从损失函数的角度详解机器学习算法之逻辑回归
源 | 机器学习算法全栈工程师 ID:Jeemy110 作者:章华燕
逻辑回归详解
分类是监督学习的一个核心问题,在监督学习中,当输出变量Y取有限个离散值时,预测问题便成为分类问题。这时,输入变量X可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型或分类决策函数,称为分类器(classifier)。分类器对新的输入进行输出的预测(prediction),称为分类(classification)。
统计学习方法都是由模型,策略,和算法构成的,即统计学习方法由三要素构成,可以简单表示为:
方法 = 模型 + 策略 + 算法
对于logistic回归来说,模型自然就是logistic回归,策略最常用的方法是用一个损失函数(loss function)或代价函数(cost function)来度量预测错误程度,算法则是求解过程,后期会详细描述相关的优化算法。
01 逻辑回归简介
逻辑回归在某些书中也被称为对数几率回归,明明被叫做回归,却用在了分类问题上,我个人认为这是因为逻辑回归用了和回归类似的方法来解决了分类问题。
假设有一个二分类问题,输出为y∈{0,1},而线性回归模型产生的预测值为 z=w^T x+b 是实数值,我们希望有一个理想的阶跃函数来帮我们实现z值到0/1值的转化:
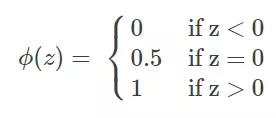
然而该函数不连续,我们希望有一个单调可微的函数来供我们使用,于是便找到了 Sigmoid 函数来替代:
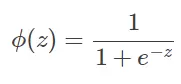
他们的函数图像如下所示:
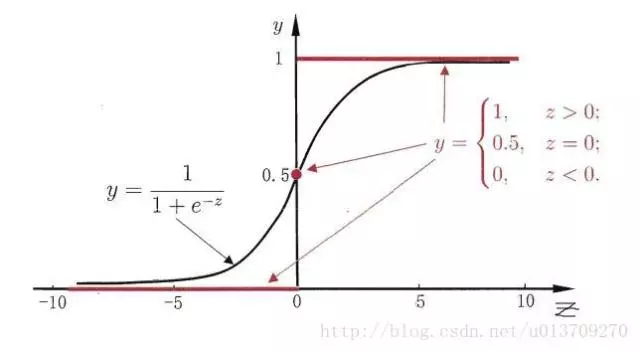
有了Sigmoid 函数之后,由于其取值范围为[0,1]。我们就可以将其视为类1的后验概率估计p(y=1|x)。说白了,就是如果有了一个测试点x,那么就可以用Sigmoid 函数算出来的结果来当做该点x属于类别1的概率大小。
于是,非常自然地,我们把Sigmoid函数计算得到的值大于等于0.5的归为类别1,小于0.5的归为类别0:
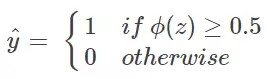
同时逻辑回归于自适应线性网络非常相似,两者的区别在于逻辑回归的激活函数时Sigmoid function而自适应线性网络的激活函数是y=x,两者的网络结构如下图所示:
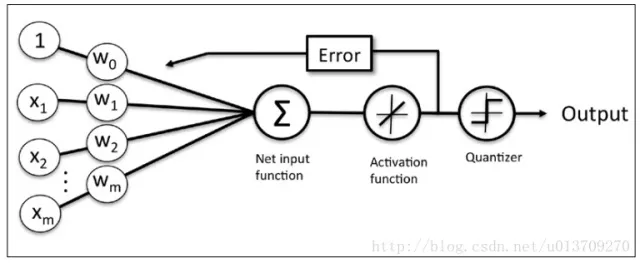
自适应线性网络
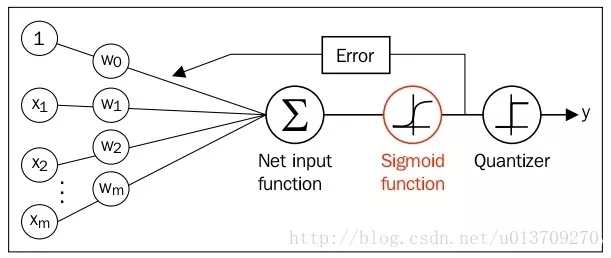
逻辑回归网络
02 逻辑回归的损失函数
好了,所要用的几个函数我们都好了,接下来要做的就是根据给定的训练集,把参数w给求出来了。要找参数w,首先就是得把代价函数(cost function)给定义出来,也就是目标函数。
我们第一个想到的自然是模仿线性回归的做法,利用误差平方和来当代价函数。
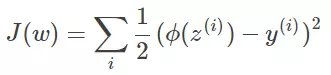
其中,z^(i)=w^T x^(i)+b,i表示第i个样本点,y^(i) 表示第i个样本的真实值,ϕ(z^(i)) 表示第i个样本的预测值。
这时,如果我们将 ϕ(z^(i))=1 / ( 1+epx(−z^(i)) ) 代入的话,会发现这时一个非凸函数,这就意味着代价函数有着许多的局部最小值,这不利于我们的求解:
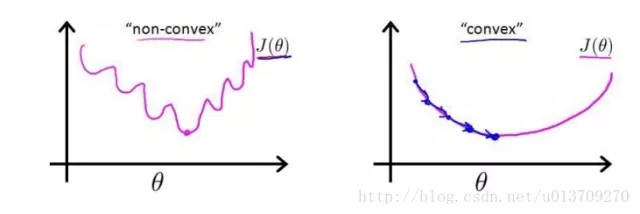
那么我们不妨来换一个思路解决这个问题。前面,我们提到了ϕ(z)可以视为类1的后验估计,所以我们有:
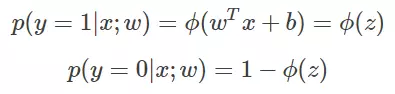
其中,p(y=1|x;W) 表示给定w,那么x点y=1的概率大小。 于是上面两式可以写成一般形式:
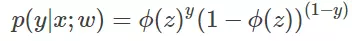
注:以上的过�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BB%8E%E6%8D%9F%E5%A4%B1%E5%87%BD%E6%95%B0%E7%9A%84%E8%A7%92%E5%BA%A6%E8%AF%A6%E8%A7%A3%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95%E4%B9%8B%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


