什么时候值得去使用上下文嵌入
作者:Viktor Karlsson
编译:ronghuaiyang
导读: 使用来自BERT的上下文嵌入是很昂贵的,而且并不是所有的情况下都能带来价值,我们来看看在什么情况下是值得使用的。
使用最先进的模型,如BERT,或它的任何后代,不适合资源有限或预算受限的研究者或实践者。仅仅是一个预训练的BERT-base,一个在当前的标准下几乎可以被认为是“小”的模型,在16个TPU芯片上花了超过4天进行训练,这将花费数千美元。这还甚至没有考虑进一步的微调或模型的最终服务,这两者都会增加总成本。
我之前的文章都是试图找出创建更小的Transformer模型的方法,现在,我会后退一步,问:什么时候来自Transformer模型的 上下文嵌入 是值得使用的?在什么情况下,用更少的计算开销, 非上下文嵌入 像GloVe或甚至 随机嵌入,可以达到类似的性能?是否有数据集的特征可以表明何时会出现这种情况?
这些是Arora等人在Contextual Embeddings: When Are They Worth It?中回答的一些问题。这篇文章将给出他们研究的概述,并重点介绍他们的主要发现。
研究
本研究分为两部分,首先检验 训练数据量 的效果,然后检验 这些数据集的语言特征。
训练数据容量
研究发现,训练数据量在确定GloVe和随机嵌入的相对性能方面起着关键作用。使用更多的训练数据,非上下文嵌入可以快速改进,并且在使用所有可用数据时,表现通常能够达到BERT的5% - 10%的范围内。
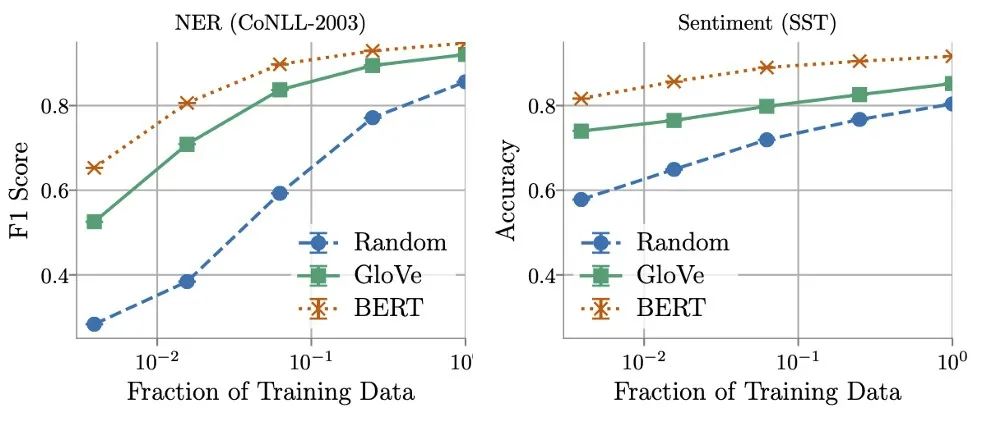
另一方面,作者发现在某些情况下可以用16倍 更少 的数据训练上下文化的嵌入,同时仍然匹配非上下文化的嵌入所获得的最佳性能。这就提出了推理成本(计算和内存)和标注数据成本之间的权衡,或者如Arora等人所言:
ML实践者可能会发现,对于某些现实世界的任务,在使用非上下文嵌入时,在效率上的巨大收获值得为更多数据添加标签。
数据集的语言特性
训练数据量的研究表明,在某些任务中,上下文嵌入的表现明显优于非上下文化的嵌入,而在其他情况下,这种差异要小得多。这些结果促使作者们思考,是否有可能找到并量化语言特性,以表明什么时候会出现这种情况。
为此,他们定义了三个度量标准,用于量化每个数据集和其中的特征。根据设计,这些度量标准没有给出一个单一的定义,而是用于编码哪些特征影响模型性能的直觉。这使得它们能够被解释,并随后被严格定义,用于我们所研究的任务。因此,在下面的列表中,我将分享作者提出的指标以及在命名实体识别数据集上的示例定义:
- 文本结构的复杂性。每个实体跨越的tokens数量表明了复杂性。“George Washington” 具有两个tokens。
- 单词用法的歧义性。在训练数据集中,每个token分配不同的标签的数量。“Washington”可以被指定为 人员、 地点 和 组织,这需要考虑其上下文。
- 没有见过的词的流行度。token出现的次数的倒数。如果前面的句子是我们的数据集,单词“of”将被赋值1/2 = 0.5。
这些指标被用来给数据集中的每个评估指标打分,从而允许我们将它们分割成“困难”和“容易”的子集。这使得作者可以比较来自同一数据集的这两个子集的嵌入性能。
总结
在Contextual Embeddings: When Are They Worth It?中,Arora等人强调了数据集的关键特征,这些特征表明上下文嵌入何时值得使用。首先,训练数据集容量决定了非上下文化嵌入的潜在有用性,越多越好。其次,数据集的特征也起着重要�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BB%80%E4%B9%88%E6%97%B6%E5%80%99%E5%80%BC%E5%BE%97%E5%8E%BB%E4%BD%BF%E7%94%A8%E4%B8%8A%E4%B8%8B%E6%96%87%E5%B5%8C%E5%85%A5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


