以论文学习如何在推荐场景应用强化学习
作者:吴海波 蘑菇街
整理:Hoh Xil
来源:误入机器学习的码农@知乎专栏
导读: 近期,业界开始流传 YouTube 成功将 RL 应用在了推荐场景,并且是 YouTube 近几年来取得的最显著的线上收益。
放出了两篇论文:
[1] Top-K Off-Policy Correction for a REINFORCE Recommender System
https://arxiv.org/pdf/1812.02353.pdf
[2] Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology
https://arxiv.org/pdf/1905.12767.pdf
个人建议两篇论文都仔细读读,TopK 的篇幅较短,重点突出,比较容易理解,但细节上 SlateQ 这篇更多,对比着看更容易理解。而且,特别有意思的是,这两篇论文都说有效果,但是用的方法却不同,一个是 off-policy,一个是 value-base,用 on-policy。很像大公司要做,把主流的几种路线让不同的组都做一遍,谁效果好谁上。个人更喜欢第二篇一些,会有更多的公式细节和工程实践的方案。
很多做个性化推荐的同学,并没有很多强化学习的背景,而 RL 又是一门体系繁杂的学科,和推荐中常用的 supervised learning 有一些区别,入门相对会困难一些。本文将尝试根据这两篇有工业界背景的论文,来解答下 RL 在推荐场景解决什么问题,又会遇到什么困难,我们入门需要学习一些哪些相关的知识点。本文针对有一定机器学习背景,但对 RL 领域并不熟悉的童鞋。
本文的重点如下:
-
目前推荐的问题是什么
-
RL 在推荐场景的挑战及解决方案
-
常见的套路是哪些
▌推荐系统目前的问题
目前主流的个性化推荐技术的问题,突出的大概有以下几点:
-
优化的目标都是 short term reward,比如点击率、观看时长,很难对 long term reward 建模。
-
最主要的是预测用户的兴趣,但模型都是基于 logged feedback 训练,样本和特征极度稀疏,大量的物料没有充分展示过,同时还是有大量的新物料和新用户涌入,存在大量的 bias。另外,用户的兴趣变化剧烈,行为多样性,存在很多 Noise。
-
pigeon-hole:在短期目标下,容易不停的给用户推荐已有的偏好。在另一面,当新用户或者无行为用户来的时候,会更倾向于用大爆款去承接。
▌RL应用在推荐的挑战
看 slide ( 见参考资料 [3] )
-
extremely large action space:many millions of items to recommend. 如果要考虑真实场景是给用户看一屏的物料,则更夸张,是一个排列组合问题。
-
由于是动态环境,无法确认给用户看一个没有看过的物料,用户的反馈会是什么,所以无法有效模拟,训练难度增加。
-
本质上都要预估 user latent state,但存在大量的 unobersever 样本和 noise,预估很困难,这个问题在RL和其他场景中共存。
-
long term reward 难以建模,且 long/short term reward。tradeoff due to user state estimate error。
▌旅程开始
熟悉一个新领域,最有效率的做法是和熟悉的领域做结合。接下来,让我们先简单看下 RL 的基本知识点,然后从 label、objective、optimization、evaluation 来切入吧。
1. RL 的基本知识
有一些基本的 RL 知识,我们得先了解一下,首先是场景的四元组结构:
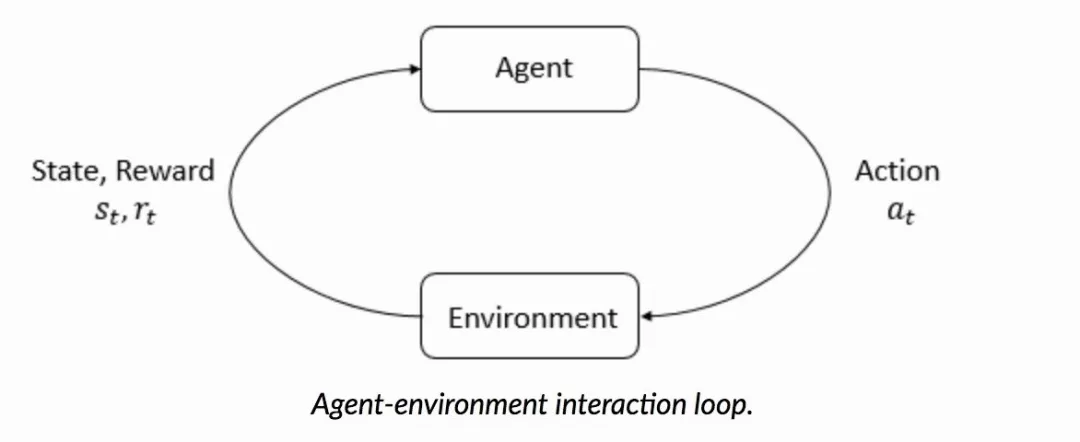
RL 最大的特点是和环境的交互,是一种 trial-error 的过程,通常我们会用 MDP 来描述整个过程,结合推荐场景,四元组数学定义如下:
-
S: a continuous state space describing the user states;
-
A: a discrete action space, containing items available for recommendation;
-
P : S × A × S → R is the state transition probability;
-
R : S × A → R is the reward function, where r(s, a) is the immediate reward obtained by performing action a at user state s.
2. RL 在推荐场景的 Label 特点
众所周知,RL 是典型的需要海量数据的场景,比如著名的 AlphaGo 采用了左右互博的方式来弥补训练数据不足的问题。但是在推荐场景,用户和系统的交互是动态的,即无法模拟。举个例子,你不知道把一个没有推荐过的商品 a 给用户,用户会有什么反馈。
① 老生常谈 Bias
好在推荐场景的样本收集成本低,量级比较大,但问题是存在较为严重的 Bias。即只有被系统展示过的物料才有反馈,而且,还会有源源不断的新物料和用户加入。很多公司会采用 EE ( Explore & Exploit ) 的方式去解决,有些童鞋表示 EE 是天问,这个点不能说错,更多的是太从技术角度考虑问题了。
EE 要解决的是生态问题,必然是要和业务形态结合在一起,比如知乎的内容自荐(虽然效果是呵呵的)。这个点估计我们公司是 EE 应用的很成功的一个了,前阵子居然在供应商口中听到了准确的 EE 描述,震惊于我们的业务同学平时都和他们聊什么。
② off-policy vs on-policy
论文 [1] 则采取 off-policy 的方式来缓解。off-policy 的特点是,使用了两个 policy,一个是用户 behavior 的 β,代表产生用户行为 Trajectory:(s0,A0,s1, · · · ) 的策略,另一个是系统决策的 π,代表系统是如何在面对用户 a 在状态 s 下选择某个 action 的。
RL 中还有 on-policy 的方法,和 off-policy 的区别在于更新 Q 值的时候是沿用既定策略还是用新策略。更好的解释参考这里:
https://www.zhihu.com/question/57159315
③ importance weight
off-policy 的好处是一定程度上带了 exploration,但也带来了问题:
In particular, the fact that we collect data with a periodicity of several hours and compute many policy parameter updates before deploying a new version of the policy in production implies that the set of trajectories we employ to estimate the policy gradient is generated by a different policy. Moreover, we learn from batched feedback collected by other recommenders as well, which follow drastically different policies. A naive policy gradient estimator is no longer unbiased as the gradient in Equation (2) requires sampling trajectories from the updated policy πθ while the trajectories we collected were drawn from a combination of historical policies β.
常见的是引入 importance weighting 来解决。看下公式:
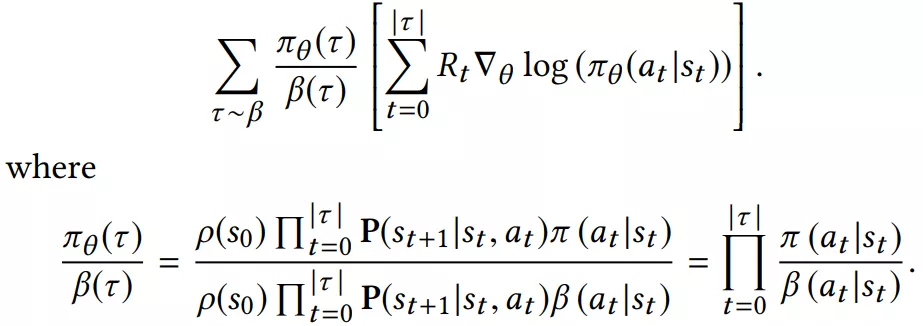
从公式看,和标准的 objective 比,多了一个因子,因为这个因子是连乘和 rnn 的问题类似,梯度容易爆炸或消失。论文中用了一个近似解,并有人证明了是 ok 的。
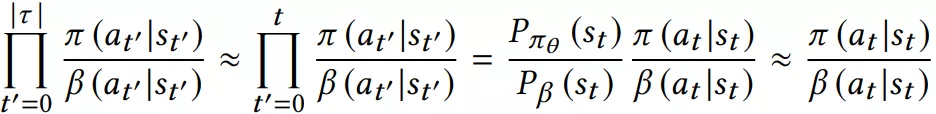
3. RL 在推荐场景的 Objective 特点
在前文中,我们提到,现有的推荐技术,大多是在优化短期目标,比如点击率、停留时长等,用户的反馈是实时的。用户的反馈时长越长,越难优化,比如成交 gmv 就比 ctr 难。
同时也说明,RL 可能在这种场景更有优势。看下 objective 的形式表达:

可以发现,最大的特点是前面有个累加符号。这也意味着,RL 可以支持和用户多轮交互,也可以优化长期目标。这个特点,也是最吸引做个性化推荐的同学,大家想象下自已在使用一些个性化产品的时候,是不是天然就在做多轮交互。
轮到 Bellman 公式上场了,先看下核心思想:
The value of your starting point is the reward you expect to get from being there, plus the value of wherever you land next.
看下公式,注意它包含了时间,有助于理解:
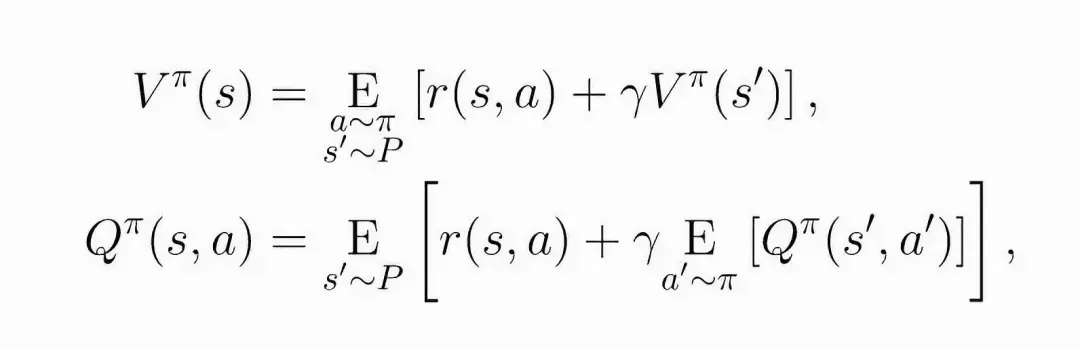
在论文 [2] 中,有更多关于 bellman 在 loss 中推导的细节。由于论文 [1] 采用的 policy-gradient 的优化策略,我们需要得到 loss 的梯度:
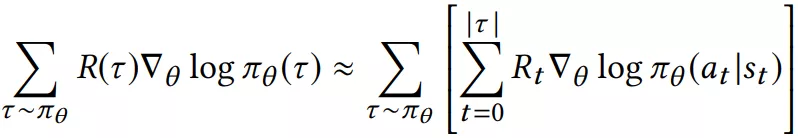
加入 importance weighting 和一些 correction 后:
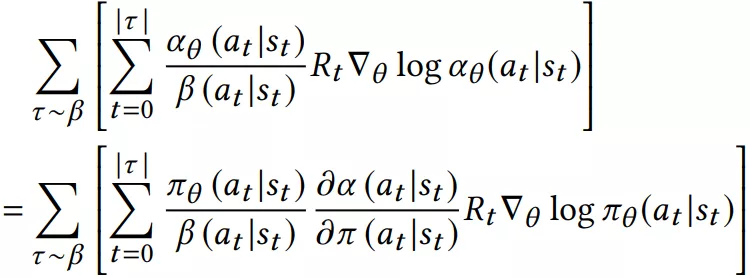
更多细节可以去参考论文。
4. optimization 和 evaluation
通常,RL 可以分成两种,value-base 和 policy-base,虽然不是完全以 optimial 的角度看,但两种套路的优化方法有较大的区别。其中 value-base 虽然直观容易理解,但一直被质疑不能稳定的收敛。
they are known to be prone to instability with function approximation.
而 policy-base 则有较好的收敛性质,所以在很多推荐场景的 RL 应用,大部分会选择 policy-base。当然现在也很有很多二者融合的策略,比如 A3C、DDPG 这种,也是比较流行的。
怎么训练 β 和 π?
π 的训练是比较常规的,有意思的是 β 的学习。用户的 behavior 是很难建模的,我们还是用 nn 的方式去学一个出来,这里有一个单独的分支去预估 β,和 π 是一个网络,但是它的梯度不回传,如下图:
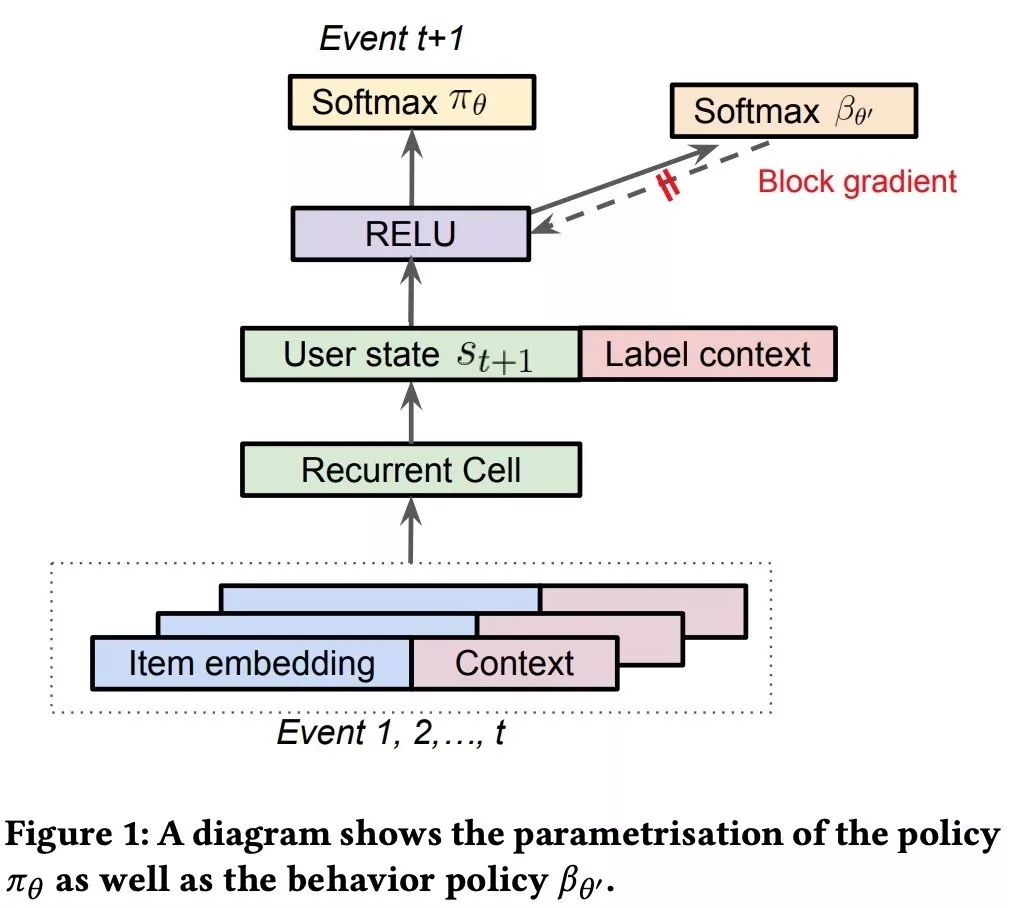
这样就不会干扰 π。二者的区别如下:
(1) While the main policy πθ is effectively trained using a weighted softmax to take into account of long term reward, the behavior policy head βθ′ is trained using only the state-action pairs;
(2) While the main policy head πθ is trained using only items on the trajectory with non-zero reward 3, the behavior policy βθ′ is trained using all of the items on the trajectory to avoid introducing bias in the β estimate.
为何要把 evaluation 拿出来讲呢?通常,我们线下看 AUC,线上直接看 abtest 的效果。本来我比较期待论文中关于长期目标的设计,不过论文 [1] 作者的方式还是比较简单,可借鉴的不多:
The immediate reward r is designed to reflect different user activities; videos that are recommended but not clicked receive zero reward. The long term reward R is aggregated over a time horizon of 4–10 hours.
论文 [2] 中没有细讲。
两篇论文中还有很大的篇幅来讲 Simulation 下的结果,[1] 的目的是为了证明作者提出的 correction 和 topK 的作用,做解释性分析挺好的,[2] 做了下算法对比,并且验证了对 user choice model 鲁棒,但我觉得对实践帮助不大。
▌One more thing:TopK 在解决什么问题?
1. listwise 的问题
主流的个性化推荐应用,都是一次性给用户看一屏的物料,即给出的是一个列表。而目前主流的个性化技术,以 ctr 预估为例,主要集中在预估单个物料的 ctr,和真实场景有一定的 gap。当然,了解过 learning to rank 的同学,早就听过 pointwise、pairwise、listwise,其中 listwise 就是在解决这个问题。
通常,listwise 的 loss 并不容易优化,复杂度较高。据我所知,真正在实践中应用是不多的。RL 在推荐场景,也会遇到相同的问题。但直接做 list 推荐是不现实的,假设我们一次推荐 K 个物料,总共有 N 个物料,那么我们能选择的 action 就是一个排列组合问题,C_N_K * K! 个,当 N 是百万级时,量级非常夸张。
这种情况下,如果不做些假设,问题基本就没有可能在现实中求解了。
YouTube 的两篇论文,都将问题从 listwise ( 他们叫 slatewise ) 转化成了 itemwise。但这个 itemwise 和我们常规理解的 pointwise 的个性化技术还是有区别的。在于这个 wise 是 reward 上的表达,同时要引申出 user choice model。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BB%A5%E8%AE%BA%E6%96%87%E5%AD%A6%E4%B9%A0%E5%A6%82%E4%BD%95%E5%9C%A8%E6%8E%A8%E8%8D%90%E5%9C%BA%E6%99%AF%E5%BA%94%E7%94%A8%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


