医疗健康领域的短文本解析探索三文本纠错
前言
最近在优化 dxy 帖子召回问题,我们之前在 医疗健康领域的短文本解析探索(一) 提到了 phrase mining 抽取粗粒度名词,在 医疗健康领域的短文本解析探索(二) 提到实体链接相关方案,但是用户在输入搜索内容时,很可能因为输入法或者是其他原因导致文本输入错误,最终导致搜索不到用户想要的结果降低用户体验。
在 nlp 领域中文本纠错是个坑,不能说是深坑,也就是个万丈深渊吧…😭,因为目前没有特别成熟的方法,而且用到的知识点比较繁琐,真正的应用到工业界还要考虑实际成本和效率。常见纠错内容如下所示:
- 谐音错别字:耳室症如何治疗?—-耳石症如何治疗?
- 形近错别字:氨基已酸 —-氨基己酸
- 字词顺序错误:硫酸氯氢吡格雷 ---- 硫酸氢氯吡格雷
- 字词补全:右旋糖苷铁口服液 —-右旋糖苷铁口服溶液
- 中文拼写错误:aspl —- 阿司匹林,阿斯 pi ling —-阿司匹林
- 语法错误 (Grammatical Error):Nothing is [absolute—-absolutely] right or wrong
- 常识知识错误:上海同济医院内分泌代谢科主治医师[刘辉—-刘光辉]在搜索中这些确实是常见的几种错误类型,绝大多数是一些用户习惯和输入问题,我在丁香园的搜索日志中经常见到的一些有趣的搜索问题,比方说,用户想搜索阿司匹林,可能输入
aspl,阿斯匹林,阿司匹,阿司匹 lin,阿斯 pi ling等奇奇怪怪的输入。
我们调研一些学术界近期的结果和工业界常规方法。做了以下简单的总结。
正文
《An Improved Graph Model for Chinese Spell Checking 》&&《A Hybrid Model for Chinese Spelling Check》
14 年的一篇文章,实验用到的数据集是 SIGHAN-2013[2],借鉴分词时构建 DAG(Directed Acyclic Graph )的方法,因为错误句子可能会造成错误的分词结果,会导致多种分词情况,对所有切分结果的相似拼音的字/词加入到分词的 DAG 中,构成一个由相似词语组成的新的 DAG 模型。就像下面这个例子,misspelled: “假书抵万金”。其中有一个替换原则,定义一个相似词典,所有的替换按照字典相似的词进行替换。
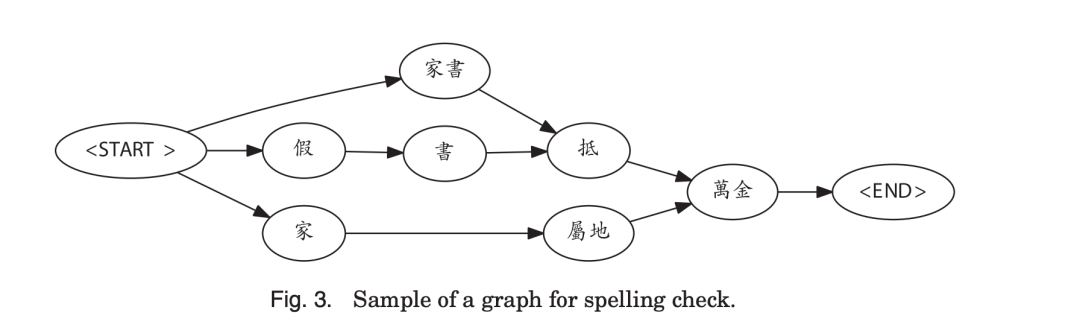
根据新的有向无环图,去找最短路径 Single Source Shortest Path(SSSP),用替换词之后最合理的分词结果,就是 CSC 正确的结果。但是这种方式存在两个小问题,如果说分词的时候如果是单个字,那么进行替换会变的没有意义,或者说,如果是分词之后,分出去的词也是分词词典中已有的词,就不好进行纠错,比方说“我/对/心[里 — 理]/研究/有兴趣”,也就是说如果出错的来源是一个置信度比较高的词语时不好进行纠错,区分“他”和“她”的不同就会相对困难。
因此为解决这一问题,本文加入 crf model 进行预测,再加一些 rule model。虽然这篇文章比较久远,但是这种 Hybrid Model 的方式确实值得借鉴。
《HANSpeller++: A Unified Framework for Chinese Spelling Correction 》
本文提出了一个 HANSpeller 框架进行检测和纠错,这个框架有两个主要的工作,首先对输入的句子生成可能的候选集,再对候选集进行排序,选择最好的结果作为新的句子。
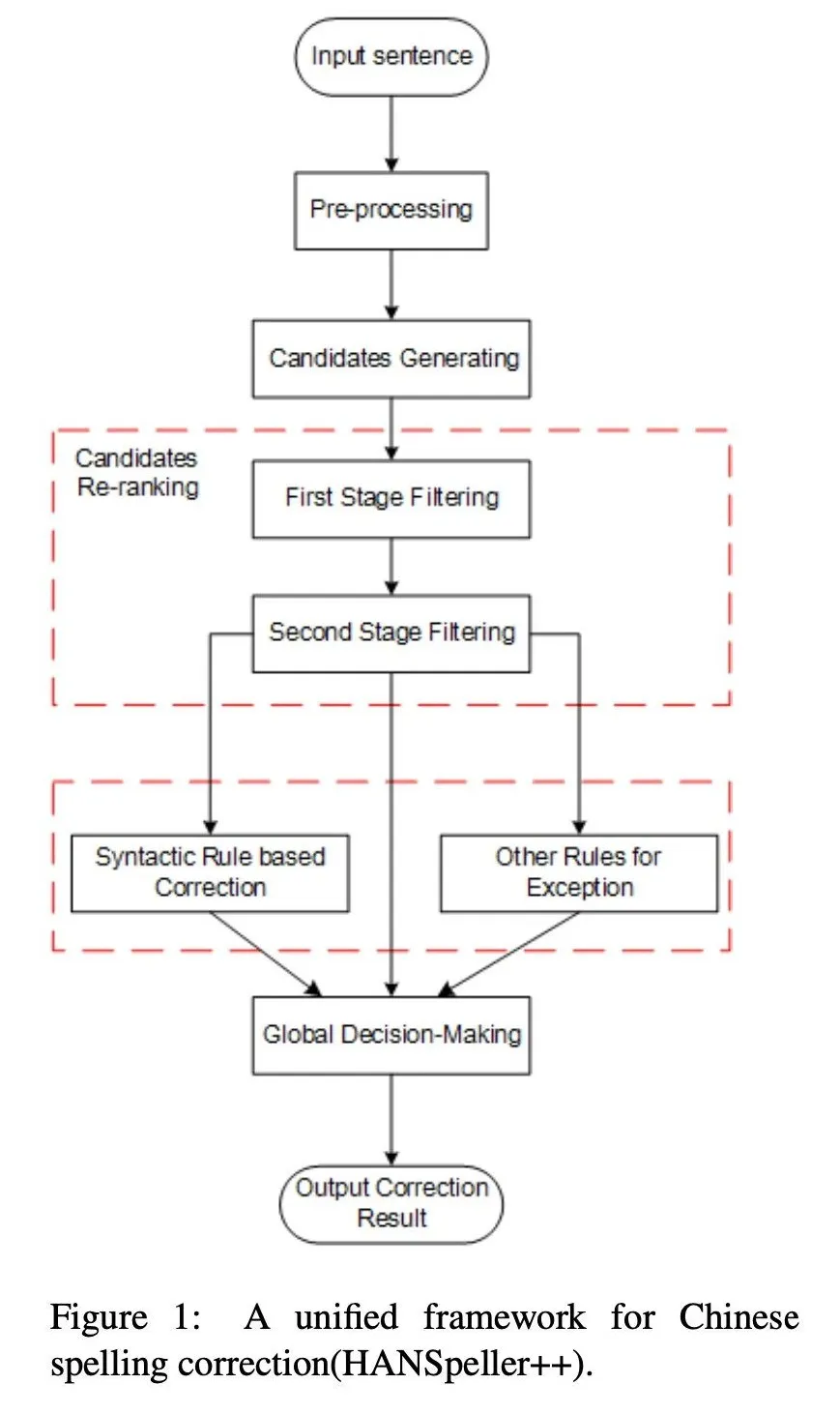
在 data processing 阶段,将长句子根据标点切分为短句并且去掉非汉字内容,根据 SIGHAN-2013,SIGHAN-2014 作为外部数据构建 confusion pair,用于生成候选方案之一。下一步 candidates generating 时根据句子中的字生成有限候选集,根据同音字,近音字,形近字,和一开始生成的 confusion pair 进行替换,因为候选集有限,只保留权重较高的替换词。替换 priority weight 计算公式如下(其中 P(c)为其在 c 这个字符可能出错的概率,edit_dist 编辑距离,二者加权):
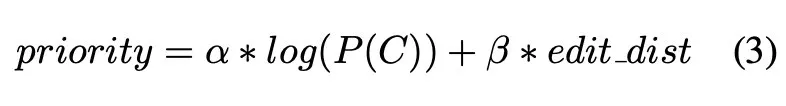
在候选结果 rerank 阶段,分为两次筛选和排序,初筛时用到的特征比较简单,n-gram probability,词典统计特征,编辑距离,和分词特征做逻辑回归分类预测。第二次筛选的时候用外部依赖数据,bing 的搜索结果,英文翻译的结果,并且使用 mi crosoft Web n-gram 服务计算翻译的 n-gram 概率。两次筛选后,保留最有可能的 top5 候选结果。其中一些通用的错误需要加入一些规则进行重新打分。之后用一些规则获取最终结果,比方说 n-gram 的概率做过滤器,不同的相似类型的候选集权重不同,confusion pair 是根据大量标注数据抽取的因此权重高于同音同形等类别,之后再对长句所需要替换的个数进行约束。
这个纠错的方案特征相对比较丰富并且使用 n-gram 保留部分的语义信息做筛选。其相当于枚举出了所有种可能的替换方案,并且根据经过分类器进行初筛,二次筛选和规则排序选择最有可能正确的结果。
《FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm 》产业界最强的简繁中文拼写检查工具
19 年爱奇艺发的文章,通过 DAE(denoising autoencoder) 去 fine tune BERT 的(mask language model)MLM 获取候选结果,用于替代之前提到构建的 confusion set。
在之前的方法中,我们需要自动构建 confusion pair set,还要给定不同来源数据权重。FASPell 利用预训练模型使用 DAE pre-train BERT,mask 句子中每个位置的字符获取候选集,通过上下文置信度信息,和字符相似度构建了一个 confidence-similarity decoder(CSD)去对句子中的每一个字符的候选集进行筛选。如果用过 pycorrector[5]的话,该工具在检测到可能存在错误的字/词之后通过近音词。形近字枚举进行替换,再根据统计字典进行排序,按顺序找最优结果。
FASPell 通过上下文的 confidence score 和字音的 similarity score 联合打分进行过滤,过滤条件:0.8 × confidence + 0.2 × similarity < 0.8 。
某些特定效果场景效果不错 GitHub 上有源码有兴趣的同学可以去试试,我们简单的构建了一批数据,做了一些尝试,效果如下所示:

但是存在一个问题,如果连续的词出现出错,或者说同样是置信度很高的词语,纠错效果不好,就类似于第一篇文章说的“心里—-心理”其 confidence score 同样很高。所以需要在构建数据集的时候需要下一些功夫。
《Spelling Error Correction with Soft-Masked BERT 》
2020 年 ACL 的一篇文章,可以说是改进了原有 BERT 直接获取每个字的候选集的方法,将纠错任务拆分为两部分解决,Detection Network 和 Correction Network,其中 Detection Network 是基于 Bi-GRU 构建的一个二分类模型,用于预测文本出错的概率。Correction Network 则是利用 bert 生成候选集合并打分。
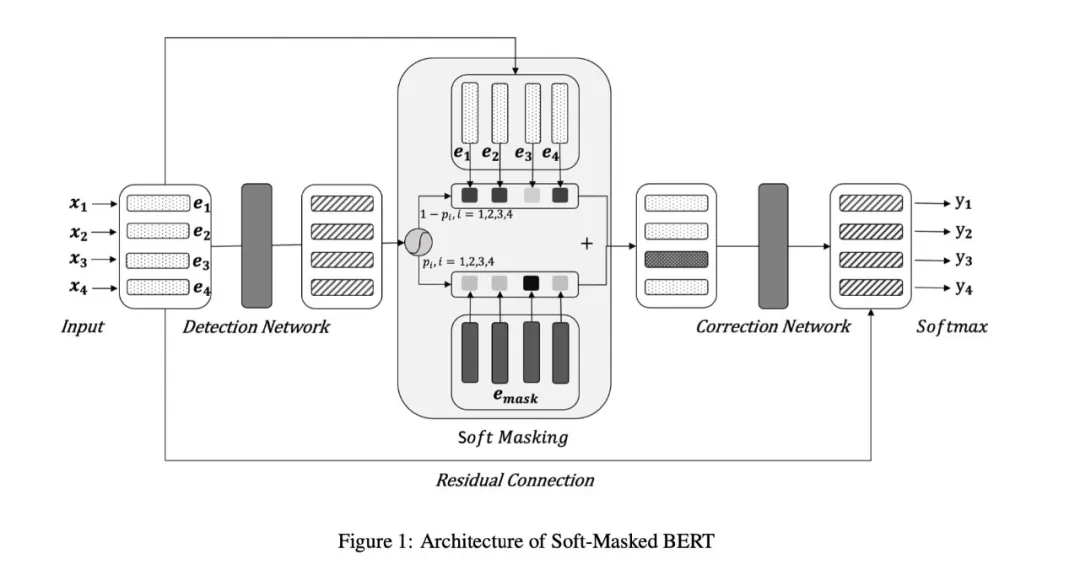
Dectection Network 在后续处理时有一个小细节,二分类获得的概率之后,根据概率对 bert 的 char embedding 和 mask embedding 加权求和传递给 Correction Network。
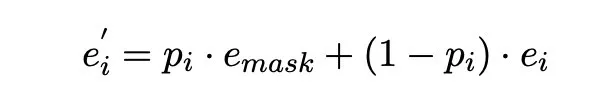
Correction Network 则是一个基于 BERT 的多分类模型,其 input 是检测层向量加权的结果结果。其目标函数由两部分组成,其中λ 是(0,1)之间的超参。
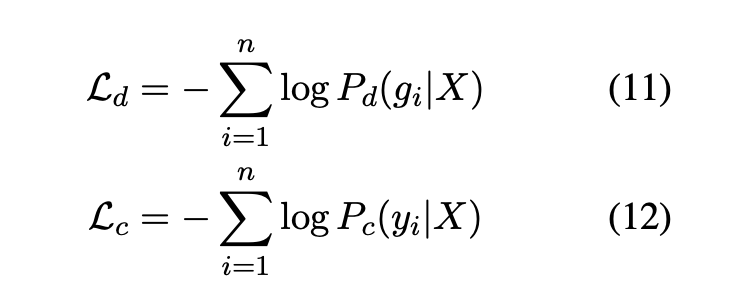
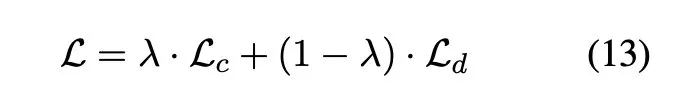
打造垂直领域纠错
在 dxy 垂直搜索中,用户输入 short query 经常会出现一些错误文本,导致可能无法搜索到正确的内容,也可能拿到与用户无关内容,最最常见的错误都是由于输入法带来的拼音错误、形近字,用户习惯带来的谐音错误,内容缺失和内容中有多余字符的错误。那么按照上面论文的方法,我们可以解决形近字和谐音这种同等长度的问题,但是像拼音和内容补全删除问题就不太好办了。而且还有一个问题,纠错文本的标注成本较高,而且做垂直领域纠错最好用该领域文本的标注数据效果最好。
好在我们是做医学垂直领域,那么我们就要利用好我们构建的医学知识图谱,用已有的领域实体帮我们解决这一问题,甚至还可以有效的解决一些用户对常识知识不熟悉带来的一些错误。
流程如下所示:
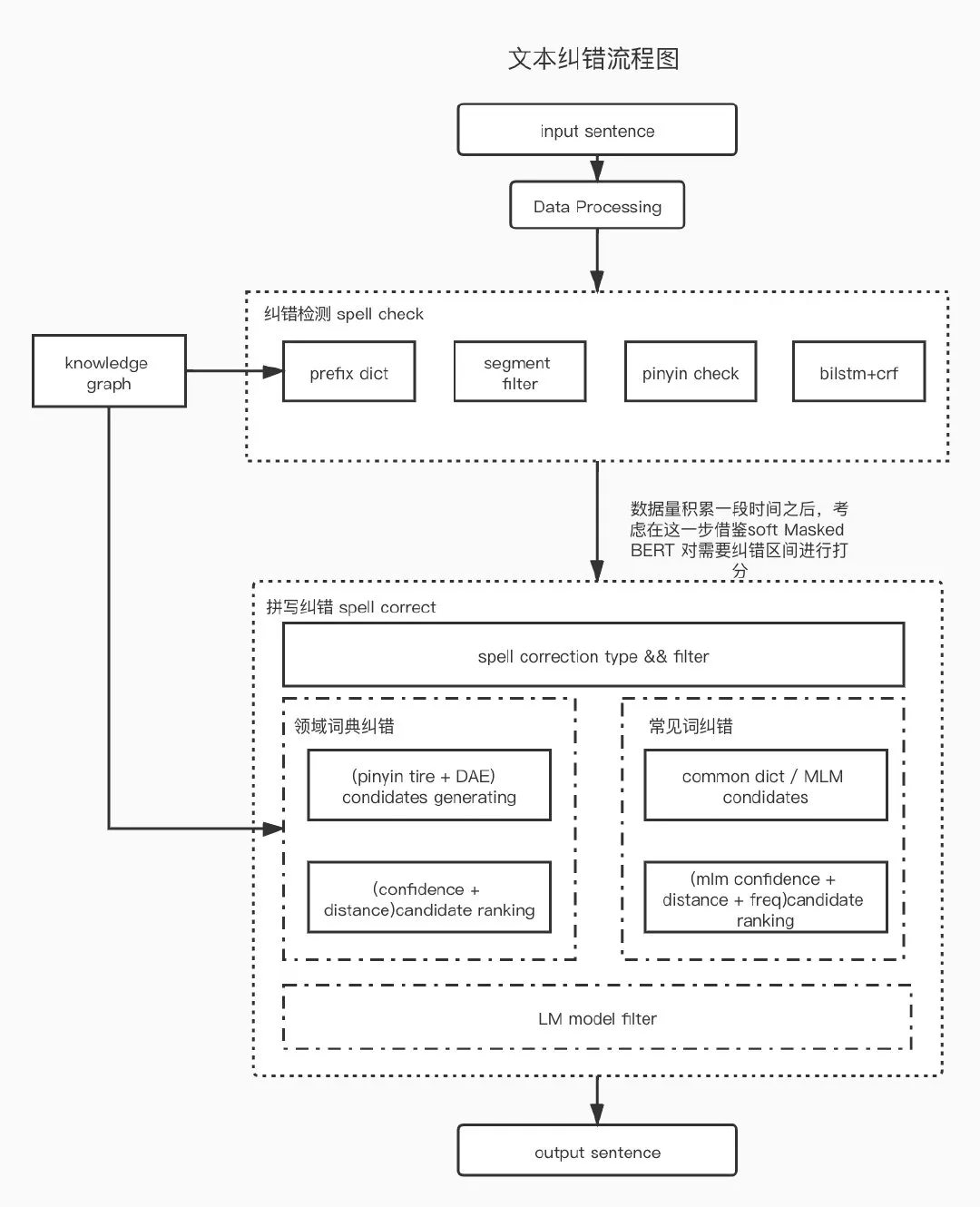
ps. 因为是搜索引擎纠错而非对话系统的纠错,所以我们暂时不用纠结依存句法错误。所以我们将句法问题可以暂时交给搜索中的 Query 扩展技术和搜索引擎。
data processing
首先我们要对输入的句子进行预处理,1.对长句子按照符号进行切分,2.实体链接获取词性和实体关系等信息。对所有的 mention 进行提取。
spell check
拼写检测,我们会从字词两个层面考虑,将可能错误的区间进行标注,prefix dict 根据已有 知识图谱 中的实体信息构建的前缀字典树,尽可能的获取各 mention 的前缀信息。segment filter 用于标注不需要纠错的部分靠谱的实体词/和停用词等。pinyin check 检测输入是否是拼音,或者是否是实体的拼音缩写,并且正确的对拼音进行分割。bilstm+crf 根据用户搜索行为构建了一批需纠错数据集,对需纠错部分进行标注,根据 bilstm+crf 结果进行比对获取错误类型和 可能 需纠错文本。
spell correction
纠错将会从两方面考虑,一方面领域词纠错,另一方面是常用词中字粒度错误。在医疗垂直领域,依赖领域内知识,根据之前构建的知识图谱中的实体构建前缀字典树,并根据搜索日志构建常见的 confusion set,并且基于 DAE 对需纠错词进行向量表示,其中用到了字型,拼音,上下文语义等特征作为输入层,中间隐藏层作为向量表示,根据 embedding simility 生成候选集合,再根据 embedding cosine distance 和 edit distance 进行联合打分进行排序过滤。
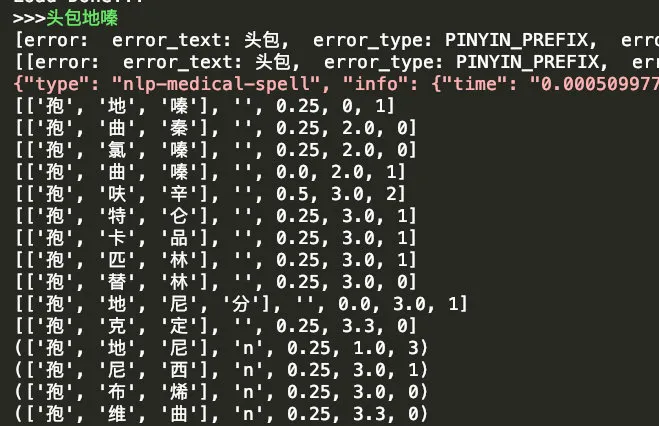
前缀树召回候选集
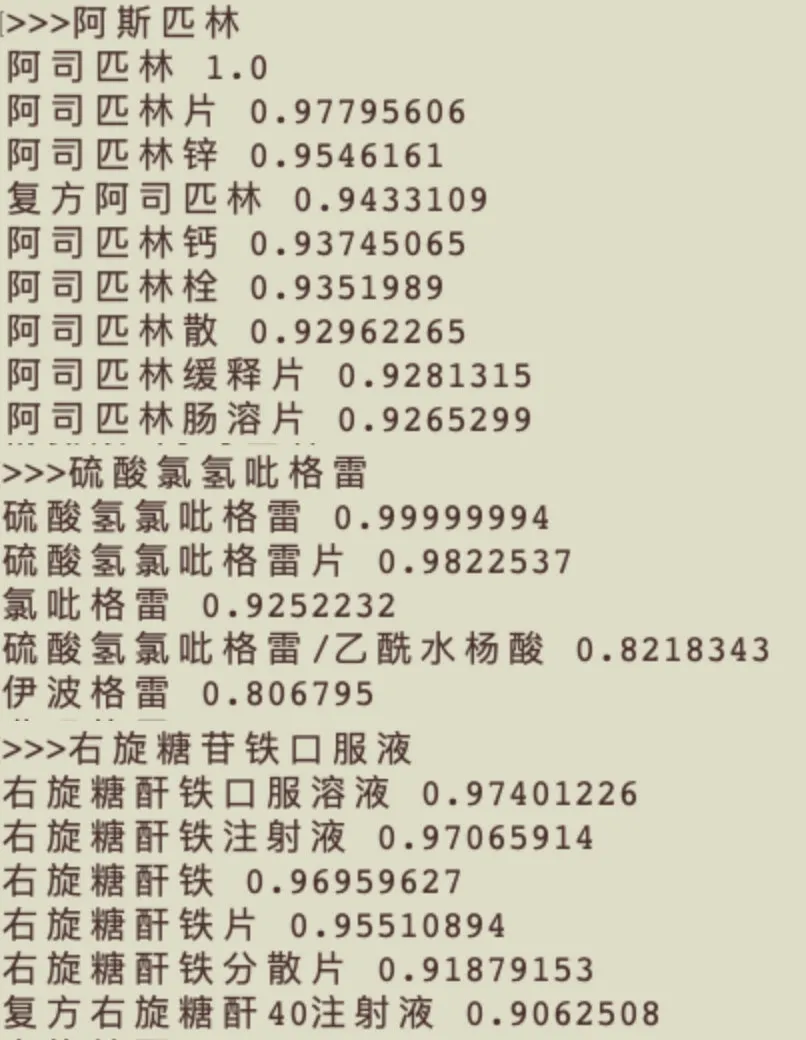
DAE 召回候选集
常用词字粒度的纠错借鉴了上述很多方法进行融合,基于 BERT fine-tune MLM 生成候选,再根据 common dict 构建 n-gram 模型根据字的 confusion set 生成候选。最后将生成的候选集与原句子中的 mention 进行替换,与原句子的 language model 的 preplexity 再一次的比较。
总结
在丁香园医疗垂直领域的文本纠错实验中,我们尝试了各种各样的方法,去解决用户在使用搜索引擎带来的纠错问题。因为是搜索引擎,所以可能用到的纠错方法就相对简单一些,后续如果是用户对话逻辑上的纠错,就要踩更多的坑,比方说上下文内容补全,知识图谱推理纠错,语法纠错等等。
参考文献
[1] pycorrector [https://github.com/shibing624/py
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%8C%BB%E7%96%97%E5%81%A5%E5%BA%B7%E9%A2%86%E5%9F%9F%E7%9A%84%E7%9F%AD%E6%96%87%E6%9C%AC%E8%A7%A3%E6%9E%90%E6%8E%A2%E7%B4%A2%E4%B8%89%E6%96%87%E6%9C%AC%E7%BA%A0%E9%94%99/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


