医疗健康领域的短文本解析探索一
丁香园大数据 NLP 文章发表于: 2019-09-02
前言
简单的回顾一下,上一回我们说到短语挖掘(Phrase Mining),对非结构化文本中抽取出高质量的名词短语,用于解决专业领域的专业词典不足的问题。我们提到了韩家炜老师的三部曲 TopMine,segphrase 和 AutoPhrase,其用到的主要方法是根据词性标注的频繁模式挖掘,根据模版所统计的 PMI,KL 散度等作为特征,进行分类,根据分类的结果进行排序。试了这些方法之后,我们在原有基础上加了一些常用特征,比方说根据之前整理好的一部分实体词构建 n-gram 模型,根据其语言模型的结果构建特征进行分类后,抽取结果得到了一些改善,对边界处理较好,准确率也有所提升。
深入 Phrase Mining
对于结构化文本来说,Phrase Mining 只是第一步,也是最重要的一步,phrase 的准确率越高,其构建知识图谱和属性抽取时的效果越好。其实 Phrase Mining 抽取的特征有两个重要的来源。
- 上下文特征。例如:Is-A pattern,统计上下文共现信息,上下文句法结构等等。
- phrase 内部字或词等特征。例如 one hot encoder,词性标注,词性标注模版频率,统计 PMI 信息,和词/字向量等等。
对于上下文特征来说最简单的方式,使用 high-quality pattern 去匹配[1],韩家炜老师在 17 年提到一篇文章 MetaPAD,详细的阐述了如何利用实体周围丰富的上下文信息,去确定模版边界,和抽取内容。如下图所示:

President Barack Obama’s government of United States reported that… 对于这句话来说,实体替换后 President [&Politician] government of [&Country] reported that -> 抽取模版 [&Politician] government of [&Country] 。大规模文本统计模版信息,根据模版质量函数,对生成模版进行过滤,保留高质量模版[2]。这种模版方式抽取实体的准确率还是比较高的。对于抽取来说,一份高质量的模版可以为我们提供准确的实体信息,而且准确的实体信息和比较好的质量检测方法可以为我们提供一份质量很棒的高质量模版,这是一个 bootstrapping 的过程,不断的迭代不断的获取新的数据。
phrase 内部特征,最简单的使用字词向量的 one-hot encoder,统计 n-gram 信息,其实 phrase 内部特征也或多或少的包含着上下文相关信息,传统的 word2vec,使用 CBOW 和 skip-gram 方式构建,其实就是对当前词或上下文进行预测时隐藏层的权重。Pos-Tag 词性标注,使用上下文相关信息,构建隐马尔可夫模型,对文本进行序列标注,判断词性。其实也完全可以用字的 n-gram 去计算信息熵和 PMI 等信息,例如在 2012 年 Matrix67 提出了《互联网时代的社会语言学:基于 SNS 的文本数据挖掘》计算左右临字信息熵和 PMI 进行新词挖掘时,用到的就是字的统计结果,但是在大量的文本下,字排列组合的结果太多了,当 n 取到 7 的时候信息量和计算量已经异常的大了,所以利用 pos pattern 作为代替字或词的 n-gram 统计,在计算量上还是可以接受的,而这也在 AutoPhrase 和 Segphrase 中见到了一些明显的效果。
举一个上述两种方式在丁香园搜索日志中常见的几个例子:
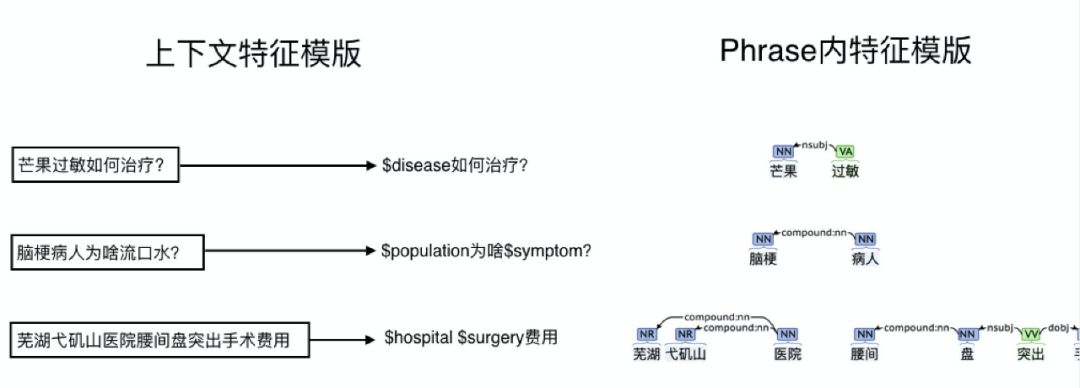
上图可以看到,在做 Phrase Mining 时其实我们考虑的主要是这两方面的特征,一种是模板抽取,一种是内部结构的排列组合。其实这些是很普通的方法,在工业界也取得一个很好的效果,可以在项目初期获得一大批的 high-quality pattern 和 high-quality phrase,关于内部特征的应用我们之后介绍。
实现自动化抽取和评估
在 Segphrase 中提到标注 300 个高质量样本,但是这件事情比较麻烦,原因有两个
- 需要领域知识的专业知识进行标注,由于及其依赖高质量数据因此效率低。
- 高质量这个概念不清晰,所谓的高质量应该指的是尽可能穷尽数据分布下的所有可能,因此比较依赖于特征选取,特征分布和分词等结果。
于是之后 AutoPhrase 使用 wiki 百科的专业领域内的主题词作为外部知识引入进行了优化。
2019 年腾讯发了一篇关于可解释性推荐的论文[3-4],其中提到了使用三种方法构建 Concept Mining System,并实现了自动化抽取和评估的整个过程。
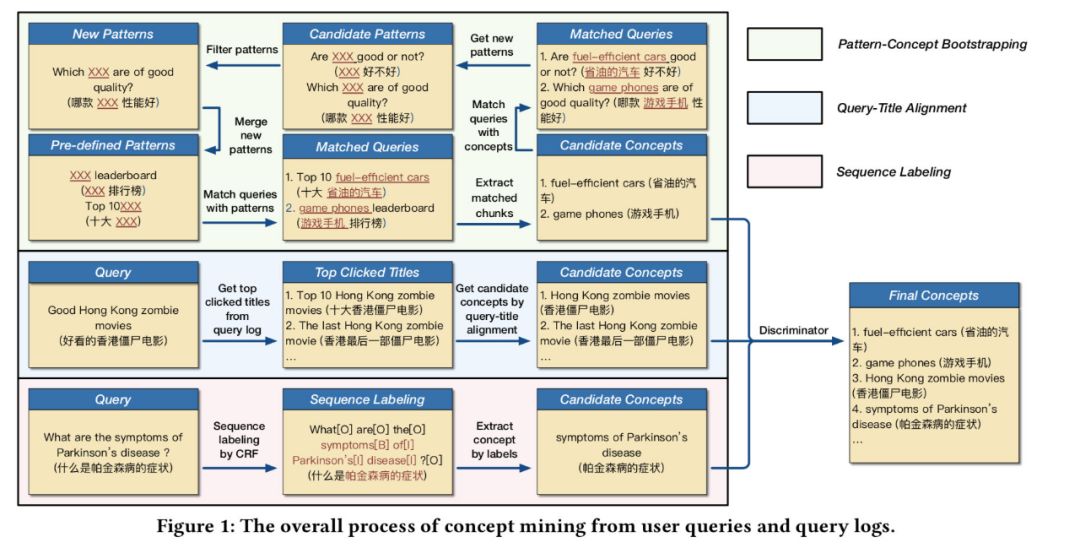
- Bootstrapping:使用一些优质种子模版(Pre-defined/Seed Pattern),对用户 query 和点击帖子的 title 进行抽取,之后过分类器模型,使用构建好的 Discriminator 进行分类,打分,过滤。使用过滤后的 concept 生成新的模版,再对模版进行规则过滤的方式获取高质量模版加入到 Pre-defined Pattern 中之后反复迭代。
- Query Click Ngram:根据用户日志的 query 和所点击帖子的 title,分词后进行 N-gram 抽取 。首先枚举出 query 的所有 N-gram 结果,之后根据 title 的 n-gram 判断 query n-gram 是否被包含于 title n-gram 中,并且 query 于 title 的首末词是否相同。
- Sequence Labeling:序列标注的话,两种方式,如果有一批高质量的标注数据的话,其实完全可以不用分类器这个步骤。前期可以尝试一些远监督的方法构建一批数据,然后加上分类器作为约束,会降低一些召回。
这篇文章的前期构建 Concept Mining System 其实主要是抽取一些上层的概念,如下图所示:
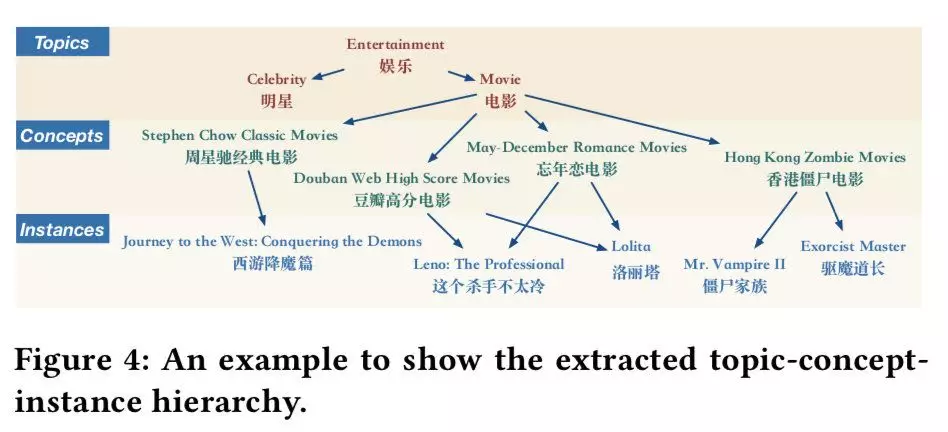
根据出现的概念和搜索的实体进行连接,进行可解释性推荐。这篇论文中对于 Concept Mining System 构建的过程中,起到实现自动化抽取的是 Discriminator 的分类器模型,其中文中说的是使用 300 个样本作为训练数据,并且使用 GBDT 进行分类。
在复现这篇论文时踩了很多坑,最大的坑在于构建这个分类器模型,因为三种不同的抽取方式,抽取的结果会有很大的不同,同时过分类器时会有很多细节上的问题。比方说 N-gram 抽取时给定 N=5,如果 Bootstrapping 抽取的结果 N>5 时怎么办?对于 N-gram 和 Sequence Labeling 来说抽取后的结果也可以将模版抽取出来,那么这个模版是否可以应用到 Bootstrapping 中呢?还有在工业化实现整个抽取系统时,如何节约成本?如何定义 concept,例如:肺炎看似实体,但是在构建层级结构时,获得性肺炎是肺炎的下层实例,而且肺炎的治疗应该属于肺炎的属性,那么肺炎算不算 concept?这些都是在复现这篇论文要考虑的事情。
踩了很多坑,加了一些改进的方案,Concept Mining System 基本复现完成,展示部分抽取结果,其中评分在 0.6 以上的结果还是可以接受的:

这篇论文主要的目的是做一种可解释性的推荐,给帖子一个 concept,感兴趣的同学可以 关注, 收藏, 点赞 😁。后续出 short query understanding 的相关内容时会细说。
刚才我们提到一个 phrase 内部特征这个概念,那么这个应该如何应用呢?举一个简单的例子,在医疗领域中比较棘手的一个概念叫做 症状,症状其实是由一些存在实体类型的原子词构成的,比方说:
症状词:晨起时足部和腿部疼痛明显/symptom
从构成的角度讲,可以将症状进行拆分
晨起时/situation 足部/body 和/conjunction 腿部/body
疼痛/atomsymptom 明显/severity 也就是说,对大的概念的实体词由粗粒度分割为尽可能小的细粒度,并可以根据细粒度结果和一些分割结果的模版重新进行排列组合之后也是一些新的粗粒度的实体词。这么做的好处是什么?一方面可以优化我们对症状的抽取,如果存在新的症状词时,可以很好对应到其作用部位,状态等信息。另一方面,在做实体链接的时候,名词短语会挖掘到一些无属性的新词,比方说 ‘胸骨上部’是库中不存在的实体,在连接的过程中很容易将其连接到 ‘胸骨下裂’ 这个症状词上,这种问题就可以通过原子词分割的方式解决,最简单的方式是使用其内部模版进行比较, 胸骨上部 应该对应到 身体部位, 上部 应该作为 方位词 对原本标签没有影响。再比方说用户检索 心功能检测,巧了数据库里没有这个实体词,只有 肺功能检测,我们推用户 肺功能检测 的信息怕是会被打死,原子化拆分也可以解决这种问题,后面我们细说该如何做。
⚠️前方开始进阶
刚才提到了一些都是工业化的规则方式抽取,在一个从无到有的过程中,这些也算是应该趟一趟的路。当然了如果财大气粗找一批领域内专家,建立一个小目标,先标一个亿的数据,训练一个泛化能力极强的模型肯定是最好的方法(☠️前提标注人员标注的数据质量需要保证。可以理解标注工作繁重枯燥,失常会出现漏判、误判的情况,比如“ 手里剑”被误标注为 手术器械)

18 年华东理工的学生发了一篇结构化电子病历数据的文章[5],其对症状词做了拆分,将症状切分为原子症状、身体部位、中心词等等。这篇文章的内容很简单,主要是使用 POS 特征,使用 Bidirectional LSTM-CRF 进行序列标注的方式进行拆分。数据方面他将症状组合词分为 11 类:
Atomsymptom:症状原子词,不可再分的症状词,比方说:疼痛,酸痛
Body:身体部位词
Head:核心词,一些除身体部位之外的目标词,如血压
Conjunction:连词,和,并,及
Negative:否定词,否,无,非等等
Severity:描述症状的严重程度,轻微,剧烈
Situation:状态词,产后,清晨时
Locative:方位词,上部,后侧,上方等
Sensation:感官词,灼热感,冷等
Feature:特征词,获得性,一过性,I/II 型,中心型等
Modifier:修饰词,下降,上升等文章主要描述对电子病历中的症状进行拆分,使用细粒度拆分的方式结构化电子病历中的症状,模型也是序列标注中通用的模型,在应用方面没有介绍太多信息。
这个组还有一篇文章[6]很有意思,相当于在上篇文章对应用方面做了拓展。使用知识图谱去构建一个症状词的上下位关系,对症状数据标准化。
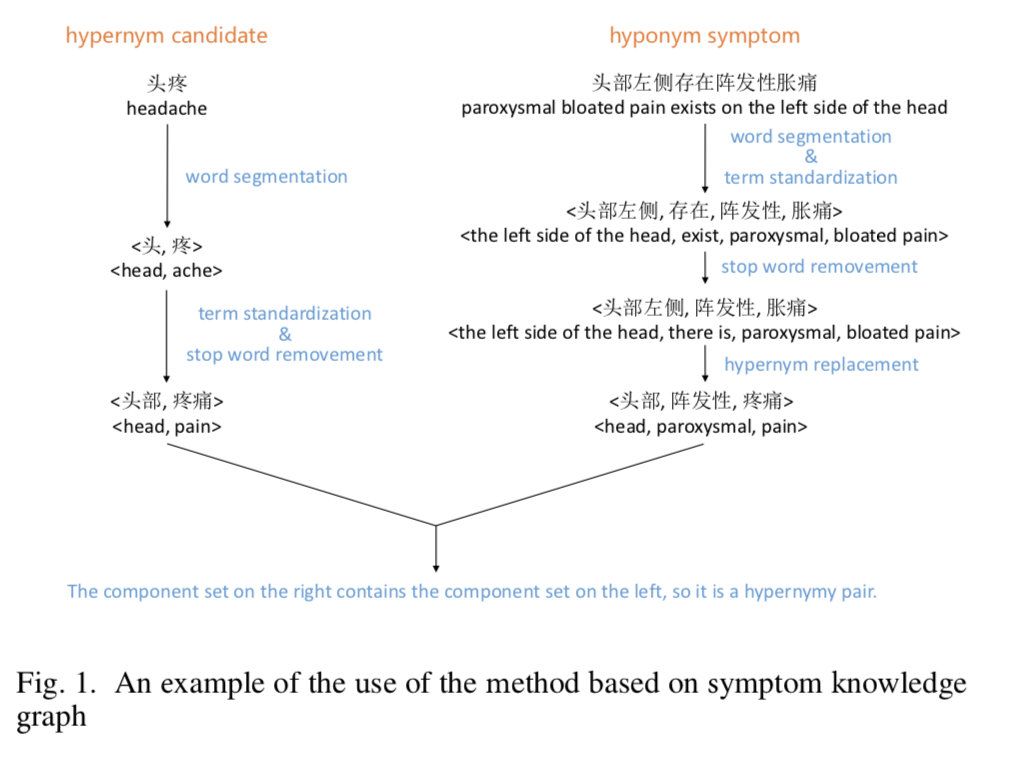
左右两侧分别是两种症状词,首先对左侧候选集进行标准化,其中标准化流程包括,细粒度分割,细粒度标准化替换( 头 替换为 头部),去停用词等操作, 头疼 标准化为 < 头部,疼痛 >, 头部左侧存在阵发性头疼 可以整理为 < 头部,阵发性,疼痛 >。因为一些包含关系,我们可以将 头疼 作为 头部左侧存在阵发性头疼 的上位词。这里用到的细粒度类型只有三种 Atomsymptom,Body,Head。其实这篇文章好的一点是可以在做实体链接的时候对发现的新症状词进行实体对齐提供一个方案,如果是库中不存在的词,我们也可以根据其上位词进行推断用户意图。使用切分的方式有效的将数据细粒度结构化,构建知识图谱上下位关系进行存储和推理。这种方法也可以有效的帮我们解决刚才提到的 胸骨上部—> 胸骨上裂 和 心功能检测—> 肺功能检测 这个问题。
简单拓展一下,今年 2019 ACL 刘知远老师团队[7]中提到最小语义单位——》义原(sememe),义原是最基础的不宜在分割的最小语义单位,这篇论文中将 Sememe Knowledge 作为外部知识的方式应用,其证明了义原知识在语义构成实验中的有效性。反观原子词分割这件事情,其实就是一个垂直领域中的最小义原的分割,后续我们有考虑将一些义原知识作为外部特征的方式优化我们的抽取和连接的结果。有兴趣的童鞋也可以看看其 2017 年的一篇使用义原知识进行词的表示学习的文章[8]。
那么既然细粒度分割在理论上是对我们进行实体抽取和实体链接是有益处的,那么让我们愉快的搞事情吧,转身看了看 ner 抽取的几十万的症状……还有几十万的疾病……

细粒度分割是一个长期迭代的过程,需要不断更新,然后不断的优化补全,所以看来没办法一口吃成一个胖子了,但是一些普适化的东西还是可以搞一搞的,比方说根据用户日志的搜索频率找一些高频的症状和疾病,简单拆分一下还是可以进行下去的。
继续 ⚠️踩坑
说到结构化电子病历这件事,其实目前是一个比较细的一个研究方向,刚提到用序列标注,知识图谱构建上下位关系进行标准化。其实还可以用表示学习[9]进行标准化统一。
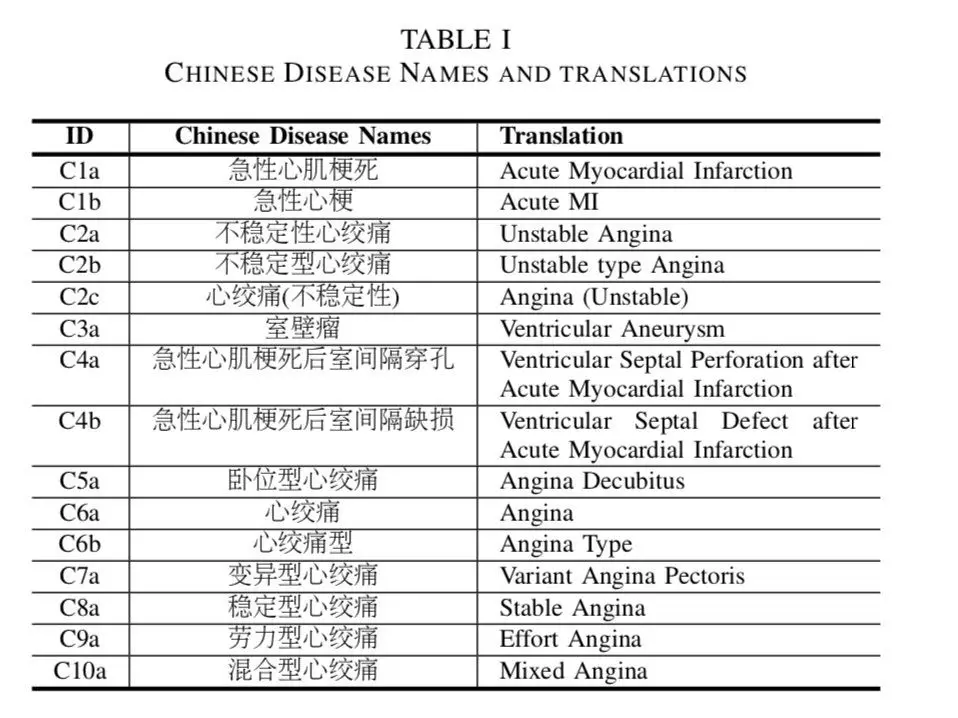
首先需要了解一下 International Classification of Disease 10th revision (ICD-10)这个数据集,此数据集是根据疾病的某些特征,按照规则疾病进行分类,并用编码进行表示。其中收录了大概 2w 多的疾病。如下图所示
18 年 Yizhou Zhang 提出一种 multi-view attention based denoising auto-encoder(MADAE)模型[9]。模型结构如下所示
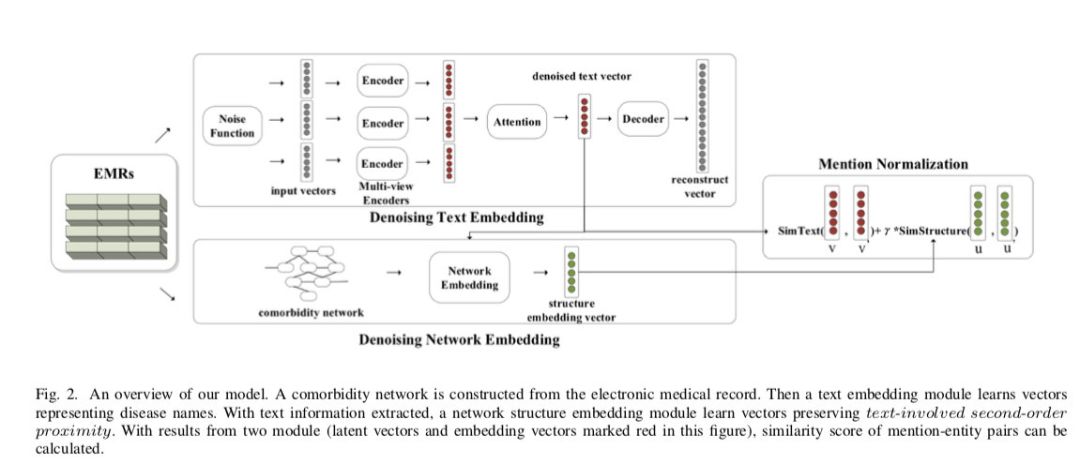
基于一种多视图注意力网络的降噪自编码器进行病历数据的标准化流程。DAE 本身是为了学习到较鲁棒性的特征,在网络的 embedding 层引入随机噪声,可以说是破坏了输入数据并重构出了原始数据,所以其训练出来的特征会更鲁棒,Multi-view encoders 根据加入噪音后的原始文本进行 embedding,根据其词,字,音三种向量表示结果过一层 attention 再 decoder 回到最初的输入数据 。与之前提到的拆分标准化方法不同,如下图所示:
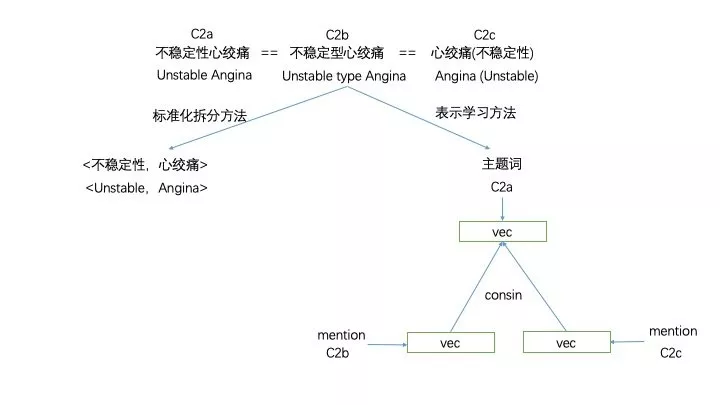
对于 C2a,C2b,C2c 来说我们可以使用标准化拆分的方式,将其拆分为 < 不稳定性,心绞痛 >,之后可以推出 C2a,C2b,C2c 在描述同一个内容。而在 MADAE 模型中其实是以一个为标准,比方说 C2a 为库中关于 不稳定性心绞痛 标准的写法,而 C2b,C2c 可以说是其别名或 mention。我们使用 MADAE 模型的 encoder 层输出的向量结果与知识库中所保存标准化写法进行相似度计算,就可以解决一些同音字和写法结构上的不统一的问题,再按照 Denoising Network Emdedding 中根据 co-occur 统计上下文信息,对 Denoising Text Embedding 进行相似度加权的方式,我们也可以找出一些同义词。Denoising Text Embedding 的方法的结果:
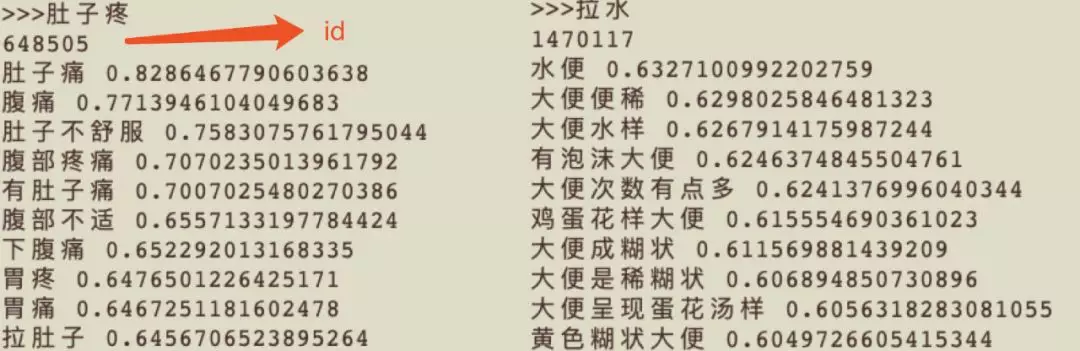
这么做的优点是,首先我们数据库中不用存储太多的节点信息。可以将图的节点信息减少,节省了部分空间,并且我们可以使用这种方式挖掘同义词。

如果 ner、phrase mining 等等挖掘出了与数据库中无法完全匹配的新词时我们可以摒弃那种用于字层面的相似度计算方法,例如 bm25、编辑距离
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%8C%BB%E7%96%97%E5%81%A5%E5%BA%B7%E9%A2%86%E5%9F%9F%E7%9A%84%E7%9F%AD%E6%96%87%E6%9C%AC%E8%A7%A3%E6%9E%90%E6%8E%A2%E7%B4%A2%E4%B8%80/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


