去哪儿网数据同步平台技术演进与实践

作者介绍
井显生,2019年加入去哪儿,现负责国内机票出票、退款、改签核心业务。在领域驱动设计(DDD)、高并发有大量实践经验。
一、前言
去哪儿网国内机票售后是为用户提供退票、改签、航班变动、行程服务、疫情政策等服务的业务。业务场景中有复杂的基于订单、客票、 PNR 、行程、航司等各种维度的查询诉求,这些数据分散存储在不同的 mysql 数据库表中,难以为复杂业务查询场景提供服务。为解决复杂查询场景,我们设计了一套将数据从一个数据源聚合导入到另一个数据源,提供同构或者异构、低延时的、最终一致性的数据同步系统。
去哪儿数据同步平台是把数据从 mysql 同步到 es 中,并且提供统一的查询网关的服务。随着业务的发展, es 主备集群高可用性存在问题,单一节点故障后难以恢复和补数;同步链路不合理,索引间存在相互影响;公司要求升级 es 集群版本等问题凸显。本文将与大家详细探讨数据同步平台 ES 多版本迁移支持、数据同步平台高可用和数据一致性的设计与实践,希望对大家能够有所帮助或启发。
二、数据同步平台介绍
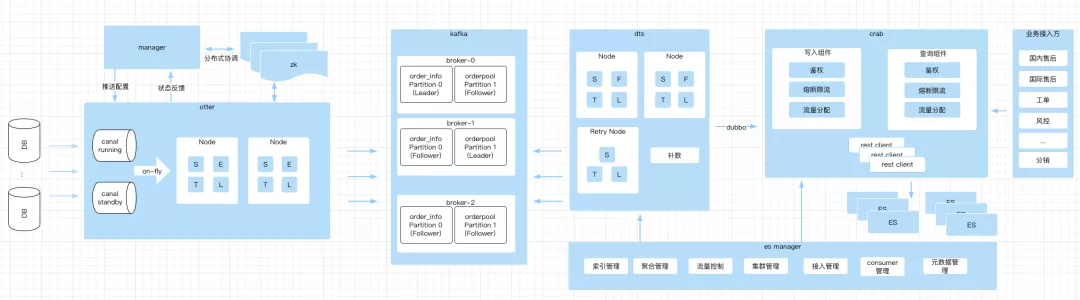
早期去哪儿推出了基于 Databus 的数据同步系统 1.0 。它解决了多表聚合后写入异构数据存储系统(如 es ,hive 等)的问题。为解决 databus 生产者单点问题、canal和数据配置运维困难和查询客户端管理混乱等痛点,数据同步平台做了整体的架构升级。具体的实践,大家可以参考 Qunar 技术沙龙之前的技术博客 《数据同步平台重构实践》。去哪儿数据同步平台主要是数据同步模块、数据中台( crab )和管理模块组成,整体架构如下图所示。
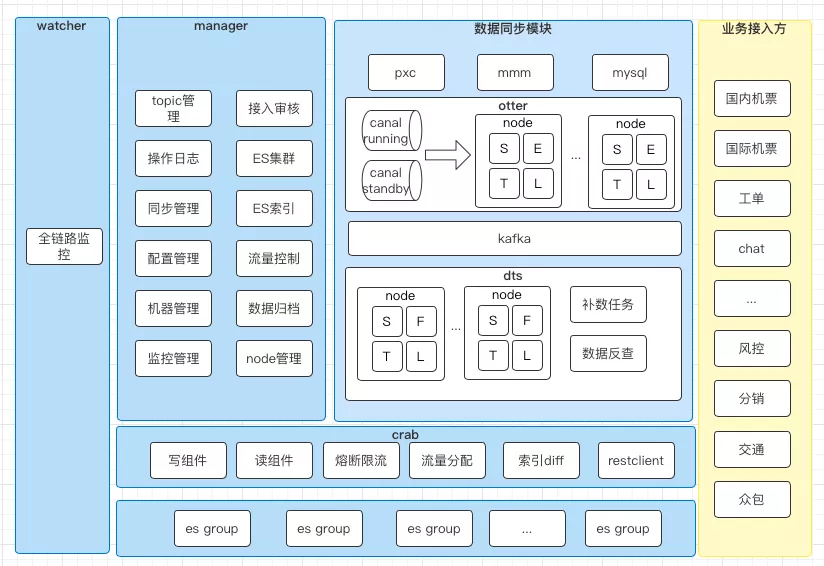
2.1 数据同步平台介绍
数据同步模块包括 databus 、 canal 、 inception gate 等多种实现方案,我们从同步配置易用性、事务性和高可用上考虑选择了阿里巴巴开源分布式数据库同步系统( otter )订阅 mysql binlog ,消息队列使用了 kafka ,数据映射过滤规则自主设计的系统 dts 。
- **otter : ** 基于阿里巴巴开源分布式数据库同步系统改造,主要解决了同步配置页面化、 Databus 生产者单点的问题。同时我们扩展实现了Kafka类型的DataSourceMedia,在otter Load阶段发送消息给Kafka。
- **dts : ** 设计思路参考 otter 的模式,主要包括 Node 、补数任务和数据库反查组件。Node 是由 SFTL 四个阶段组成, S 是从 kafka 消费数据, F 是过滤数据, T 是重新组装数据(主子表关联、 Array 处理), L 是把数据通过 Crab-client 写入 ES 网关中。
2.2 数据中台
数据中台( crab )对内提供了数据同步写入服务,对外提供了统一的查询服务。实现了以 appcode + es 索引维度的 hystrix 熔断、降级和隔离,通过配置设置了 es 集群的查询流量调度。我们还提供了 crab-client 以 java api 形式屏蔽了dsl复杂细节,降低了业务线接入成本。
- **crab : ** 是数据中台,提供了 ES 的读写服务,提供统一的鉴权、熔断限流、流量分配等功能。
- es group: es group 是指一个 index 存在于多个 es 机群中,逻辑上划分为组,为读写提供主备高可用服务。
- 业务接入方: 业务接入方通过 crab-client 接入对 es 进行查询, crab-client 简化了查询复杂度,方便业务接入。
2.3 管理平台
管理平台对整个数据同步平台来说可以是一个 optional 的环境,只有在第一次启动启动时需要,一定启动了任务后,无论管理平台是否可用,不影响正常功能。管理平台维护了数据同步配置、 dts node 的上下线,管理数据中台 crab 的鉴权、限流和 ES 集群读写流量分配。
- mysql mmm pxc: 公司内部 mysql 三种架构(单节点mysql、mmm 和 pxc )。由 otter 内置 canal 订阅 binlog ,提供数据同步元数据。
- manager : 管理工作节点( otter 、 dts 、 crab )运行时的配置,主要包括读写鉴权、 ES 集群分组、 ES 索引维护、 ES 主备集群查询流量分配、dts 数据聚合 node 管理和其他管理功能。
- watcher: 公司内部监控报警平台,为系统提供全链路的监控和报警。
三、技术演进背景
数据同步平台目前接入了 10+ 业务线、14+个 es index。2021 Q2 数据组要求统一升级 es5.x 到 es7.x ,同时数据同步平台高可用和稳定性问题凸显,主要表现在以下四个方面:
- ES 主备(任一)机群故障后,整个同步链路不可用,且故障难恢复。
- 数据库 IP 迁移后,otter 无法自动切换数据库。
- 全链路监控和降级熔断不清晰,难以发现故障,排查问题难。
- 同步链路隔离和降级不合理,一个索引同步故障影响了其他索引的同步。
基于上述系统痛点,制定了以下两个目标:
-
数据同步平台系统具备灵活的缩扩容能力,把 es 集群平滑缩扩容迁移,升级 es5.x 到 es7.x 。
这个目标不仅满足数据组需求,还提高了数据同步平台的高可用能力,单一 es 集群故障时可以灵活的配置上下线恢复故障。
-
同步全链路高可用优化
梳理全链路的流量治理和熔断降级机制,建立同步各个阶段的高可用方案,隔离不同索引同步间的相互影响。
四、技术演进实践
4.1 es 集群 7.x 升级和热拔插
crab 是数据中台,提供了 es 集群的读写服务,核心架构如下图所示。manager 配置 es 集群分组和查询流量控制, crab 定时拉取配置信息,对外提供读写操作。7.x 升级和热拔插目标可以拆解为crab网关支持 es5.x 和 es7.x 并行、es 集群热拔插、es 集群灵活补数三个任务项。
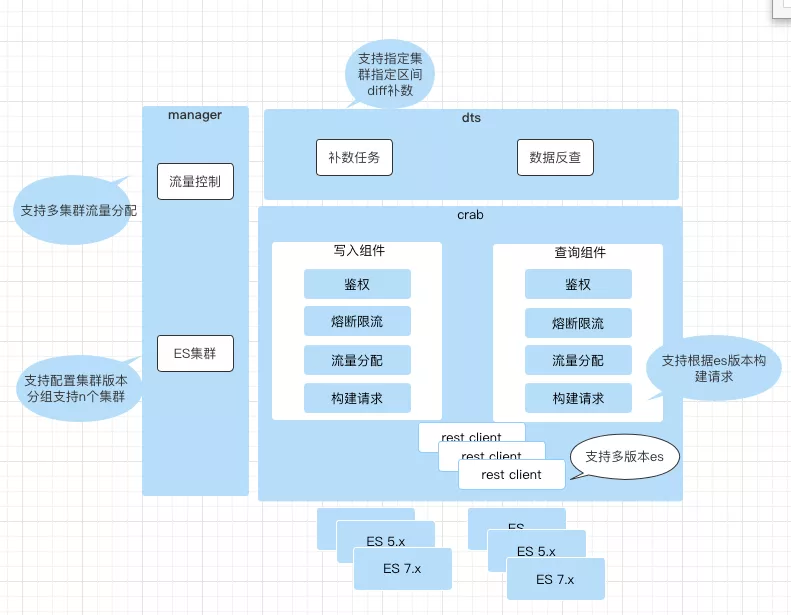
4.1.1 es5.x 和 es7.x 并行
es5.x 和 es7.x 在版本上存在差异,主要包括 es rest client 兼容性,REST APIs 兼容性,es 查询返回值的三部分:
- Elastic rest client
es 客户端目前主要是以下四个,从 es5.x 和 es7.x 多版本支持上看 Elastic java low level rest client兼容所有版本es,综合比较后我们选择使用Elastic java low level rest client。
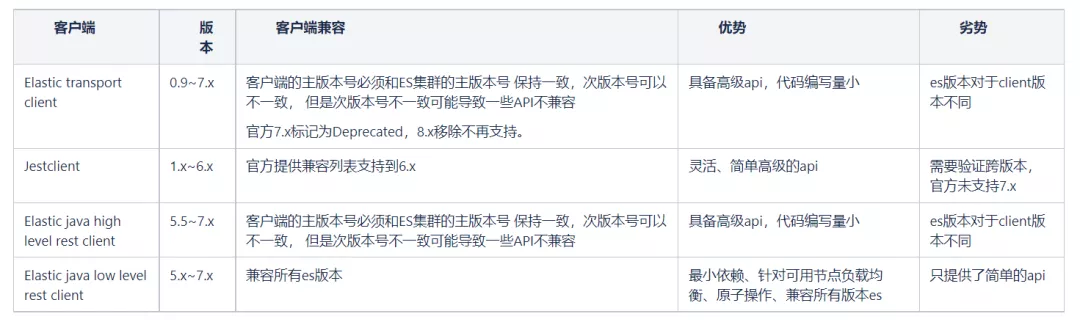
- REST APIs
crab网关支持的REST APIs主要包括Search APIs、Document APIs 和 Script APIs
Search APIs 主要支持 Search 、Scroll 对 ES 进行查询操作。主要区别如下表格。es7.x 功能实现需要在 manager 中配置 ES 的版本, crab 在构建请求时识别 es 的版本后构建不同的 endpoint 进行适配。

Document APIs主要支持 Index、 Update 和 Delete , crab 网关 insert 和 update 操作都统一使用 upsert 操作实现。

- Query DSL 和 Scripting
Elasticsearch 提供了基于 JSON 的完整查询 DSL (Domain Specific Language)来定义查询。es5.x 和 es7.x 版本支持的 dsl 存在差异,针对此场景汇总 crab 中支持的 DSL 语句发现 match 有以下区别;
es nested 类型存储的是父子(1:n)表,更新的时候需要利用 script 解决, es7.x 不再支持 file 的形式指定 script ,需要构建请求时区分 es 版本解决。

- es5.x 和 es7.x 返回值区别
es5.x 和 es7.x 返回值主要差别在 hits 上, es5.x 可以直接返回查询命中数量, es7.x 返回数量是个结构体。如下表。解决方案是 es7.x 的查询 endpoint 默认添加参数 ?track_total_hits=true,返回值的 relation 就是 eq ,获取到返回值后,提取查询名字数量,修改为 es5.x 结构。

4.1.2 es 集群热拔插方案
es 集群热拔插是解决 es7.x 升级的平滑上线和单一 es 集群故障时机群切换的方案。详细切换步骤明细可见下表格。
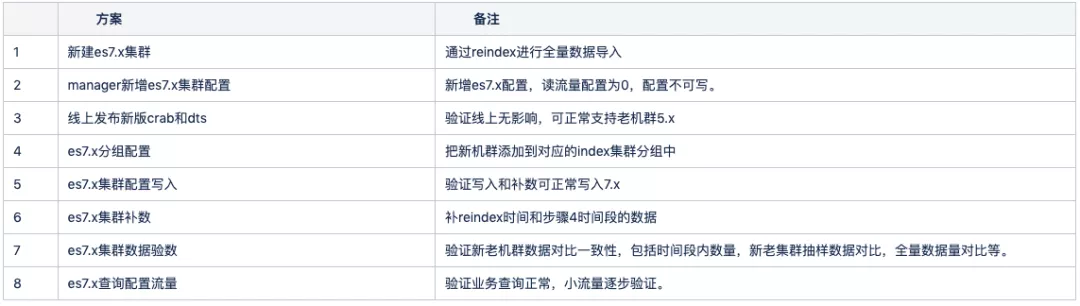
es7.x 上线从时序上核心 5 个阶段,如下图:
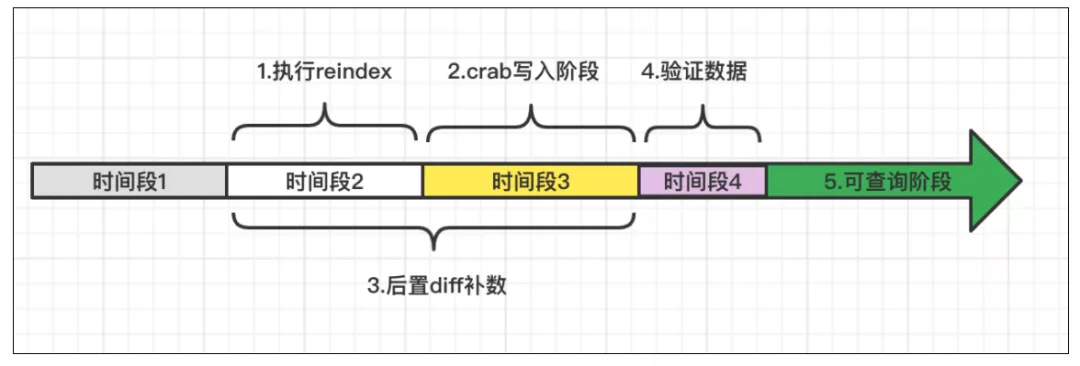
- 执行 reindex 阶段:执行 reindex 将老集群全量数据写入到新集群中,此时新集群中包含的数据是时间段1内的全量数据。
- crab 写入阶段:执行步骤 5 ,此时新产生的数据可以写入新集群,新集群中缺失时间段 2 的数据。
- 后置 diff 补数:从反查组件中查询全量数据,通过crab网关写入组件写入时间段 2 缺失的数据和时间段 3 遗漏的数据。
- 验证数据:验证新老集群时间段数据和抽样 diff 新老集群数据。
- 可查询阶段:diff 一致后新集群可以切换查询。
4.1.3 es 集群灵活补数
针对补数有全量、部分补数的需求,我们制定了 reindex 、 canal 移动位点、 diff 补数定时任务三个补数方案方案。
- reindex:ES 提供了 _reindex 这个 API 供索引进行重建,这种方式可以全量数据重建,具体代码如下:
curl -H "Content-Type: application/json" -XPOST http://ip:port/_reindex -d'{
"source": {
"remote": {
"host": "http://ip:port"
},
"index": "order_info_beta_tts8"
},
"dest": {
"index": "order_info_beta_tts8"
}
}'
reindex 补数方案适用于上图时间段 1 的补数,可以把集群 1 索引的数据全量导入到指定的新集群。
- canal 移动位点: 通过修改 canal 的位点信息,重新拉取 binlog 方式进行同步补数,由于 binlog 保存时长的问题,位点只能重新同步最近的数据,修改方式如下图:
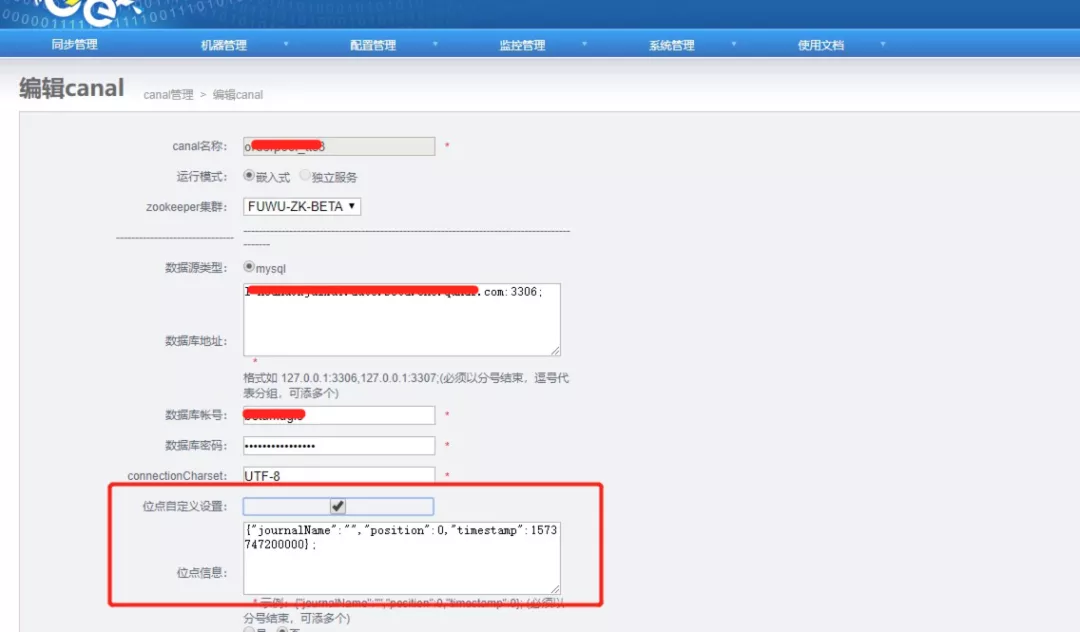
canal 位点方案适用于时间段近、集群读写 qps 不高的场景,可以用于时间段 2 的补数方案。
- diff 补数定时任务: 通过反查组件,反查数据库全量数据方式进行es数据重写。
canal 位点方案适用于时间段近、集群读写 qps 不高的场景,可以用于时间段 2 的补数方案。
- diff 补数定时任务: 通过反查组件,反查数据库全量数据方式进行 es 数据重写。
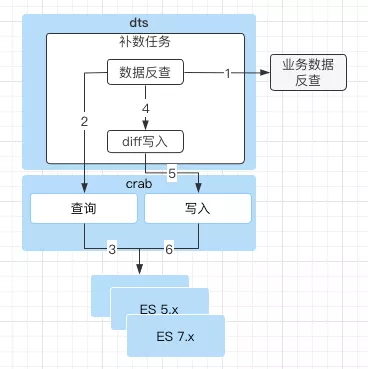
diff 补数方案是精确补数方案,由业务方实现反查组件,数据同步平台调用获取数据后通过 es 网关获取索引中的数据,对比不一致的通过 crab 写入组件写入对应的索引集群。diff 方案可以实现精确补数,缺点是业务接入方有业务开发量。目前线上支持国内机票、国际机票等核心业务。
4.2 数据一致性和高可用
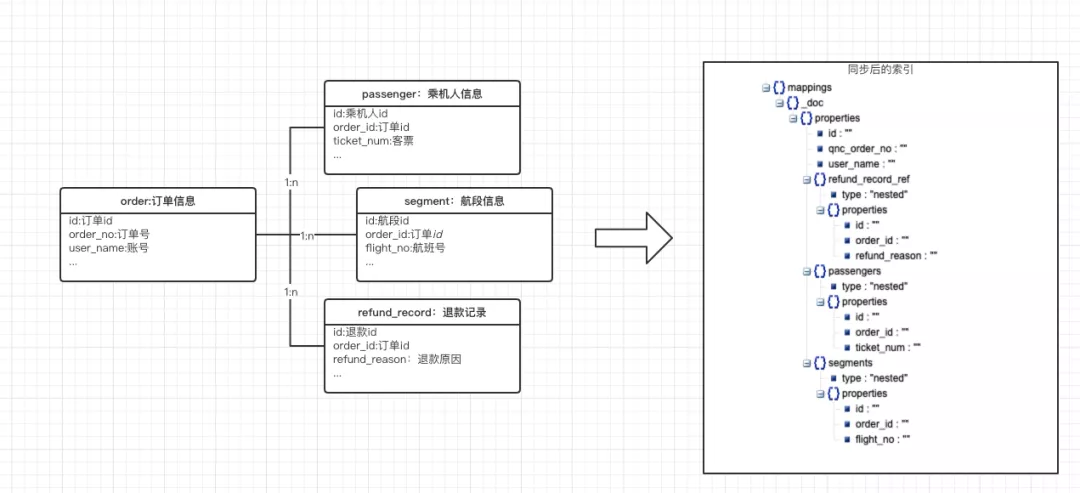
要介绍数据同步平台的数据一致性和高可用,首先以国内机票为例,核心同步信息有订单信息(1)、乘机人信息(n)、航段信息(n)、退款记录(n)等,同步到 ES 索引结构如下图所示。订单信息创建了单个文档,乘机人、航段和退款记录等数组以nested data type内部文档存储。
数据同步流程是由 otter 内置 canal 订阅 binlog 后经过 SETL 四个流程后,写入到 kafka 。dts 消费 kafka 数据,经过 SFTL 四个流程后写入 crab ,最终写入 ES 集群中,如下图所示。
- 数据顺序和最终一致性的保证:
数据最终一致性的保证是由三个层面:1. 数据同步的时候链路上同纬度数据是顺序性的;2. 数据在链路写入失败时,进入失败重试队列;3. 针对重要集群建立 diff 补数任务。
- 按照单维度数据的同步顺序性(otter → kafka → dts → crab → es)
otter Load 阶段写 kafka 时 partition ,要保证同业务分配到同一个 partition 。例如国内机票业务发送 kafka 的partition key 是库名 + order_id ,这样可以保证一个订单下的所有binlog被发送到同一个 partition 内。
dts 消费 kafka 的时候是单线程的,处理数据也是有顺序的。通过 dubbo 接口写到 crab 网关时,也是顺序写入 es 中。
- 数据在链路写入失败时,进入失败重试队列
dts 到 crab 和 crab 处理数据过程中都可能因为各种原因失败异常,系统捕获到异常后将数据写入 retry kafka 队列, dts 消费 retry 数据后,通过数据库反查组件,查询最新数据写入 crab 网关保证数据最终一致。
- 针对重要集群建立 diff 补数任务
针对国内机票和国际机票等重要索引,建立了最新一分钟数据 diff 补数逻辑,定时任务通过反查组件,查询全量一分钟数据,跟 es 数据 diff 比较,不一致的数据写入 crab 网关保证数据最终一致性。
- 数据同步链路的高可用:
数据同步链路的高可用(同步顺序:otter → kafka → dts → crab → es)如下:
otter:otter以Pipeline(可以理解成一个es索引的同步)运行在不同的 otter node 中,实现了索引间的隔离。同时内置 canal 以主备模式, S 和 L 阶段以主备模式运行在多个 Node 中,实现了单索引的高可用。
kafka:以每个索引一个 topic ,每个 topic 有多个 partition ,每个 partition 有多个副本实现了高可用。
dts:以 kafka 的 topic 为维度生成了多个 Node 消费数据,以线程隔离的方式实现了索引间的隔离。多个 consumer 实现了单索引的高可用,一个 consumer 销毁后其他 consumer 可继续消费数据。
crab:以调用方 appcode+ 索引维度创建了 Hystrix 线程池,不仅隔离了索引间的影响还保证了单索引的承载能力。
es:一个索引保存在多个 es 集群中,由管理系统配置查询分流实现了索引的高可用。
由于数据同步平台出现过 kafka 磁盘空间满、 zk 故障等异常 case ,此时可以通过 4.1.3es 集群灵活补数方式对集群进行部署和恢复服务。
- 数据同步的优化:
- 以国际机票生单为例,一个操作是会产生多个主子表的 binlog ,多个 binlog 会写入到同一个 partition , dts 在消费时可以根据业务特性,以服务单单号为 key ,一批内只保留最后一个 binlog 执行反查和写入,即一批 binlog 中同一个服务单单号不管有几个 binlog ,最后执行反查和写入的只有一次。
- otter 数据库主备切换并未开源,根据公司主流 mysql 是 pxc 架构,我们定制实现了数据库主备切换功能。
- otter S 阶段默认拉取 10000 条数据,在大表有 DDL 操作时会打满网卡造成故障,我们根据拉取条数变化动态调整拉取设置。
五、总结和未来规划
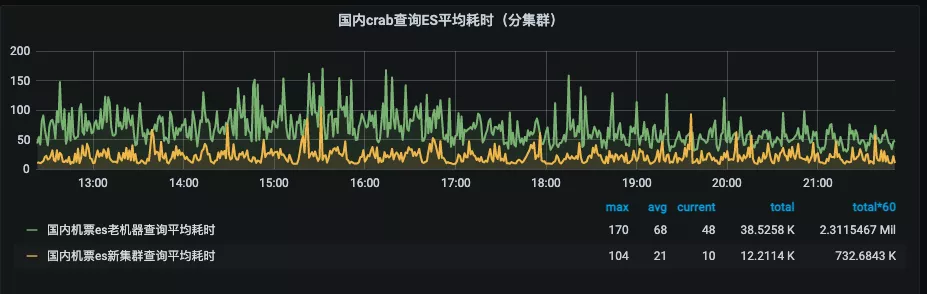
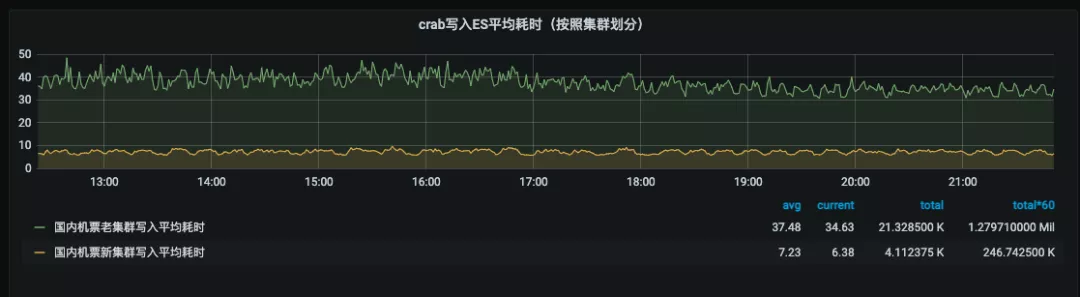
通过以上方案,顺利完成了预期目标,实现了数据同步平台的全链路监控和全链路高可用。另外 es 集群读写性能有了量级的变化,国内机票 es5.x 迁移 7.x 查询耗时从 68ms 下降到21ms (下图1),写入耗时从 34ms 下降到 6ms (下图2):
系统上线后,在日常维护中出现了几次
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%8E%BB%E5%93%AA%E5%84%BF%E7%BD%91%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5%E5%B9%B3%E5%8F%B0%E6%8A%80%E6%9C%AF%E6%BC%94%E8%BF%9B%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


