人脸检测算法之
SIGAI特约作者
Baoming
算法研究员
导言
自从anchor-based method出现之后,物体检测基本上就离不开这个神奇的anchor了。只因有了它的协助,人类才在检测任务上第一次看到了real time的曙光。但是,夹杂在通用物体检测中,某些特定物体的检测任务由于应用量巨大,以及该物体的特殊性,需要单独拎出来考虑。其中最有代表性的就是人脸检测。
人脸相对于其他物体来说有一个普遍的特点,就是在图像中所占像素少。比如,coco数据集中,有一个分类是“人”,但是人脸在人体中只占很少一部分,在全图像上所占比例就更少了。本文所要介绍的S3FD[1](Single Shot Scale-invariant Face Detector)正是要解决这个问题。
人脸检测专用数据集—widerface
Widerface可以说是目前人脸检测数据集中最难的,放一张图大家感受一下

(图片来自widerface数据集)
图片像素1024 732,平均人脸像素10 13,难度可想而知。(一共标注了132个人脸,吃饱了撑的读者可以数数看)
当然了,这张照片只是展示了人脸的大小引发的问题,还有其他像遮挡,大角度,旋转等问题,由于不是本文的重点,不予过多讨论。
SSD简介
由于该算法是基于SSD来做的改进,首
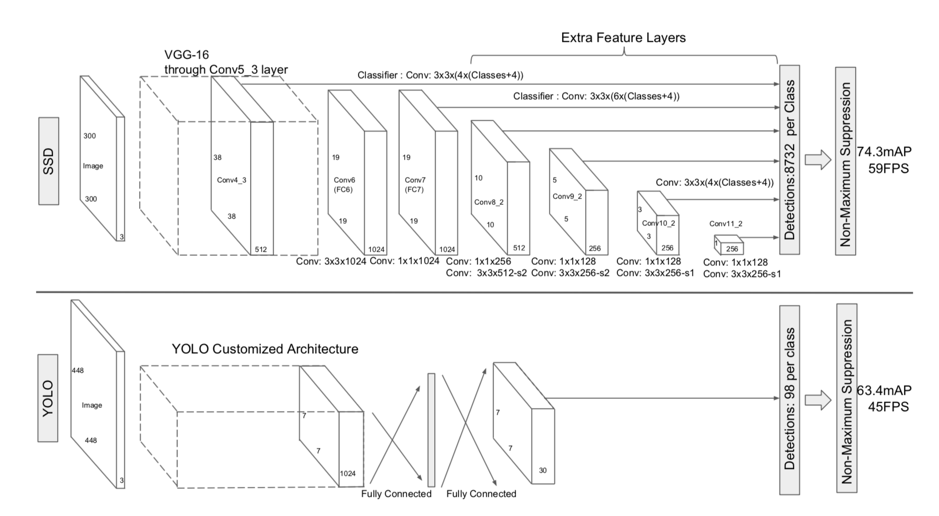
SD[2]。
(图片来自[2])
如图为SSD和YOLO的网络结构,他们也是最早的一批实现了one-stage检测的算法。可以看到,SSD为全卷积网络,并且通过不同位置的layer进行预测。换句话说,用低层网络检测小物体,高层网络检测大物体。
当然了,SSD也有一些明显的问题,比如对于小物体的recall很一般。部分原因是在利用低层网络做预测时,由于网络不够深,不能提取到有效的语义信息。
总之,SSD检测速度可以和YOLO媲美的同时,精度又可以和Faster RCNN媲美,而且很适合作为基础框架进行进一步的改进。
传统anchor机制在小人脸中遇到的问题
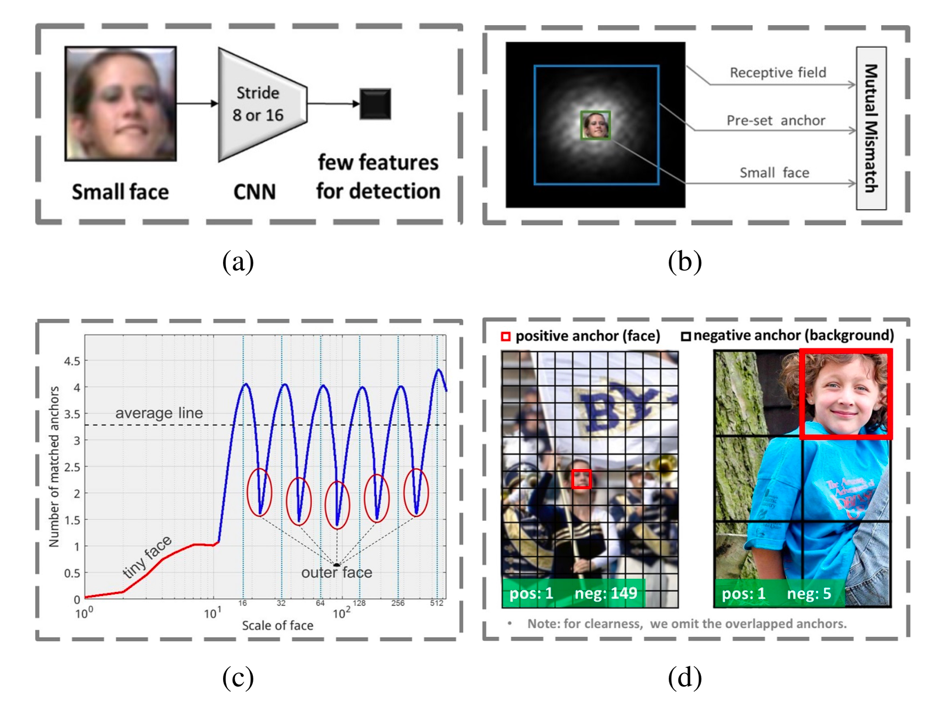
(以下图片均来自[1])
本文作者提出了四个问题:
1.人脸区域本身就小,经过几个stride之后,特征图上就不剩什么了
2. 相比于感受野和anchor的尺寸来说,人脸的尺寸小的可怜
3. 对于现有的anchor匹配策略,我们可以看到,人脸像素小于10*10的tiny face基本上一个anchor都匹配不到。而outer face这个问题其实是anchor-based方法的通病,每级anchor间大小差距越大,中间尺寸的mismatch现象就越严重。
4. 图中每一个网格可以看成是某个特定尺寸的anchor。可以看到对于左边的小人脸,正负比例严重失衡,这在训练时,尤其是first layer,需要特别考虑。
网络结构
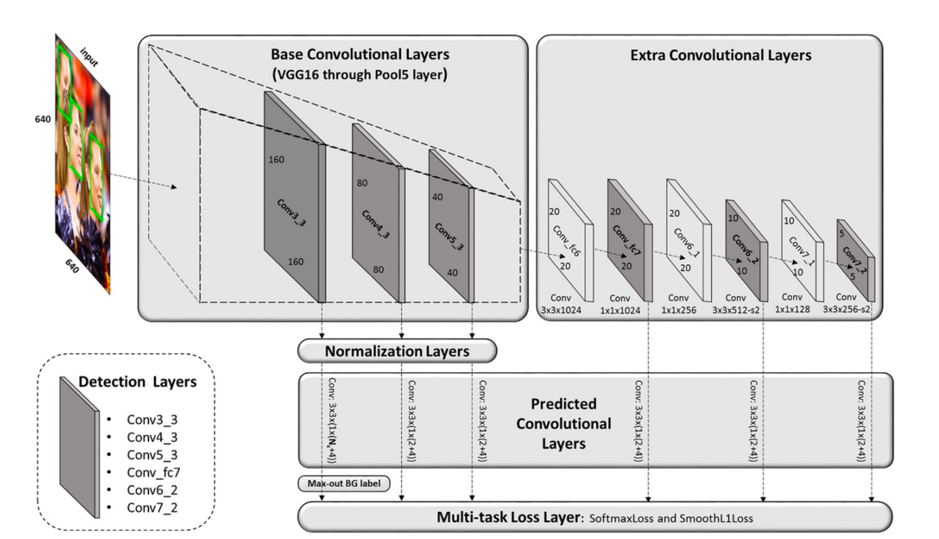
-
输入大小640 640,从feature map大小为160 160开始,一直到最后5 5,共有6级预测网络,anchor scale从16 16到最后512*512,依次指数加一(看了网络结构强迫症表示很舒服)。
-
每一个预测层,每个位置anchor只有一个(一个scale,ratio为1:1),因为在不扭曲图片的场景下,人脸的比例大概就是1:1(可能有少部分大长脸比例达到了1:2,但是太少了忽略不计)。因此,预测conv输出的特征维度是2+4=6
-
在作为预测的最低层的layer(即feature map大小为160*160)下面可以看到预测出来的特征维度为Ns+4,不是2+4,然后跟了一个叫Max-out Background label的东西,这个后面会讲到。
-
中间的conv_fc6,conv_fc7是从VGG的fc层提取出来然后reshape,作为初始权重。
-
Normalization layers就是SSD_caffe中的Normalize。感兴趣的可以去Github看weiliu89的SSD版本的Caffe代码[2]。
如何解决问题
-
Anchor与anchor之间重叠区域多。比如第一级,stride是4,但是anchor scale是16,所以相邻两个anchor之间有很大一块重叠区域,一定程度上解决了前文提到的outer face的问题。
-
改进了anchor匹配策略。
如果按照SSD中的匹配策略,jaccard overlap高于阈值(一般取0.5),平均每个人脸只能匹配到3个anchor,而且tiny face和outer face能匹配的anchor数量大部分为0。
作者设计了新的匹配策略:
第一步,将阈值从0.5降到0.35
第二步,对于那些仍然匹配不到anchor的人脸,直接将阈值降到0.1,然后将匹配到的anchor按照jaccard overlap排序,选取top-N个。这个N作者设计为第一步中匹配到anchor的平均值。
再来直观的对比一下新老匹配策略:

可以看到,average line和局部都有所提升。
-
前面提到,小人脸导致正负样本比例严重失衡。尤其对于最浅层的预测层,一方面anchor本来就多(像本文中的结构,第一级中anchor就占了总数的75%),另一方面由于大部分anchor是背景,导致false positive显著增高。所以为了减少这里的false positive,作者采用了max-out background。
前面我们看到第一级预测出来的特征维度是Ns+4,这里NS=Nm+1。对于不采用max-out策略的网络层,Nm可以看成是1,即只预测一个该anchor为背景的分数。但是这里取3,可以理解为重复三次预测该anchor为背景的分数,然后取这三个分数中最高的那一个。最直接的结果就是提高了该anchor被预测为背景的概率,因此能够减小false positive。
最后在widerface medium和hard等级上看看本文的成果(测试代码可以在作者提供的github代码中查看[3])
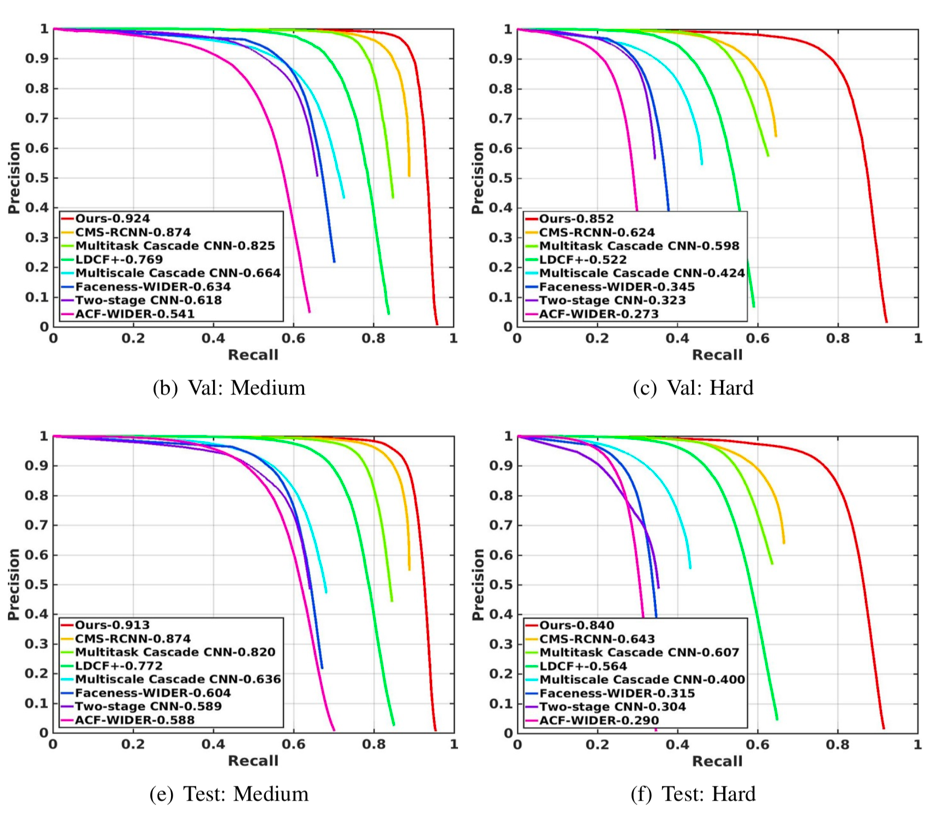
可以看到尤其是hard等级上,本文算法有巨大的提升。
参考文献
[1] Zhang, S., Zhu, X., Lei, Z., Shi, H., Wang, X., & Li, S. Z. (2017, October). S^ 3FD: Single Shot Scale-Invariant Face Detector. In Computer Vision (ICCV), 2017 IEEE International Conference on (pp. 192-201). IEEE.
[2] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016, October). Ssd: Single shot multibox detector. In European conference on computer vision (pp. 21-37). Springer, Cham.
[3] https://github.com/weiliu89/caffe
[4] https://github.com/sfzhang15/SFD
推荐阅读:
关注SIGAICN公众号,回复文章获取码,即可获得全文链接
[1] 机器学习-波澜壮阔40年 【获取码】SIGAI0413.
[2] 学好机器学习需要哪些数学知识?【获取码】SIGAI0417.
[3] 人脸识别算法演化史 【获取码】SIGAI0420.
[4] 基于深度学习的目标检测算法综述 【获取码】SIGAI0424.
[5] 卷积神经网络为什么能够称霸计算机视觉领域?【获取码】SIGAI0426.
[6] 用一张图理解SVM的脉络 【获取码】SIGAI0428.
[7] 人脸检测算法综述 【获取码】SIGAI0503.
[8] 理解神经网络的激活函数 【获取码】SIGAI0505.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读 【获取码】SIGAI0508.
[10] 理解梯度下降法 【获取码】SIGAI0511.
[11] 循环神经网络综述—语音识别与自然语言处理的利器 【获取码】SIGAI0515.
[12] 理解凸优化 【获取码】SIGAI05
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%BA%E8%84%B8%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95%E4%B9%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


