伴鱼技术机器学习预测服务设计篇
作者: 陈易生
原文: https://tech.ipalfish.com/blog/2021/08/24/palfish-prediction-service-design/
前言
在伴鱼,我们在多个在线场景使用机器学习提升用户的使用体验。例如,在伴鱼绘本中,我们根据用户的帖子浏览记录,为用户推荐他们感兴趣的帖子。
在线预测是机器学习模型发挥作用的临门一脚,重要性不言而喻。在伴鱼,我们搭建了机器学习预测服务(以下简称预测服务),统一地处理所有的预测请求。本文主要介绍预测服务的演进过程。
预测服务 V1
目前,各个算法团队都有一套组装预测服务的方式。它们的架构十分相似,可以用下图表达:
- 业务服务从特征系统获取特征,从 AB 平台获取实验分组。
- 等待获取结果。
- 业务服务将模型 ID 和特征向量发送给 ModelServer。
- ModelServer 根据模型 ID 和特征向量完成推理,将推理结果返回。
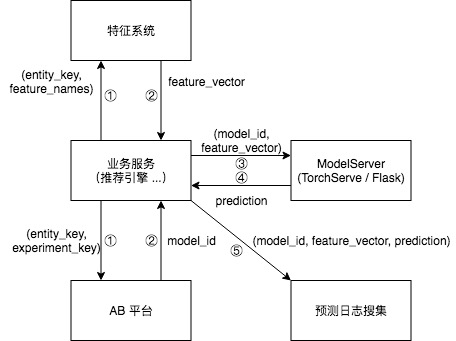
其中,ModelServer 的实现有两种主流方式。其一,使用 TorchServe 或 TensorFlow Serving 这样和训练框架高度耦合的 serving 方案。其二,使用 Flask 搭建一个简单的 HTTP 服务,将模型加载至服务的内存,在收到预测请求时调用模型的预测接口进行预测。
这种方式存在几个问题:
- 性能与多框架支持难以兼得。使用 TorchServe 或 TensorFlow Serving 能保证性能,但不能提供多框架支持;而使用 Flask 搭建预测服务,尽管可以支持任意框架训练出来的模型,但服务性能偏差。其结果是,对于不同类型的模型(LightGBM vs PyTorch),架构非常不同(Flask vs TorchServe)。
- 上线模型需要工程同学的配合。每个需要 ML 能力的业务服务,都需要在算法和工程同学的紧密合作下,学习、实现和维护一套与多个 ML 系统(例如特征系统和 AB 平台)对接的逻辑。
- 不规范。不基于 Go 预测服务难以接入公司自建的服务治理体系和可观测性体系。
为了系统性地解决这几个问题,预测服务 V2 提出了几个设计目的:
- 高性能。预测服务用于线上场景,要满足低延迟和高吞吐的需求。
- 多框架支持。我们的模型包括树和神经网络,至少涉及 LightGBM / XGBoost 和 PyTorch / TensorFlow 这两类框架。预测服务需要支持多种框架的模型。
- 配置化。算法工程师通过配置文件声明预测的工作流,无需业务的工程同学额外配合。要想对接更多 ML 子系统,只需由 AI 平台实现一次,所有算法团队都能受益,无需不同业务线的工程同学反复实现对接逻辑。
- 合规范。可以接入公司成熟的服务治理和可观测性体系。
预测服务 V2
架构主要借鉴了 Uber 和 DoorDash:预测服务接受预测请求,根据请求的内容,进行获取特征、获取 AB 实验分组等操作,然后调用 ModelServer 进行推理,返回预测结果。详情见下图。
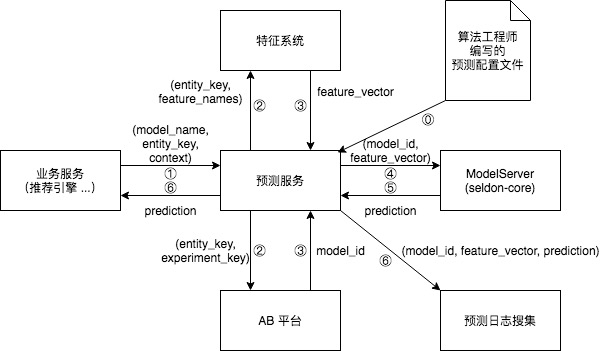
⓪ 表示在新的模型上线之前,算法工程师上传的预测配置文件会被载入预测服务,预测服务根据配置文件的内容实例化一个工作流。
① 到 ⑥ 代表预测请求的整个生命周期:
- 业务服务(例如推荐引擎)调用预测服务的接口,需要提供模型名字、预测主体的 key(例如用户 ID)、上下文(context)特征。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BC%B4%E9%B1%BC%E6%8A%80%E6%9C%AF%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E9%A2%84%E6%B5%8B%E6%9C%8D%E5%8A%A1%E8%AE%BE%E8%AE%A1%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


