为三步走:第一步是构造图,其次是计算每个节点的低维表达,最后是为每个阶段寻找K近邻。
3. 基于递归图网络来计算表达
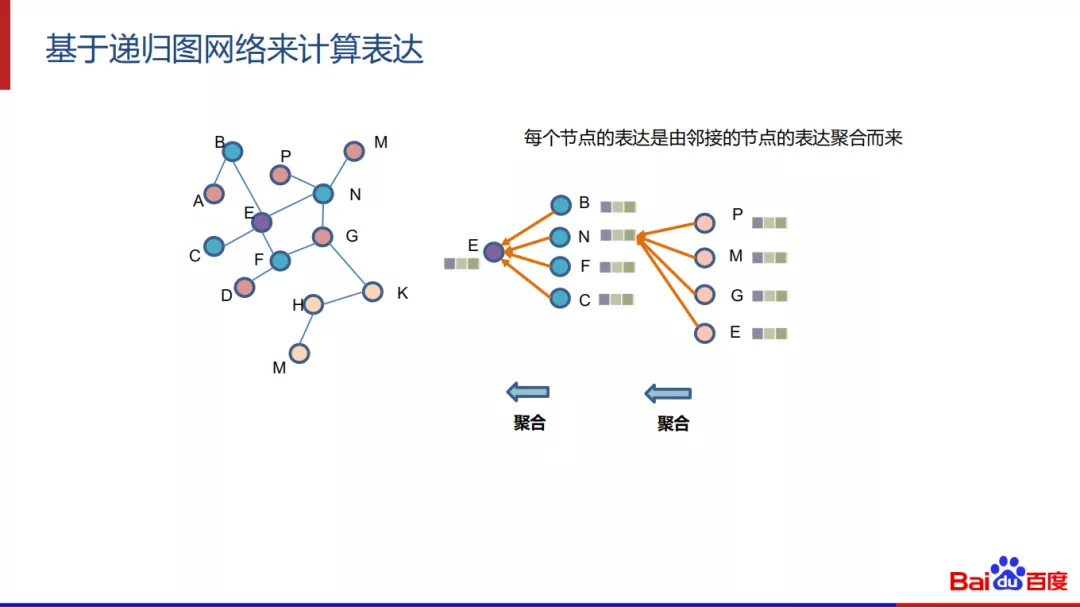
图网络可以选择的方案有很多,比如我们可以选择基于递归图网络来计算表达。在递归图网络中,每一个节点的向量都是由其邻接的节点的表达聚合而来,这样表达的好处是节点之间多跳的邻接关系,还有一对多的关系可以同时考虑到建模道中来。比如对E节点而言,可以通过节点B、N、F、C 聚合向量来表达,同样的,递归下来,每个邻居也可以这么做。比如节点N可以通过节点P、M、G、E来表达。两次传播之后,二跳的信息G就传到了E的节点表达中去了。
4. 总结
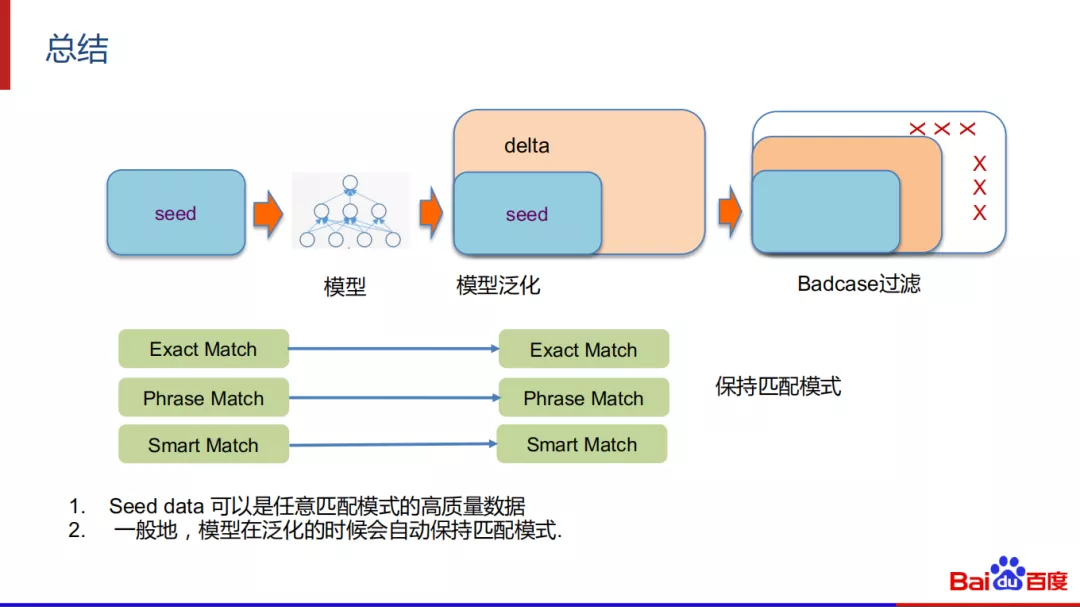
简单总结而言,基于数据驱动的方式做同义变换一般是基于种子数据抽象出一个模型,通过模型来进行泛化得到delta数据。在这里,数据是源,模型是媒介,什么样的数据就会有什么样的泛化结果。这种简单的delta泛化方法在实际中可以很好的保持匹配模式。如果你的数据是Phrase match的,那么泛化出来的一般也是phrase match的。但是在此过程中,因为输入数据的准确性和模型自身的问题, delta泛化不可能是百分百准确的,中间很有可能产生bad case。
07 同义判定
如何对bad case进行过滤,是一个同义判定的问题。
1. 匹配模式判定

在精确匹配模式中,如何判定query-keyword pair是不是同义变体关系 ( paraphrase identification ) ?
一种直观的想法是可以基于同义词对齐来做:这种方式的准确率高,但是召回出来的结果很少,举个例子如“女人生孩子后腹部有赘肉怎么办?”,keyword是“产后如何减肚子”。那么“女人”这个词很难找出对应的关系出来。此时需要一个泛化能力强的模型来做这样的事情。
例如训练一个分类模型,输入,label是0或1。
- Feature-driven的方式是人工特征+少量标记数据+浅层模型;
- Data-driven方式是transformer + 弱监督预训练+domain finetuning。
问题的难点:
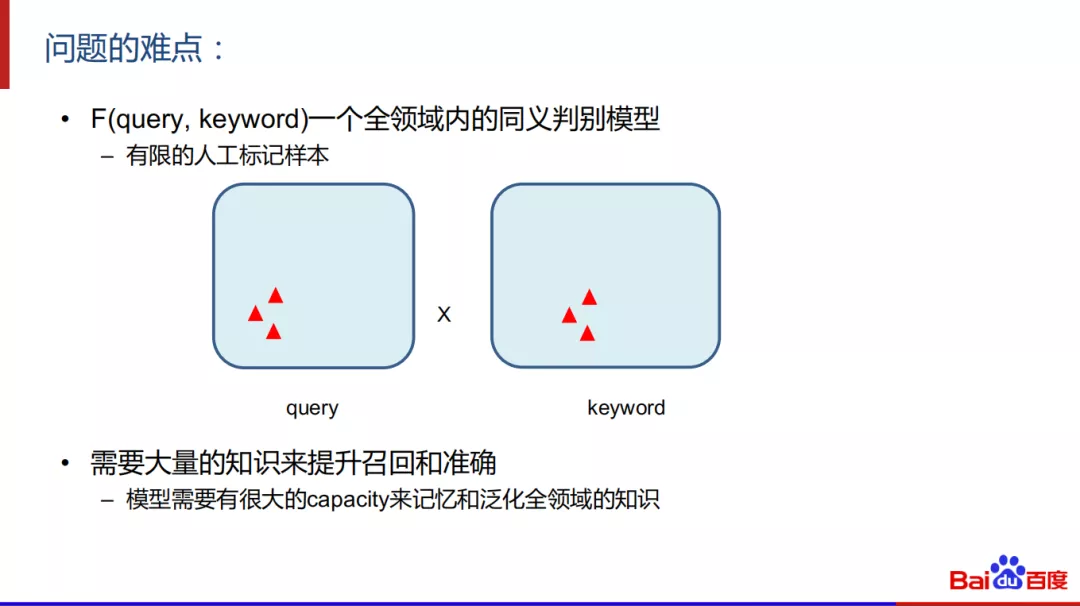
这个问题的难点,一方面因为F是一个全领域内的同义判别模型,在搜索场景中,query和keyword的量很大,而实际中只能够拿到很少的标注数据, 这么少的标记数据很难把方方面面的case都照顾到。另一方面,我们需要大量的知识来提升召回和准确。很多同义关系知道的话,对应的case就可以召回出来,如果不知道就完全召回不出来。此时模型需要很大的capacity来记忆和泛化全领域的知识。
2. 特征驱动的小模型

在特征驱动的小模型中,利用人工定义特征:
- 词粒度的匹配度计算,如max matching length,miss/match和bm25
- 命名实体的相似度、句法依存和文档分类
- 语义相似性,如基于搜索点击数据的DSSM
- 搜索检索结果的相似度
在数据方面,需要少量的人工标记数据。模型一般是是浅层DNN和GBDT之类的树模型。
3. 数据驱动的大模型

在数据驱动的大模型中,包括多阶段预训练finetuing,在百度使用的是ERNIE Large+弱监督数据+人工标记数据的多阶段预训练加finetuning的方式。
数据方面:
- 需要海量的弱监督数据例如用户侧的query-query,商业侧的keyword-keyword和query-keyword
- 少量人工标记数据。因为标注成本比较高,在标注数据之后,最好做一下主动学习和数据增强
训练方面:
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E4%B9%89%E5%8F%98%E6%8D%A2%E5%9C%A8%E7%99%BE%E5%BA%A6%E6%90%9C%E7%B4%A2%E5%B9%BF%E5%91%8A%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


