关于数据驱动的重新思考
作者:Cassie Kozyrkov
编译:ronghuaiyang
转载自: AI公园
这篇文章介绍了大多数人缺乏的心理习惯,以及为什么你不能指望没有数据就能有效地指导你的行为。
企业正在大量雇佣数据科学家,以做出严格、科学、公正、数据驱动的决策。
现在,坏消息来了:这些决定通常不是。
要想做出数据驱动的决策,就必须是数据(而不是其他东西)驱动它。看起来很简单,但在实践中却很少见,因为决策者缺乏关键的心理习惯。
数据驱动不存在了
想象一下,你正在考虑在网上买东西,而不是跑很远去店里买东西。你把你的决定归结为你是否信任网上的卖家。进行快速的搜索会得到一些相关的数据:你会看到卖家的平均评分是4.2,总分是5分。
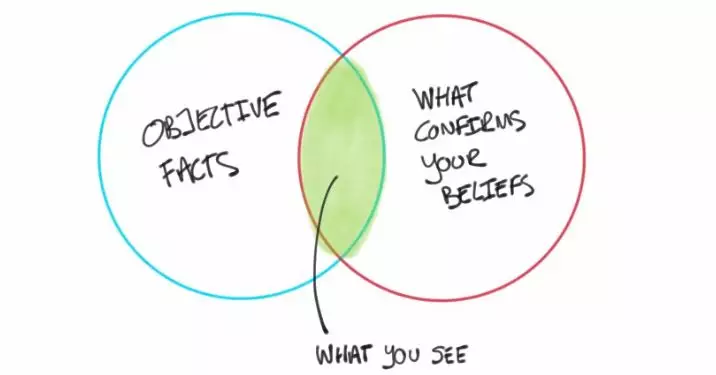
如果没有决策基础,你的决策最多只会受到数据的启发,而不是数据的驱动
你不能用这个4.2分来驱动你的决定。一旦我们看到了答案,我们就可以自由地选择最方便的问题。如果我们做的第一件事是在数据中摸索,那么我们的决策充其量也就是我喜欢称之为“数据启发”的决策。
数据启发
这就是我们,就像鲸鱼遇到浮游生物一样,在一些地方游来游去,然后到达情感的临界点,然后……做出决定。有一些数据接近我们的决定,但这些数据并不能推动它。这个决定完全来自其他地方。

决策者在数据出现之前就已经下定决心了,所以决策一直都在那里。事实证明,人类会选择性地与数据互动,以确认我们内心深处已经做出的选择。我们会在最方便的地方来观察证据,但我们并不总是知道自己在做什么。心理学家对此有一个可爱的名字: 确认偏差。
许多人只是利用数据来让他们对已经做出的决定感觉更好。
用问题去拟合答案
5分得到4.2分好不好呢?这取决于你无意识的偏见。一个真正想在网上购物的决策者会眯着眼睛看4.2,然后高兴地唱出这个数字有多高。“已经超过4.0了!”他们甚至可以给出一个严格的分析,说明它在统计上是如何显著高于4.0的。(确定!它是你一直想要的p-value。)与此同时,如果有人真的不想买这个东西,他会找到另一种方式来回答这个问题:“我为什么要满足于一个评级低于4.5星的卖家?”或者“但看看那些一星评论。”我不喜欢有这么多。“听起来是不是很熟悉?
分割数据的方法越多,你的分析就越容易滋生确认偏差。
数学的复杂性并不能提供解决方案,它只会使问题更难被发现。结果,在我们刚刚看到的这个简单示例中显而易见的东西被隐藏在一堆漂亮的Gaussians分布中。不要假设你友好的邻居数据科学家也看到了它。分割数据的方法越多,你的分析就越容易滋生确认偏差。
结果呢?决策者最终会使用数据来让自己对无论如何要做的事情感觉更好。
昂贵的习惯
当分析复杂或数据难以处理时,一些悲剧就会出现。有时候,一群数据科学家和工程师花了几个月的时间才把一切归结为4.2这个数字。在一段艰苦的旅程结束时,数据科学团队成功地给出了结果:4.2分,5分为满分!计算得很细致。这个团队夜以继日地工作,周末按时完成任务。
利益相关者如何处理它?是的,和我们之前的4.2一样:通过他们的确认偏差眼镜来观察,对真实世界的行为没有影响。它是否准确并不重要——如果所有那些糟糕的数据科学家只是编造了一些数字,那就没有什么不同了。
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


