亿展宏图第一篇两张图入门图算法

供稿|eBay支付风控团队
作者|赵扬(Kevin Zhao)
编辑|林颖
“凡两个物体接触,必会产生转移现象”
——罗卡定律。
引子: 在老牌TVB剧《法证先锋》中,法证部的高sir(欧阳震华饰)经常说的一句话:“ 凡两个物体接触,必会产生转移现象”。这就是 罗卡定律,指的是:在犯罪现场调查中,行为人(犯罪嫌疑人)必然会带走一些东西,亦会留下一些东西。即现场必会留下微量迹证。而在eBay支付风控部门,我们也时时刻刻扮演着侦探的角色,与“不法分子”进行斗智斗勇。图算法(Graph Algorithm)作为侦探的好帮手,可以帮我们通过图深度学习的算法快速定位人与人以及人与物之间的微妙联系,用于抓住企图利用平台而做的不良行为。

导读
“亿展宏图”(“亿”是亿贝eBay的亿,“图”指的是图算法)是由eBay支付风控团队(主要负责保护在eBay交易的买家和卖家,降低交易支付风险)推出的系列文章,希望将eBay支付风控团队工作中图算法方面的一些理解和研究跟大家一起分享和探讨。同时,我们会把过去的几年里在KDD,AAAI等会议中发表的4~5篇文章的思路,用相对易于理解和形象的表述,轻松的融入到这些技术博客中,希望对大家有些启发。出于公司数据的安全性考虑,文中所用的数据是脱敏数据或者会有意换成假数据,请大家谅解。
整个“亿展宏图”系列将分为如下 7篇 技术文章:
1. 两张图入门图算法(介绍什么是图算法,并用两张图来总结图算法的各种研究方向和演化)
2.图算法在eBay 支付风控领域的应用(总结我们支付风控部门图算法的实际应用案例)
3.如何高性能训练图神经网络(介绍各种提升图神经网络训练的方法)
4.如何实践中解决图太大问题(介绍我们团队在图算法遇到海量数据时的处理思路)
5.如何解决异构图和可解释性问题(介绍异构图的深度学习模型和我们提出的xFraud异构图算法模型)
6.如何构建图上基于相似度的边(展示如何在海量数据的大图上构建基于相似度的边,并通过高性能的聚类算法进行聚类并定位恶意注册团伙)
7.动态图算法(带大家从静态图算法延伸到动态图算法模型)
作为“亿展宏图”系列文的首篇,本篇将从图算法的 介绍、 应用 和 演化过程 三个方面带领大家入门图算法,希望能对大家有所帮助。
一、什么是图
根据维基百科的官方定义:图(Graph)用于表示物件与物件之间的关系,是图论的基本研究对象[1]。图是由一些小圆点(称为定点或者节点)和连接这些圆点的直线或者曲线(称为边)组成。从定义中可以看出,图就是点和边的集合,研究图就是对点和边的研究。为了便于大家理解,我们以下面三张图为例:
1、社交图:人为节点,社交关系/方式为边;

2、知识图谱:知识为节点,知识点间的关系/联系为边;
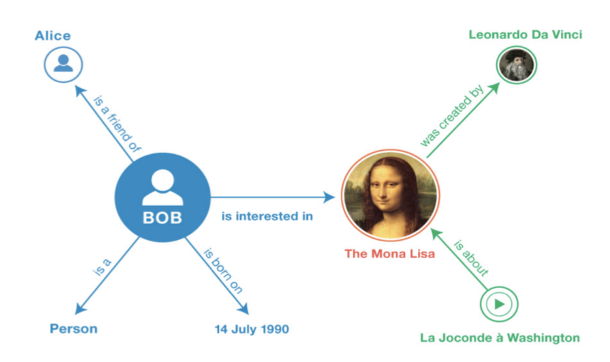
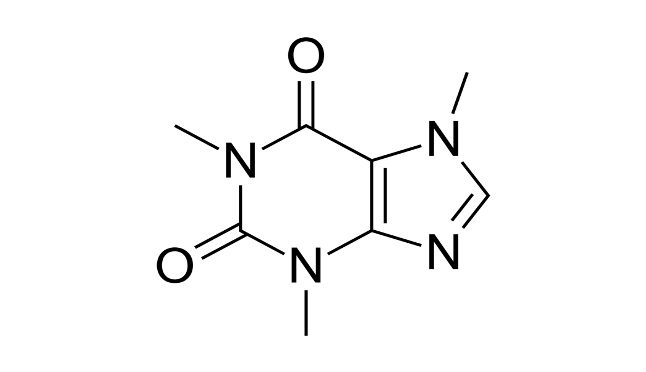
3、化学里面的分子图:原子为节点,键为边。
二、图算法的应用
上大学期间,有些人可能会开始“堕落”、不学无术,对所学专业缺乏兴趣。其中一个很重要的原因就是他们内心没有找到这些课程对他以后工作或者生活的用处。我一直认为,只有知道了这个“物”能为我们“所用”之后,我们才会更有耐心和兴趣去一步一步学习研究。这也是我为什么前两篇要优先介绍图算法应用而不是纯算法公式的原因。图算法在业界的应用有搜索推荐、分类、聚类、异常检测、传染病传播分析等等,我们逐一介绍一下。
1. 搜索推荐
通常的搜索推荐的算法无外乎从海量数据中先通过粗排找到相似的物品,然后通过用户反馈数据(比如点击量等数据)进行有监督的精排进行推荐。如果想要提升效果,肯定需要是引入了更多的对结果准确性有帮助的信息,而图算法的加入就是加入了点和边等等的结构相关的重要信息。
比如在Pinterest网站的搜索排序中,他们就引入了基于图的算法,因为用户会自己会建立自己的收藏商品集合,比如所有的洋娃娃在一个收藏夹里面,这样无形中就建立了点和边的信息,每个点就是物品,如果两个物品在一个收藏夹里面,他们之间就会有连边,更大概率是同一类物品。引入这种结构在某些场景下会大幅度提升算法效果。
普通的搜索会根据图片信息,错误地返回一些纹理颜色类似但并不是同类型的物品,如下图的第一行所示,比如灯具等等。而基于图的算法结果(如下图第二行所示)在某些场景下会明显较好。不少大公司目前在搜索中也都慢慢地开始逐步引入图算法得到的一些特征,进而提升搜索准确性。

(此图摘自斯坦福大学图算法课程[2])
2. 分类
如维基百科需要识别文章是否是假的/谎报文章(hoax article),这就需要分类模型算法。通常解决这类问题的思路是用各种自然语言处理(NLP)的模型,通过文字上的不同进行分类。但是如果仔细看维基百科里文章结构性的分析,你会发现文章的联系图结构其实就是最核心的分类特征。根据维基百科分析师的研究发现,真实的文章会更互相耦合,如下图所示:
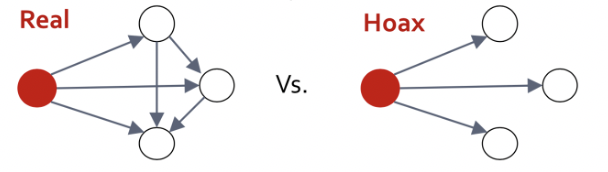
(此图摘自斯坦福大学图算法课程[2])
根据结构的不同,就可以建立图模型进行分类预测。效果如下:

(此图摘自斯坦福大学图算法课程[2])
根据以上数据显示:随机标记(Random)的准确率在50%,非专业人工标记(Human)的准确率在66%,而图算法(Network)的准确性可以达到86%!可见图算法在某些特定的分类应用中的优越性。
3. 聚类
业界有各种各样的图聚类算法,这里就先不赘述了。其中需要注意的是:图聚类算法和普通的K-means、层次聚类算法、密度聚类算法等各类传统算法的不同点。纯图聚类算法更多考虑的是图的结构,即边的结构,而不是传统聚类算法里面点和点之间的相似性。
4. 异常检测
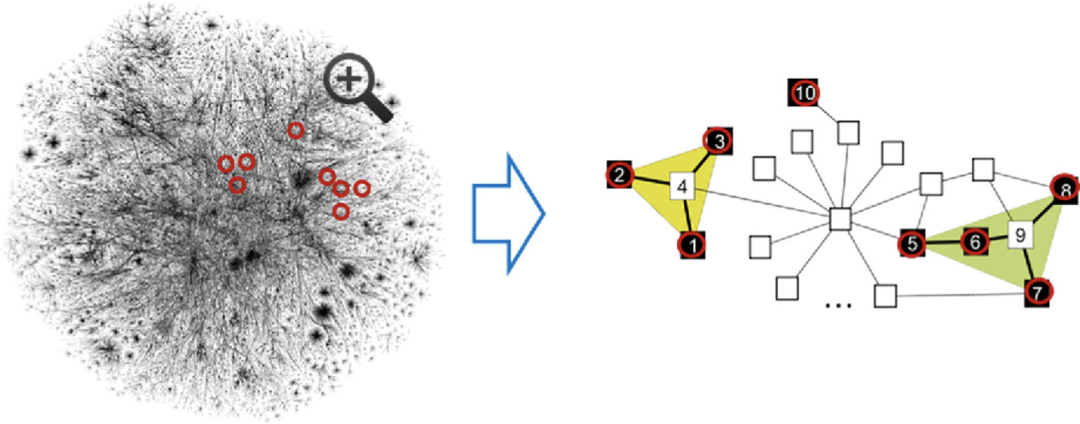
(此图摘自斯坦福大学图算法课程[2])
比如你有一个大的物理计算机集群,你可以通过图算法找到集群中各个机器,也就是各个节点之间的联系,并构造边,这样你就构造出来一张大图。当某些节点发生问题的时候,通过应用图算法便可以检测并定位到集群相关的节点问题。
5. 传染病传播分析
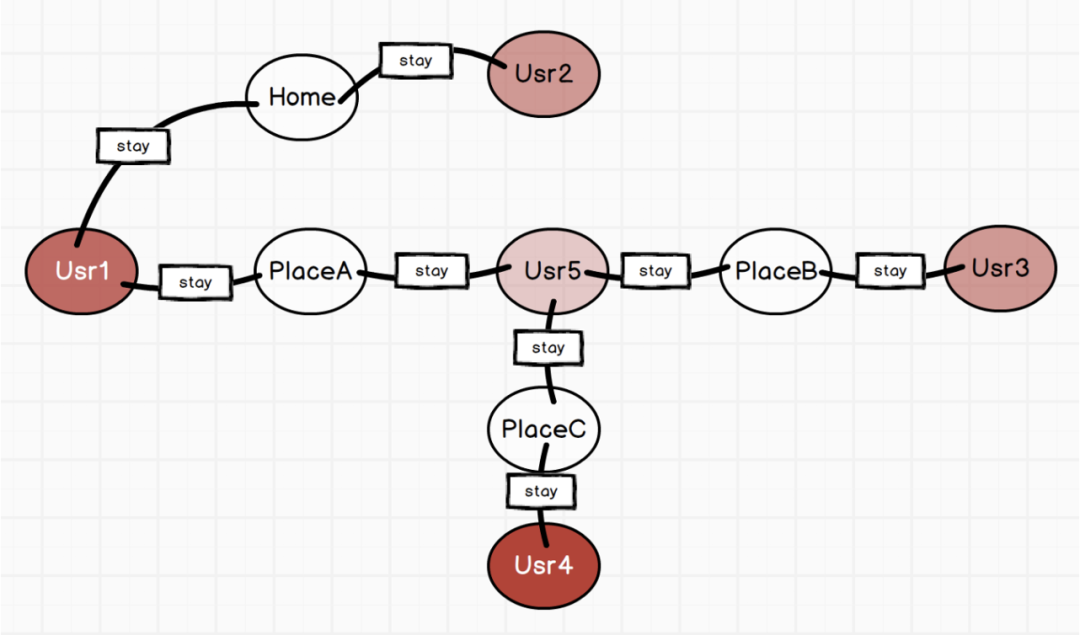
(此图摘自斯坦福大学图算法课程[2])
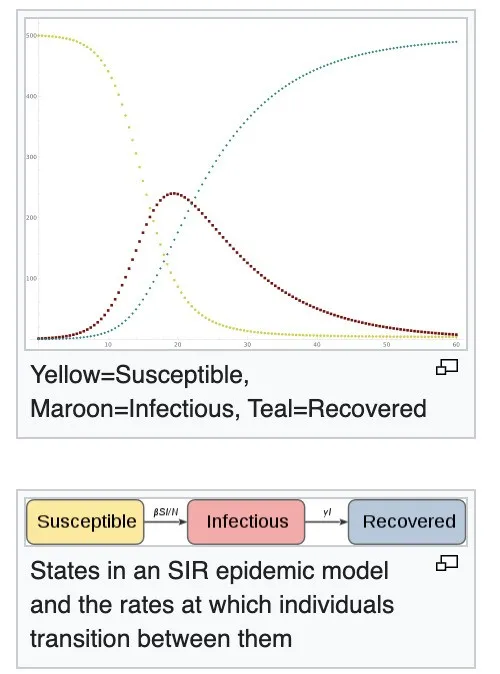
新冠来临之后,每个人的停留轨迹和与他人的联系就天然的形成了图,可以应用各种图的算法。比如上图就是用户(Usr)和停留的地方(Place)之间的连边图,我们可以轻松找到与潜在危险用户有联系的人。另外,还有一类学术专家在研究传染病的传染速率模型,经典的是SIR(Susceptible, Infectious, Recovered)模型,会通过统计模型来模拟易感染人群,感染人群和治愈人群之间的关系和相关系数。
三、图算法的演化
在真正学习某一方向的算法时,不仅仅需要了解当前最流行和高级的的算法细节,更需要的是总结这个领域整个算法体系的历史演化并了解各个主要分支。假如你想到了一个优化创新的方向,但这其实是前人早就研究过并认为已经是行不通的方向,那么这个方向的研究其实是低效研究。理清体系的演化过程就可以很好地避免这种“无用功”。
只有了解了图算法的形成,发展和演化的整个过程,对于图的应用才会有更好的掌控能力。下面是笔者根据个人理解总结的两张图,以便梳理整个图算法的演进过程,如有理解不到位的地方,也希望大家指正,共同加深理解。
首先,第一张图如下图所示:
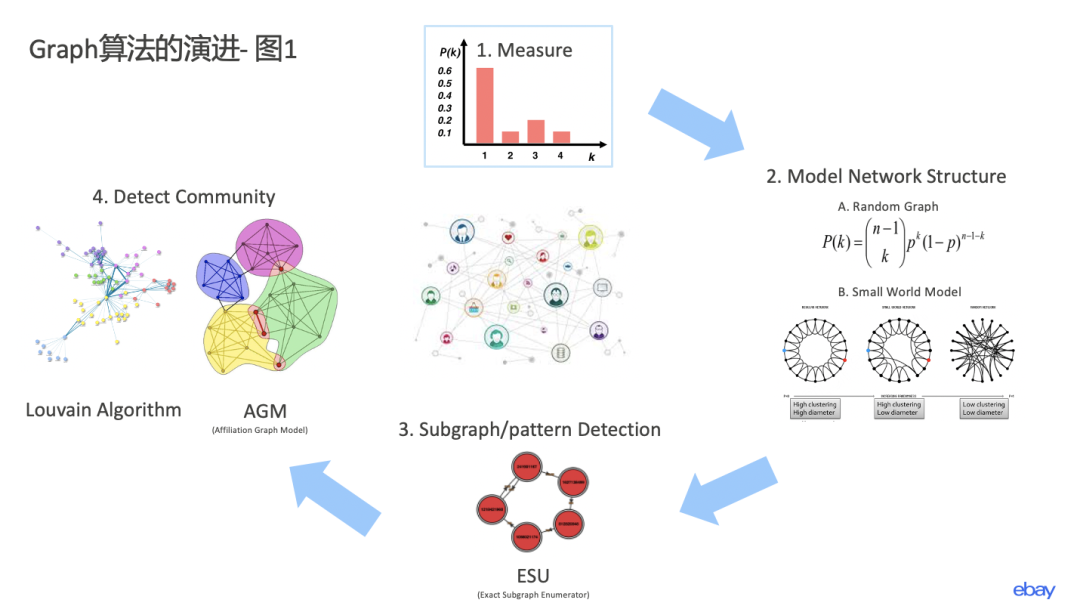
让我们先换位思考一下,假如说先辈们从来没有研究过任何图算法,你就是第一个开始研究图算法这个领域的人,你会一上来就研究各种图模型吗?不!你会先加深对于图算法这个领域的理解,做一些统计量,使自己对于这一门学科有更好的掌控力。
这就是第一部分: 测量(Measure)。
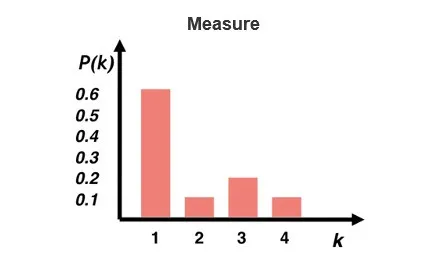
学术专家们定义了很多指标来描述一个图结果,比如说图的度分布,即每个点有几个边。比如一个点连有3条边,这个点的度就是3。对于每个点我们可以进行度的分布统计,就形成了度分布的统计量,用来衡量一个图的边的稠密程度等。
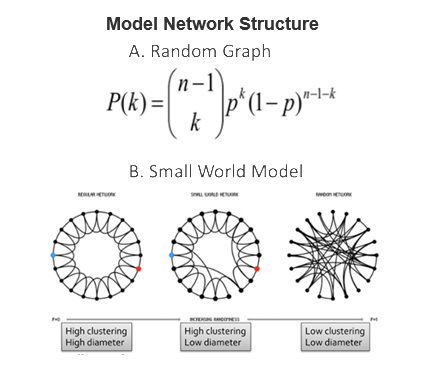
有了一些统计量之后,人们开始试图建立一些统计模型,这个时候假设条件就是我们的好帮手,当加入一些假设条件后,问题就会变得简单很多,并可以从理论上抽象出模型来,这就到了第二个阶段: 网络结构模型(Model Network Structure)。人们研究了各种宏观统计模型,比如经典的random graph模型和小世界模型。
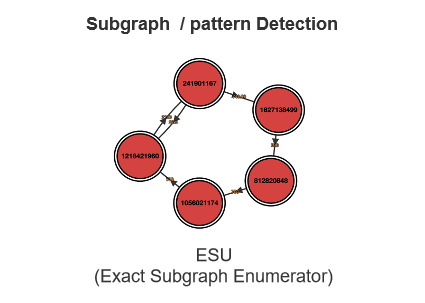
再之后,宏观的模型研究一番后,人们发现不太容易应用这些模型,因为这些模型有了过多的假设,使得它很难解决实际的业界问题,所以大家又回到微观领域,也就到了第三阶段 探索一个图中的子图或者某种模式(Subgraph / pattern Detection)。如下图所示的ESU算法等这类算法就很好地帮助我们ebay风控团队在海量交易里面找到某种特定的洗钱或者盗号模式。
在宏观微观都研究的差不多后,此时大家对于图已经有了相对深刻的了解,这个时候就更想研究用图算法来解决更常见的问题,比如对于图里面的人进行归类,并找到其中的共性来界定点和点之间的关系。这就是第四阶段: 探寻共性(Detect Community)。
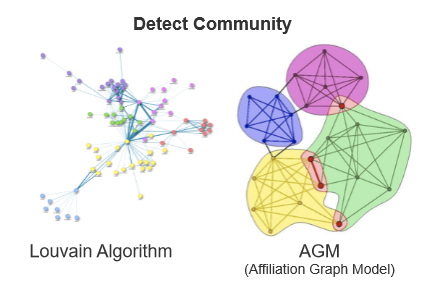
这一类的算法主要分成没有节点重合的基于模块化进行优化的louvain图聚类算法,以及允许有节点重合的AGM算法等等。这一块有很多学术研究者都在研究。有兴趣的读者可以查阅相关算法细节,因为篇幅问题,我这里不再赘述了。
以上四个阶段就构成了我所做的第一张图。
有了聚类之后,科学家们自然而然的就会自然延伸到分类的问题。最容易想到的分类方法就是通过周围 信息传递(Message Passing) 的方式来划分,比如我发现了一个高风险用户,那他周围跟他有联系(边
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%BF%E5%B1%95%E5%AE%8F%E5%9B%BE%E7%AC%AC%E4%B8%80%E7%AF%87%E4%B8%A4%E5%BC%A0%E5%9B%BE%E5%85%A5%E9%97%A8%E5%9B%BE%E7%AE%97%E6%B3%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


