去哪儿网倒排索引原理
作者 : 高沛, 2018年7月加入去哪儿网,目前负责酒店搜索、门票搜索、大搜等搜索相关业务,曾参与基于Lucene的搜索召回服务搭建,个人对搜索引擎、分布式技术比较感兴趣,喜欢探究技术内幕、深入了解底层原理。
1 前言
Lucene 作为 Apache 开源的一款搜索工具,一直以来是实现搜索功能的神兵利器,现今火热的 Solr 和 Elasticsearch 均基于该工具包进行开发,我们搜索召回组这边也是基于 Lucene 实现了一套索引构建机制,用于酒店搜索、门票搜索、大搜等搜索相关业务。
而 Lucene 之所以能在搜索中发挥至关重要的作用正是因为倒排索引。
因此,本文将介绍一下倒排索引的概念以及倒排索引在 Lucene 中的实现。
2 基本原理
2.1 什么是倒排索引
搜索的核心需求是全文检索,全文检索简单来说就是要在大量文档中找到包含某个单词出现的位置,在传统关系型数据库中,数据检索只能通过 like 来实现,例如需要在酒店数据中查询名称包含公寓的酒店,需要通过如下 sql 实现:
select * from hotel_table where hotel_name like '%公寓%';
这种实现方式实际会存在很多问题:
- 无法使用数据库索引,需要全表扫描,性能差
- 搜索效果差,只能首尾位模糊匹配,无法实现复杂的搜索需求
- 无法得到文档与搜索条件的相关性
搜索的核心目标实际上是保证搜索的效果和性能,为了高效的实现全文检索,我们可以通过倒排索引来解决。
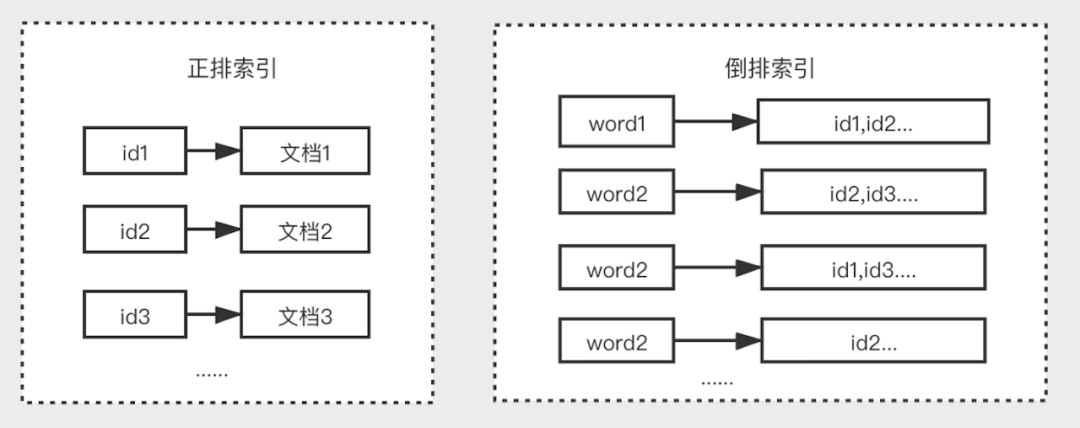
倒排索引是区别于正排索引的概念:
- 正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。
- 倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。
下面通过一个例子来说明下倒排索引的生成过程。
假设目前有以下两个文档内容:
苏州街维亚大厦
桔子酒店苏州街店
其处理步骤如下:
- 正排索引给每个文档进行编号,作为其唯一的标识。
文档 idcontent1苏州街维亚大厦2桔子酒店苏州街店
- 生成倒排索引:
a.首先要对字段的内容进行分词,分词就是将一段连续的文本按照语义拆分为多个单词,这里两个文档包含的关键词有:*苏州街、维亚大厦*.....
b.然后按照单词来作为索引,对应的文档 id 建立一个链表,就能构成上述的倒排索引结构。
Word
文档 id苏州街
1,2维亚大厦
1
维亚
1桔子
2酒店
2
大赛1
有了倒排索引,能快速、灵活地实现各类搜索需求。整个搜索过程中我们不需要做任何文本的模糊匹配。
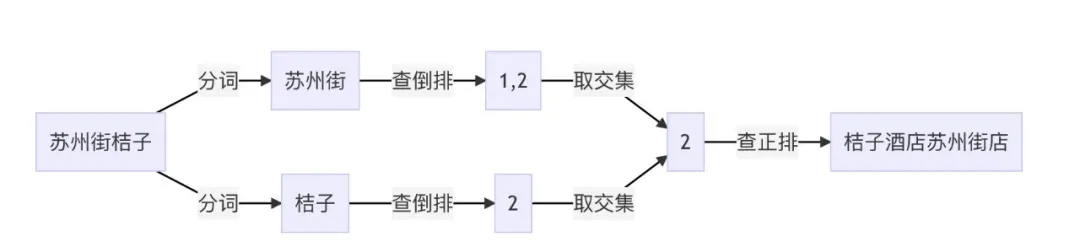
例如,如果需要在上述两个文档中查询 苏州街桔子 ,可以通过分词后通过 *苏州街 查到 1、2,通过 桔子 \* 查到 2,然后再进行 取交取并 等操作得到最终结果。
2.2 倒排索引的结构
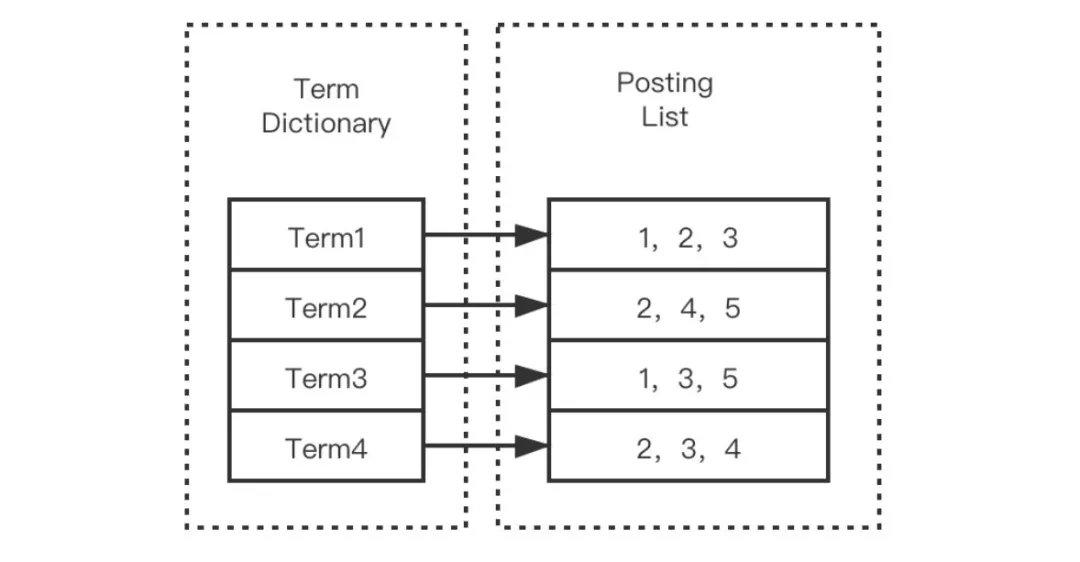
根据倒排索引的概念,我们可以用一个 Map来简单描述这个结构。这个 Map 的 Key 的即是分词后的单词,这里的单词称为 Term,这一系列的 Term 组成了倒排索引的第一个部分 —— Term Dictionary (索引表,可简称为 Dictionary)。
倒排索引的另一部分为 Postings List(记录表),也对应上述 Map 结构的 Value 部分集合。
记录表由所有的 Term 对应的数据(Postings) 组成,它不仅仅为文档 id 信息,可能包含以下信息:
- 文档 id(DocId, Document Id),包含单词的所有文档唯一 id,用于去正排索引中查询原始数据。
- 词频(TF,Term Frequency),记录 Term 在每篇文档中出现的次数,用于后续相关性算分。
- 位置(Position),记录 Term 在每篇文档中的分词位置(多个),用于做词语搜索(Phrase Query)。
- 偏移(Offset),记录 Term 在每篇文档的开始和结束位置,用于高亮显示等。
3 Lucene 倒排索引实现
全文搜索引擎在海量数据的情况下是需要存储大量的文本,所以面临以下问题:
- Dictionary 是比较大的(比如我们搜索中的一个字段可能有上千万个 Term)
- Postings 可能会占据大量的存储空间(一个Term多的有几百万个doc)
因此上面说的基于 Map 的实现方式几乎是不可行的。
在海量数据背景下,倒排索引的实现直接关系到存储成本以及搜索性能。
为此,Lucene 引入了多种巧妙的数据结构和算法。其倒排索引实现拥有以下特性:
- 以较低的存储成本存储在磁盘 (索引大小大约为被索引文本的20-30%)
- 快速读写
下面将根据倒排索引的结构,按 Posting List 和 Terms Dictionary 两部分来分析 Lucene 中的实现。
3.1 Posting List 实现
PostingList 包含文档 id、词频、位置等多个信息,这些数据之间本身是相对独立的,因此 Lucene 将 Postings List 被拆成三个文件存储:
- .doc后缀文件:记录 Postings 的 docId 信息和 Term 的词频
- .pay后缀文件:记录 Payload 信息和偏移量信息
- .pos后缀文件:记录位置信息
基本所有的查询都会用 .doc 文件获取文档 id,且一般的查询仅需要用到 .doc 文件就足够了,只有对于近似查询等位置相关的查询则需要用位置相关数据。
三个文件整体实现差不太多,这里以.doc 文件为例分析其实现。
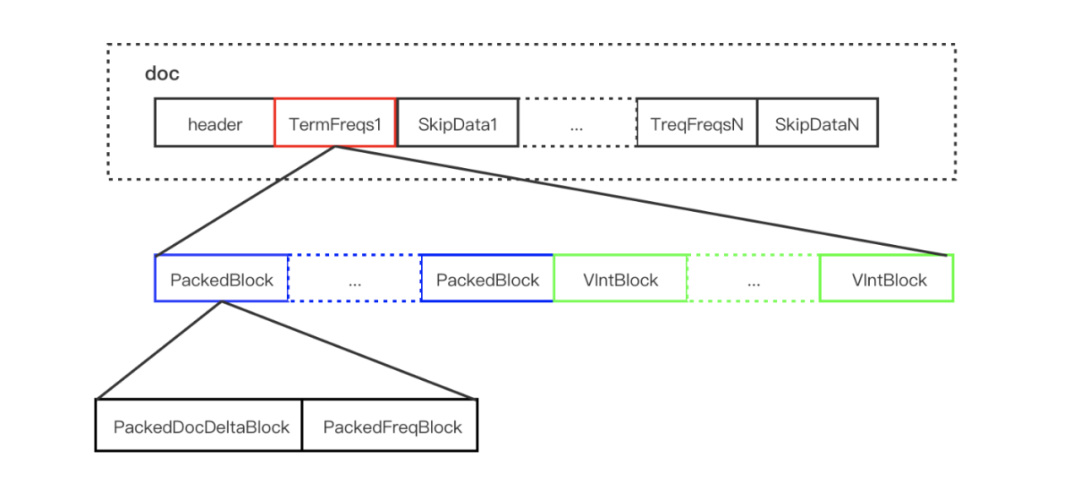
.doc 文件存储的是每个 Term 对应的文档 Id 和词频。每个 Term 都包含一对 TermFreqs 和 SkipData 结构。
其中 TermFreqs 存放 docId 和词频信息,SkipData 为跳表信息,用于实现 TermFreqs 内部的快速跳转。

3.1.1 TermFreqs
TermFreqs 存储文档号和对应的词频,它们两是一一对应的两个 int 值。Lucene 为了尽可能的压缩数据,采用的是混合存储 ,由 PackedBlock 和 VIntBlocks 两种结构组成。
PackedBlock
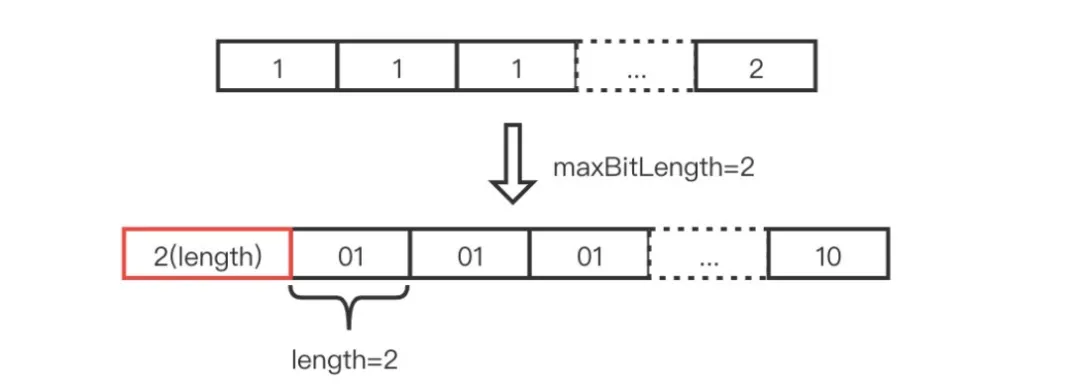
其采用 PackedInts 结构将一个 int[] 压缩打包成一个紧凑的 Block。它的压缩方式是取数组中最大值所占用的 bit 长度作为一个预算的长度,然后将数组每个元素按这个长度进行截取,以达到压缩的目的。
例如:一个包含128个元素的 int 数组中最大值的是 2,那么预算长度为2个 bit, PackedInts 的长度仅是 2 * 128 / 8 = 32个字节,然后就可以通过4个 long 值存储。
VIntBlock
VIntBlock 是采用 VInt 来压缩 int 值,对于绝大多数语言,int 型都占4个字节,不论这个数据是1、100、1000、还是1000,000。VInt 采用可变长的字节来表示一个整数。数值较大的数,使用较多的字节来表示,数值较少的数,使用较少的字节来表示。每个字节仅使用第1至第7位(共7 bits)存储数据,第8位作为标识,表示是否需要继续读取下一个字节。
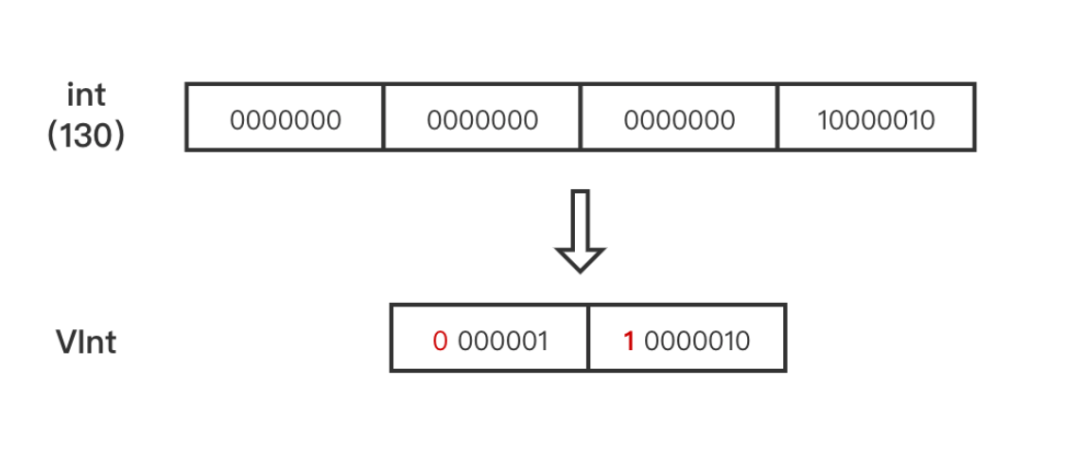
举个例子:
整数130为 int 类型时需要4个字节,转换成 VInt 后仅用2个字节,其中第一个字节的第8位为1,标识需要继续读取第二个字节。
根据上述两种 Block 的特点,Lucene 会每处理包含 Term 的128篇文档,将其对应的 DocId 数组和 TermFreq 数组分别处理为 PackedDocDeltaBlock 和 PackedFreqBlock 的 PackedInt 结构,两者组成一个 PackedBlock,最后不足128的文档则采用 VIntBlock 的方式来存储。
3.1.2 SkipData
在搜索中存在将每个 Term 对应的 DocId 集合进行取交集的操作,即判断某个 Term 的 DocId 在另一个 Term 的 TermFreqs 中是否存在。TermFreqs 中每个 Block 中的 DocId 是有序的,可以采用顺序扫描的方式来查询,但是如果 Term 对应的 doc 特别多时搜索效率就会很低,同时由于 Block 的大小是不固定的,我们无法使用二分的方式来进行查询。因此 Lucene 为了减少扫描和比较的次数,采用了 SkipData 这个跳表结构来实现快速跳转。
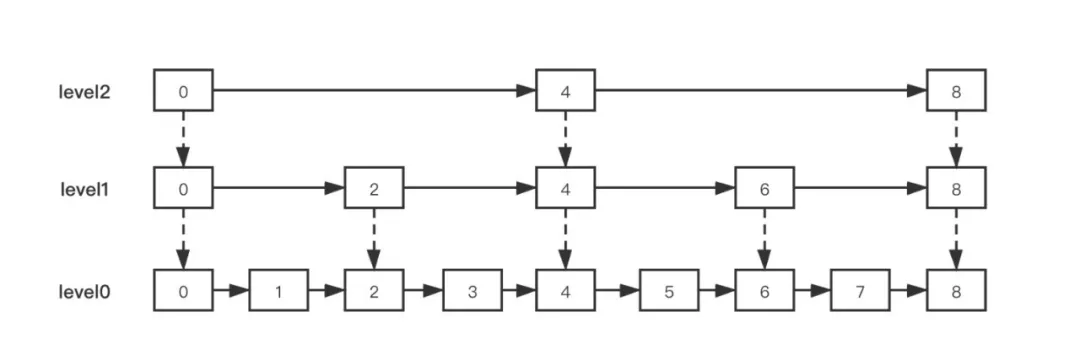
跳表
跳表是在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
实质就是一种可以进行二分查找的有序链表。
SkipData结构
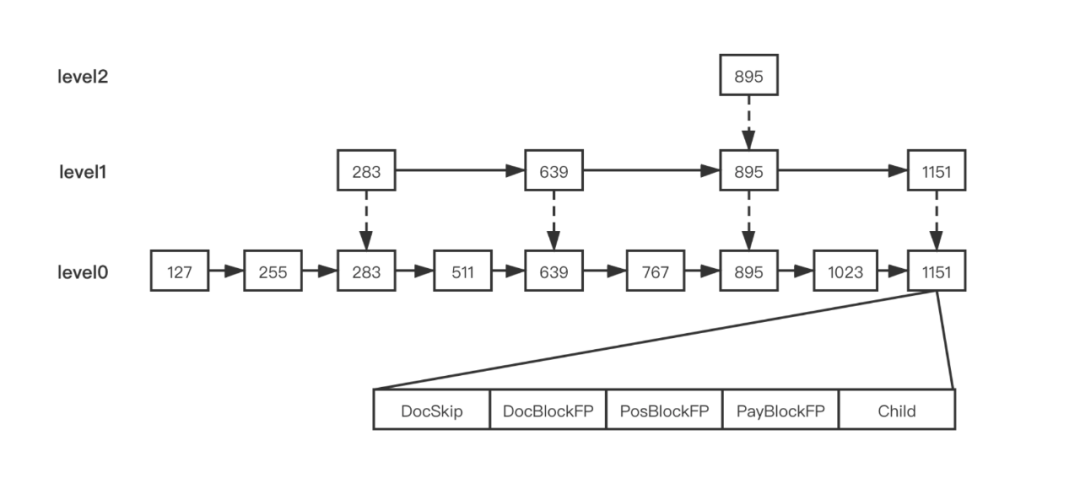
在 TermFreqs 中每生成一个 Block 就会在 SkipData 的第0层生成一个节点,然后第0层以上每隔 N 个节点生成一个上层节点。
每个节点通过 Child 属性关联下层节点,节点内 DocSkip 属性保存 Block 的最大的 DocId 值,DocBlockFP、PosBlockFP、PayBlockFP 则表示 Block 数据对应在 .pay、.pos、.doc 文件的位置。
3.1.3 Posting 最终数据
Posting List 采用多个文件进行存储,最终我们可以得到每个 Term 的如下信息:
- SkipOffset:用来描述当前 term 信息在 .doc 文件中跳表信息的起始位置。
- DocStartFP:是当前 term 信息在 .doc 文件中的文档 ID 与词频信息的起始位置。
- PosStartFP:是当前 term 信息在 .pos 文件中的起始位置。
- PayStartFP:是当前 term 信息在 .pay 文件中的起始位置。
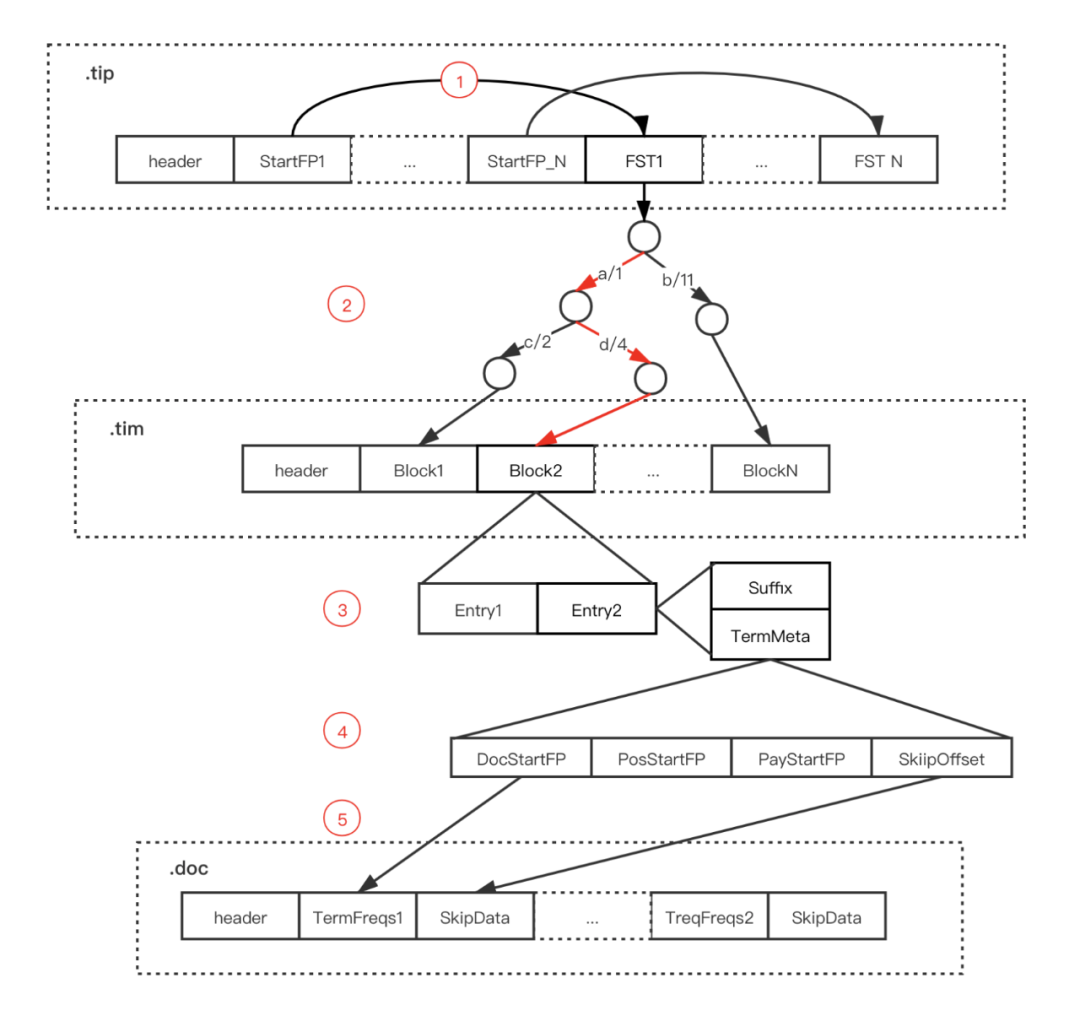
3.2 Term Dictionary 实现
Terms Dictionary(索引表)存储所有的 Term 数据,同时它也是 Term 与 Postings 的关系纽带,存储了每个 Term 和其对应的 Postings 文件位置指针。
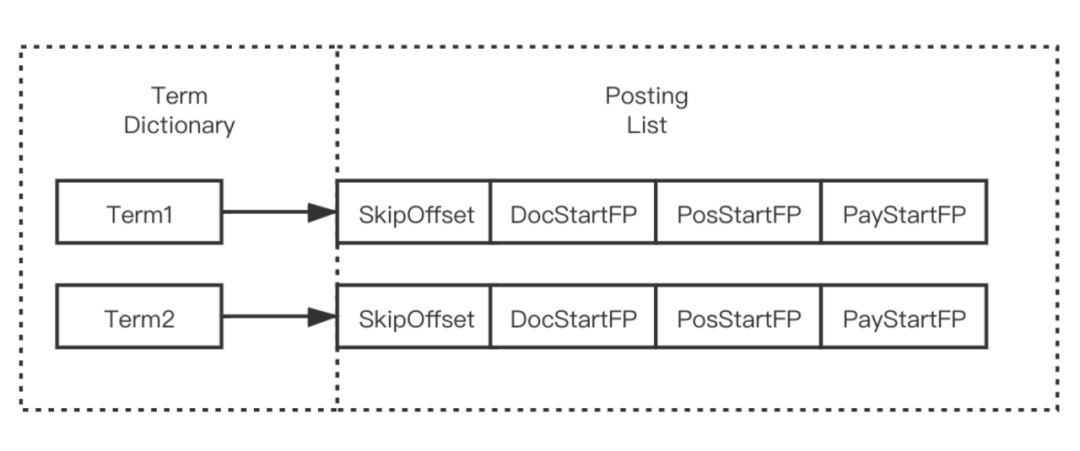
3.2.1 数据存储
Terms Dictionary 通过 .tim 后缀文件存储,其内部采用 NodeBlock 对 Term 进行压缩前缀存储,处理过程会将相同前缀的的 Term 压缩为一个 NodeBlock,NodeBlock 会存储公共前缀,然后将每个 Term 的后缀以及对应 Term 的 Posting 关联信息处理为一个 Entry 保存到 Block。
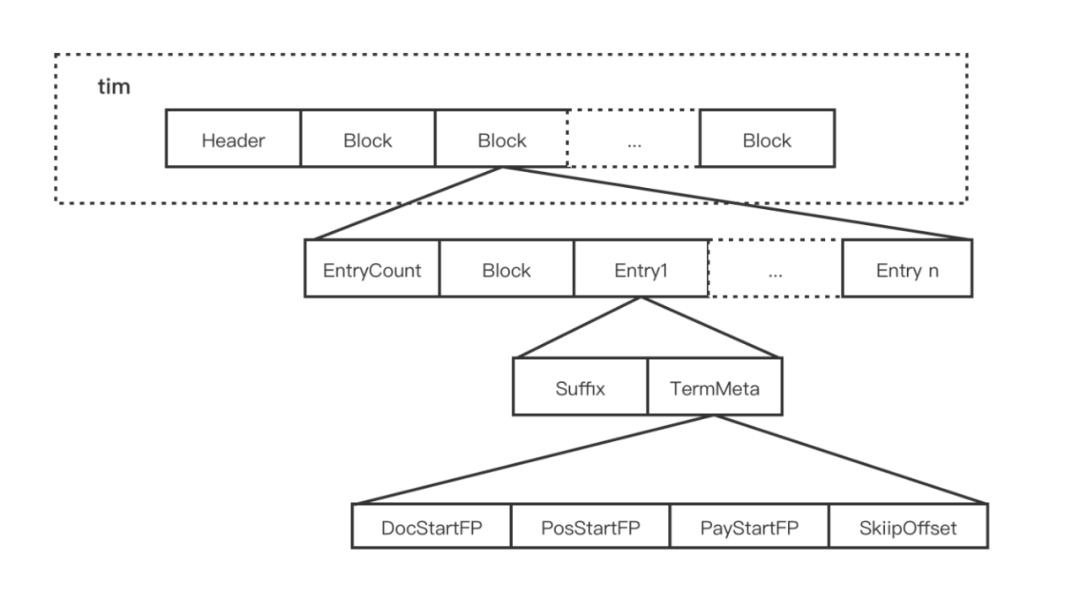
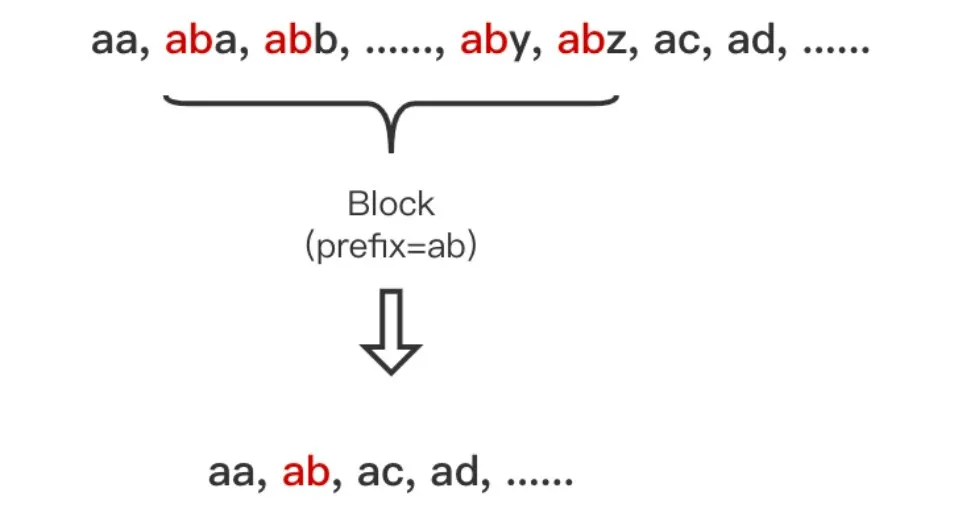
****在上图中可以看到 Block 中还包含了 Block,这里是为了处理包含相同前缀的 Term 集合内部部分 Term 又包含了相同前缀。
举个例子,在下图中为公共前缀为 a 的 Term 集合,内部部分 Term 的又包含了相同前缀 ab,这时这部分 Term 就会处理为一个嵌套的 Block。
3.2.2 数据查找
Terms Dictionary 是按 NodeBlock 存储在.tim 文件上。当文档数量越来越多的时,Dictionary 中的 Term 也会越来越多,那查询效率必然也会逐渐变低。
因此需要一个很好的数据结构为 Dictionary 建构一个索引,这就是 Terms Index(.tip文件存储),Lucene 采用了 FST 这个数据结构来实现这个索引。
FST
FST, 全称 Finite State Transducer(有限状态转换器)。
它具备以下特点:
- 给定一个 Input 可以得到一个 output,相当于 HashMap
- 共享前缀、后缀节省空间,FST 的内存消耗要比 HashMap 少很多
- 词查找复杂度为 O(len(str))
- 构建后不可变更
如下图为 mon/1,thrus/4,tues/2 生成的 FST,可以看到 thrus 和 tues 共享了前缀 t 以及后缀 s。
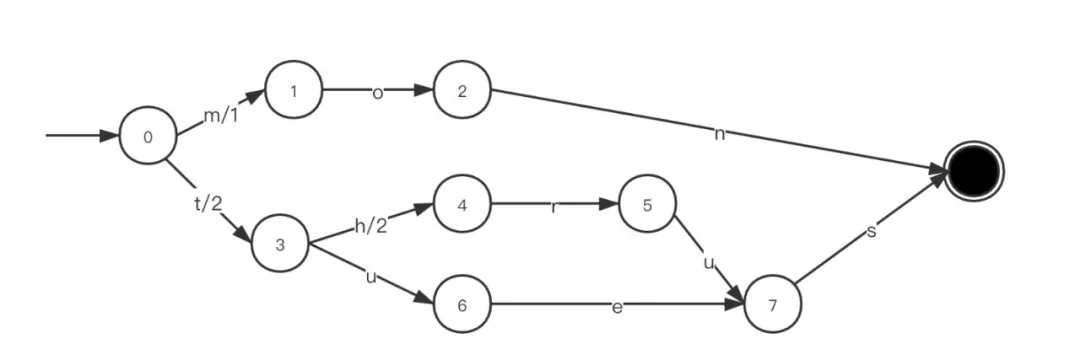
根据 FST 就可以将需要搜索 Term 作为 Input,对其途径的边上的值进行累加就可以得到 output,下述为以 input 为 thrus 的读取逻辑:
- 初始状态0
- 输入t, FST 从0 -> 3, output=2
- 输入h,FST 从3 -> 4, output=2+2=4
- 输入r, FST 从4 -> 5, output=4+0
- 输入u,FST 从5 -> 7, output=4+0
- 输入s, FST 到达终止节点,output=4+0=4
那么 Term Dictionary 生成的 FST 对应 input 和 output 是什么呢?可能会误认为 FST 的 input 是 Dictionary 中所有的 Term,这样通过 FST 就可以找到具体一个 Term 对应的 Posting 数据。
实际上 FST 是通过 Dictionary 的每个 NodeBlock 的前缀构成,所以通过 FST 只可以直接找到这个 NodeBlock 在 .tim 文件上具体的 File Pointer, 然后还需要在 NodeBlock 中遍历 Entry 匹配后缀进行查找。
因此它在 Lucene 中充当以下功能:
- 快速试错,即是在 FST 上找不到可以直接跳出不需要遍历整个 Dictionary,类似于 BloomFilter。
- 快速定位 Block 的位置,通过 FST 是可以直接计算出 Block 的在文件中位置。
- FST 也是一个 Automation(自动状态机)。这是正则表达式的一种实现方式,所以 FST 能提供正则表达式的能力。通过 FST 能够极大的提高近似查询的性能,包括通配符查询、SpanQuery、PrefixQuery 等。
3.3 倒排查询逻辑
在介绍了索引表和记录表的结构后,就可以得到 Lucene 倒排索引的查询步骤:
- 通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
- 通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
- 将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
- 存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
- 如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通过 SkipData 快速跳转
4 Lucene 数值类型处理
上述 Terms Dictionary 与 Posting List 的实现都是处理字符串类型的 Term,而对于数值类型,如果采用上述方式实现会存在以下问题:
- 数值潜在的 Term 可能会非常多,比如是浮点数,导致查询效率低
- 无法处理多维数据,比如经纬度
所以 Lucene 为了支持高效的数值类或者多维度查询,引入了 BKDTree。
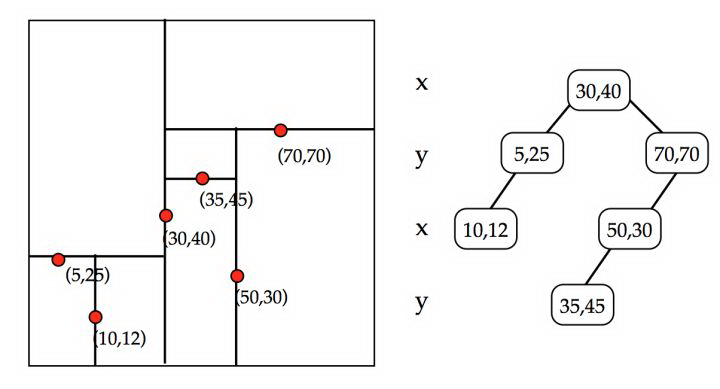
4.1 KDTree
BKDTree 是基于 KDTree,KDTree 实现起来很像是一个二叉查找树。主要的区别是,KDTree 在不同的层使用的是不同的维度值。
下面是一个2维树的样例 ,其第一层以 x 为切分维度,将 x>30的节点传递给右子树,x<30的传递给左子树,第二层再按 y 维度切分,不断迭代到所有数据都被建立到 KD Tree 的节点上为止。
4.2 BKDTree
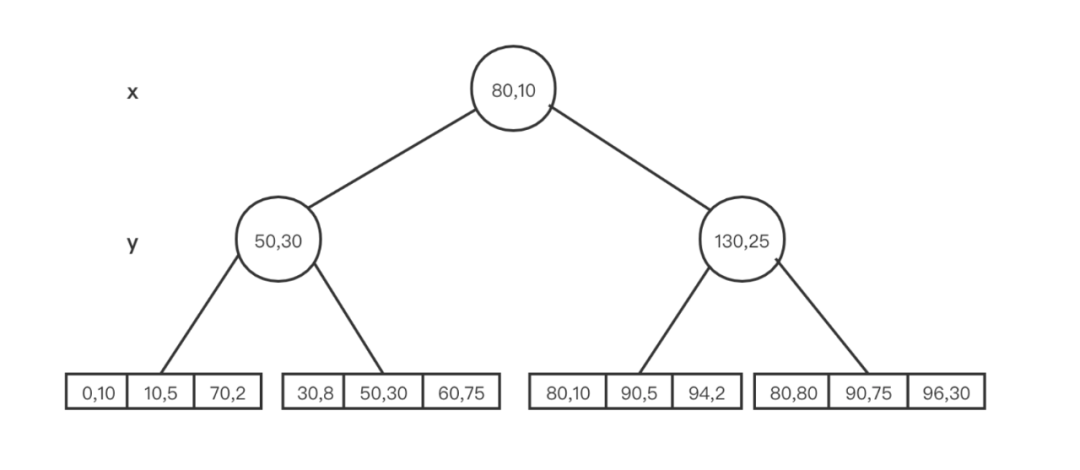
BKD 树是 KD 树和 B+ 树的组合,拥有以下特性:
- 内部 node 必须是一个完全二叉树
- 叶子节点存储点数据,降低层高度,减少磁盘 IO
5 总结
本文先介绍了倒排索引的概念和结构,然后对 Lucene 倒排索引的 Terms Dictionary 和 Posting List 的整体结构以及倒排索引的查询逻辑,最后介绍了 Lucene 对数值类型所做的处理。
倒排索引有效的解决了搜索中的很多问题,而 Lucene 对倒排索引的实现包含了很多巧妙的结构和设计,对数据存储压缩以及查询很有借鉴意义,值得深入学习。
参考资料
Lucene 源码分析: https://www.amazingkoala.com.cn/Lucene/
Lucene BKD 树: https://www.shenyanchao.cn/blog/2018/12/04/lucene-bkd/
Lucene 查询原理及解析 : https://www.infoq.cn/article/ejEG02VRoeGVaLw4j_LL
Lucene 倒排索引探秘: [https://www.6aiq.com/article/1564413040138](https://www.6aiq.
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%8E%BB%E5%93%AA%E5%84%BF%E7%BD%91%E5%80%92%E6%8E%92%E7%B4%A2%E5%BC%95%E5%8E%9F%E7%90%86/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


