人机交互式机器翻译研究与应用

分享嘉宾:黄国平 腾讯AI Lab 高级研究员
编辑整理:赵文娇
内容来源:DataFun AI Talk《人机交互式机器翻译研究与应用》
出品社区:DataFun
这个题目看起来比较小众,希望大家听我的讲座没有白听,可以学到一些东西,就是AI技术落地过程中的一些问题,以及解决策略和方法,技术、产品、行业问题的大杂烩。
我的分享主要包括以下几个方面:
1. 机器翻译现状简介;
2. 翻译需求与人工翻译行业;
3. 人机交互式机器翻译技术;
4. 人机交互式机器翻译应用;
5. 人工智能落地的一些思考。
首先会过一下机器翻译的现状,看一下翻译需求是怎么回事,然后就是我本身做的事情,还有做这个事情过程中遇到的哪些问题,以及这些问题带来的思考。
机器翻译现状简介:
机器翻译在2018年不想听到这几个字也很难,有的公司说起人工智能好像也不知道做什么,那就做一个翻译机或者同传吧,如果没有技术怎么办,没有技术的话,你也可以做机器翻译,怎么做呢?做人机耦合吧,把人关到同传箱里面,然后翻译内容不由机器来生成,由人进行生成,把人工翻译结果打印到屏幕上。翻译其实是比较低频的需求,但是在2018年很多公司希望在翻译上展示出自己不一样的能力,表现出很饥渴的样子,大家很多时候或多或少有这样的疑问,当大家真的需要用机器翻译的时候,往往错误百出,在同传的时候,在博鳌论坛上,翻译连续翻译出10几个神奇的句子,这种神奇诡秘的地方,对于机器翻译来说,这不是伪需求吗?谁会花几千块,大几百块买那么一个破玩意儿,但是各家说自己出货又很高,我一直没有想明白,为什么那些翻译机的销量能有几百万,几千万台,然后各家的数据一综合的话会超过亿,可是在我身边却看不到呢,我们AI行业各家的数据都是谜一样的存在。每家都在宣传自己掌握核心技术,通过开源软件知道了机器翻译的原理,出来的东西也都差不多,一句诗来形容就是“藕花深处田田叶,叶上初生并蒂莲”。
国内最近20年,长期投入的机器翻译的单位大概有这么几家,有的资深一些,有的比较新一些,比如说腾讯在机器翻译上的投入没有超过3年,超过10年快20年的是前面几个单位,比如说中国科学院自动化研究所(也是我读博的地方),还有中国科学院计算机技术研究所,除此之外,清华,哈工大,这些时间也比较长,苏州大学比较年轻的,最近几年在人工智能上的成绩是有目共睹的,公司的话应该是百度和网易有道,其他的相对晚一些。机器翻译的从业人员,应该都是从这些机构走出来的,毕业的或者跳槽的,思维趋同,做出来的产品大差不差。
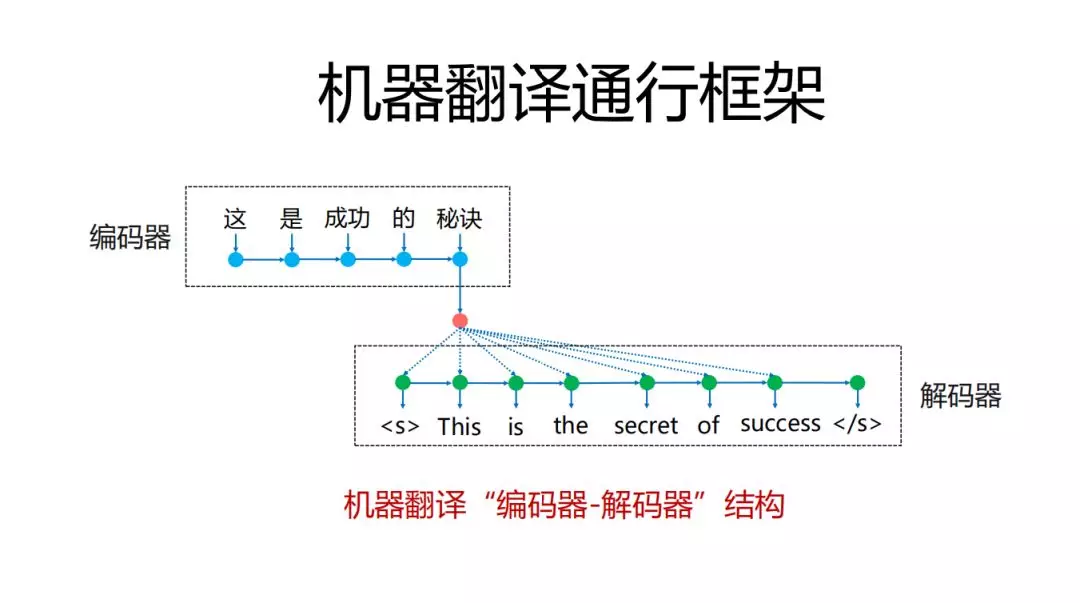
机器翻译用的框架还是雷同的,主要是细节处理或者是针对一些问题本身的改进。通行的结构就是编码器解码器结构,做深度学习的对这套框架应该是很熟悉的,最难用的就是先把原文句子经过每个字词通过RNN之类的手段对它进行编码,最后形成一个句子向量,在解码端,从句子开始根据句子向量,生成空格段的词,最难用的框架,问题可能是比较多的:比如它的基本原则很简单,在解码器一端从句子开始到句子结尾处,它才停止翻译的过程,如果没有遇到句子开始和句子结尾的话就一直进行翻译过程。大家很容易想到有些问题:比如在这种框架中,有些片段没有翻译到,形成丢失,或者是生成的译文和原文没有什么关系。大家实际中在使用线上翻译产品中会有这样的感知,虽然现在的机器翻译和三四年前相比已经有了质的飞跃,但还是不合格的,仍然有很多问题,这时如果需要弥补这些问题,一般都是加模型。
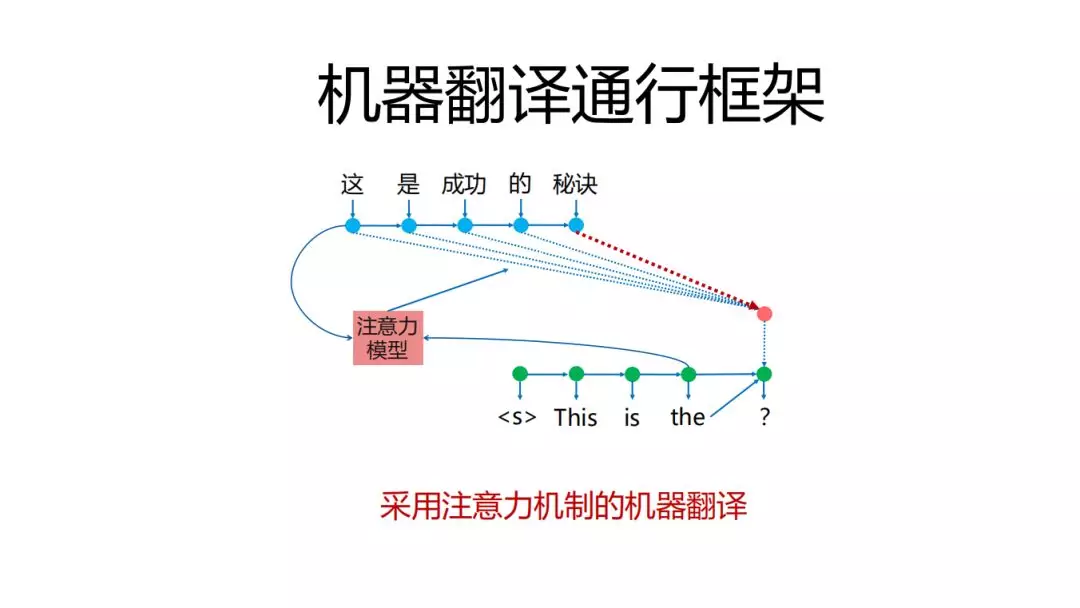
最简单的就是注意力模型,加注意力模型的本质需求是希望我生成的下一个目标词的时候能与原文的某些词或者某一个词建立比较强的联系,并通过注意力模型,来生成随翻译过程不断变化的上下文向量。它根据原文编码,加注意力模型之后呢,它会随着前面已经生成的词,进行变化,这个时候翻译效果会上升一大截。
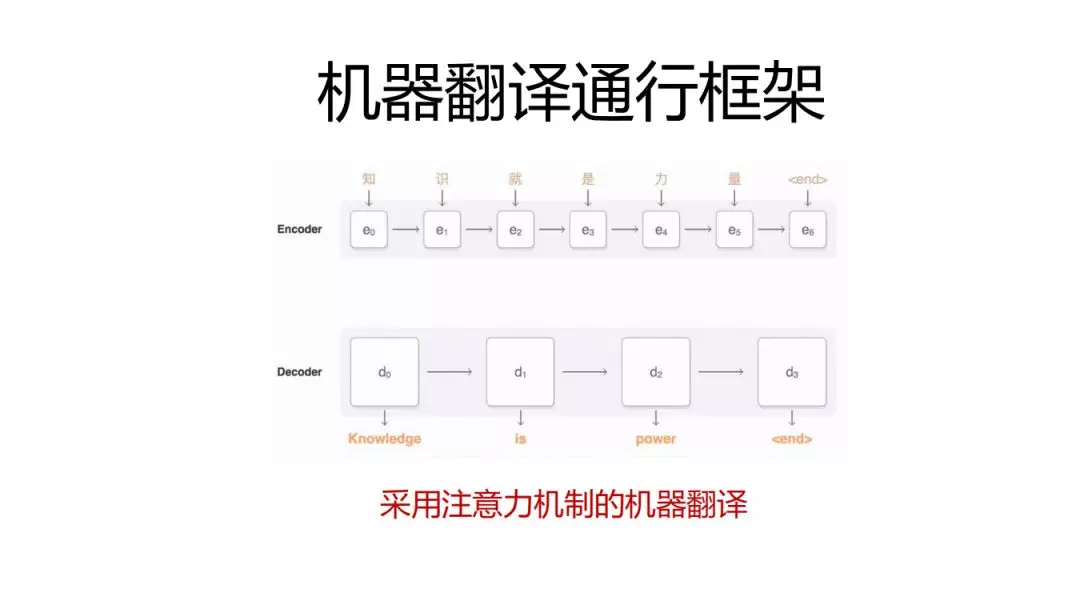
如果用固化的方法来讲,注意力模型怎么去解释它的物理作用呢?在翻译这个问题下,它看起来有点像翻译的概念,就是词到词之间的翻译,但是好多词又不一定,在使用线上翻译的时候,输入原文句子里面多一个标点,少一个标点可能引起译文端的剧烈变化,这个时候,这个时候注意力就是学偏了,它把好多东西都压到了原文最后那个标点上面。所以我们人工单相思式的去解释翻译概念是不对的,既然注意力机制与翻译概念不是那么有关系的话,那就换一下,比如谷歌发表了transformer的架构。
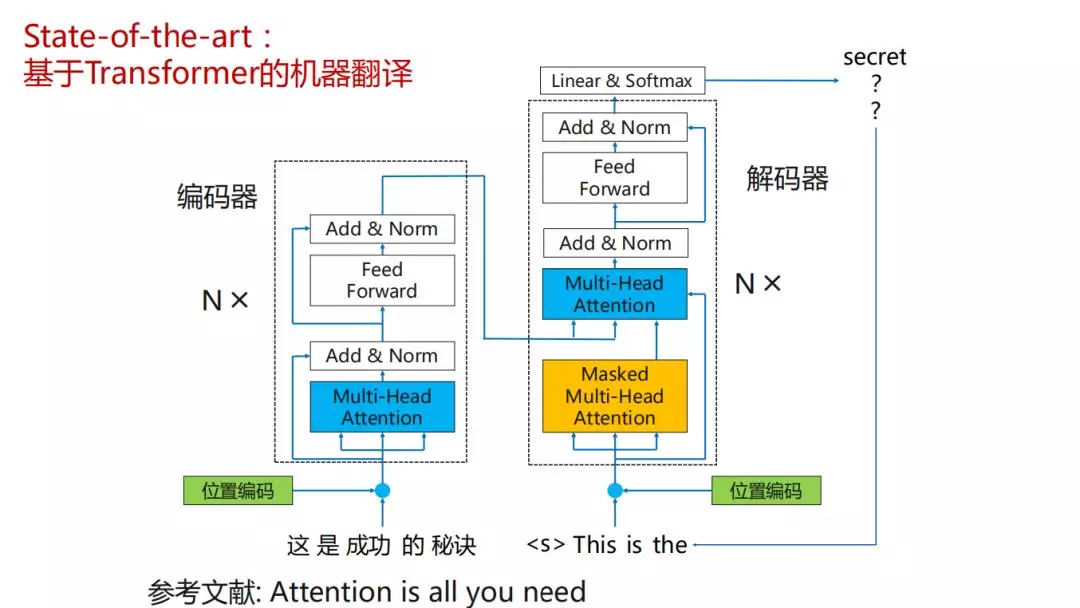
大家如果做这个方向应该是比较熟悉的,不做这个方向的,要理解的东西也比较多,相比RNN结构,transformer这个结构相比RNN,对原文信息的编码是更充分的,比如说是在RNN的时候,对原文的编码都是从左至右或者从右至左,但是在transformer这一套框架中,它对原文中每个词的编码都会参考整个句子的词,而且编码还不止一层,有个self-attention机制,一般我们用attention都是原文和目标端文字之间的关系,但是在transformer关系中它会计算原文和原文之间的关系,然后译文与译文之间的关系,这样就会更充分了,但是参数规模会爆炸,所以也出现了比较尴尬的事实,transformer在比赛中,如果GPU状态比较差的话,是跑不了实验的,比如我们实际场景上线,就是训练语料是以亿句为规模的,想通过1080,或者2080那是肯定跑不出来的,因为要跑好几个月,就算是P40,一块P40也没什么用,就是它的单个显存比较大一些,比如说24G左右,因为在面对海量数据的时候,我们一个模型,跑一个模型48块盘,48块P40,如果大家是玩一玩或者创业公司来做这个事情的时候,会有很多的困难,也许以后会随着云计算业务的普及,大家会受惠,但是短期而言的话,在做AI技术落地的时候,硬件对于创业团队容易造成很大的经济压力。
State-of-the-art:基于Transformer的机器翻译
transformer对语言的编码不是单向的,每个词每一轮的编码都会参考上一轮的结果,这是transformer显著区别于RNN的区别,编码器如之前所言考虑句子中所有词,解码器默认是从左到右,从句子开始生成下一个词,在生成下一个词之前,对之前解码的内容进行多轮解码。
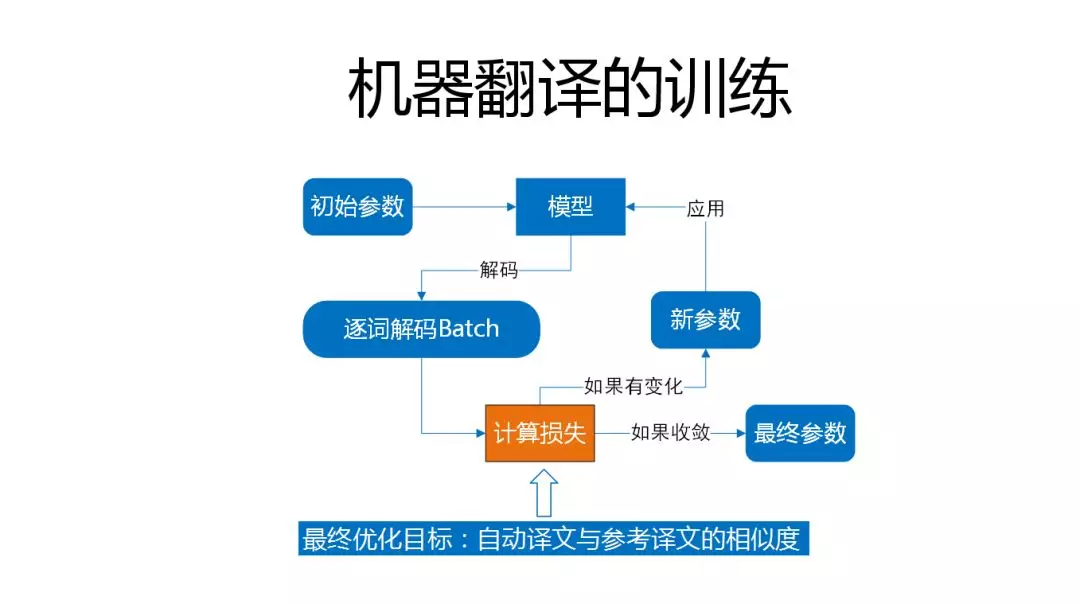
机器翻译的训练和大家做其他的训练也没有什么两样,都是随机初始化,或者按照某种预设方式初始化参数,然后把它加载到模型中,对训练语句进行batch数据,计算损失,调参数,重复这个过程,直到最后收敛,把参数保留下来,没有什么不一样的地方,只是需要注意计算损失这一步。因为一般而言在翻译领域,如何去评价一个自动译文好不好呢,我们的评价指标叫blue,它是和参考译文去比对,一元的串匹配的有多少,二元的串匹配的有多少,三元四元有多少。但是在神经网络翻译训练当中,我们是没有办法用blue这种方式的,这时候就用PPL,用的比较广泛,虽然在统计规律中讲PPL越低,blue值会增的,但是好多时候,在一些比较狭小的空间,它会有个反馈,所以这个时候会有个模型选择。这个模型选择一般是构建一批比较大一点的人工测试集,就是面向开放领域,或者把大家的高频query抓下来,埋点,然后中间会生成一堆checkpoint,然后看哪个更能体现线上实际要求,这个过程和做其他产品没有特别大的区别,只是做数据处理充满各种小的技巧。

比如说在做产品的过程中产品还没有发布,买数据的钱花了好多,然后人工评估体系的构建又花了好多钱,最后都不知道这个产品能赚几个钱。(注:当然我是很有自信的,我的产品能把产品的成本赚回来了。)现在各家都在炒作自家产品,其实用的技术没有差太多,如果用相同的语料去训练各大公司的机器翻译引擎的话,大家blue值的差别不会超过3个,区别其实会很小很小,大家为什么又拼命强调其中的差异化呢,其中最主要的原因就是:目前,翻译的问题还没有被彻底解决,大家还可以找出很多差异,但是大趋势是趋同的。机器翻译的困难呢,大家在做的过程中会有一些体会,我这里总结了四个方面:
第一个方面就是歧义和未知现象: 歧义的,像南京市长江大桥这种都老掉牙了,未知现象的,比如是在武侠小说里面驾。。。驾。。。(模仿骑马的这种), 再比如新产生的词不太容易被翻译出来。
第二个方面是翻译不仅仅是字符串的转换: 直接翻译不能解决所有问题,比如,青梅竹马,直接翻译成英文是“发青的梅子,竹子做的马”;特定情况下的江湖(比如有人的地方就有江湖),直接翻译过去就是“江和湖”,其实并不能表达中文中的语义;再比如特定场景下的“你妈妈叫你回家吃饭了”,都没法直接逐字进行翻译。
第三个方面就是翻译的解并不唯一: 缺乏量化标准,并且始终存在人为标准,这个是精准层面的,把一句话表达清楚,其实有很多方式。
第四个方面就是翻译的高度: 有的语句意境很高,上升到文学层次了,比如“最是那一低头的温柔”,翻译的时候涉及到意境的体会和把握,对于人工翻译来说困难,对于机器翻译来说,也困难。
翻译需求与人工翻译行业:
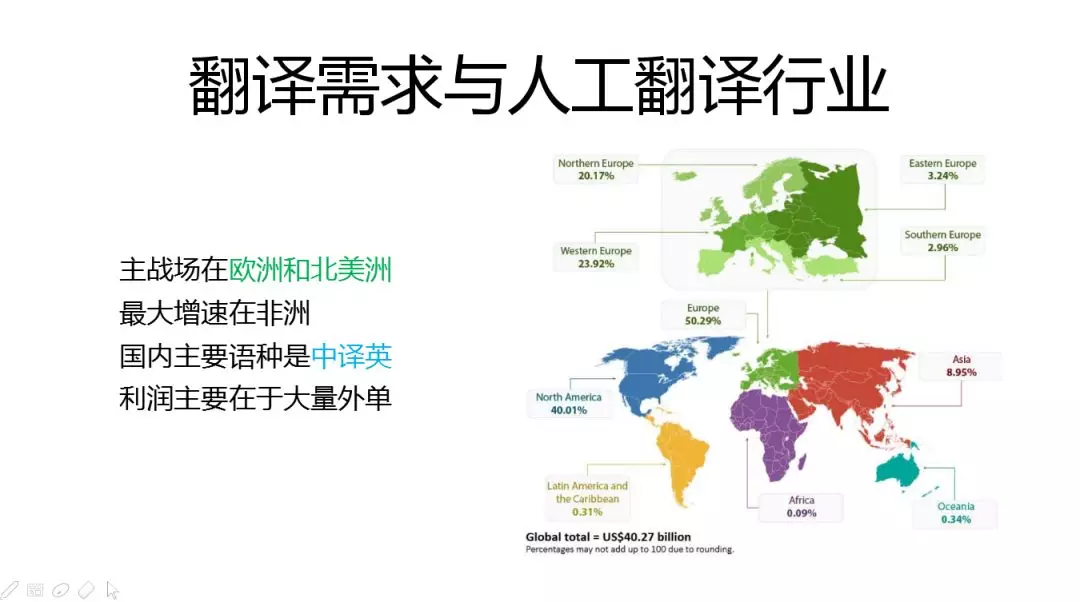
翻译行业全球的产值还是很高的,大约四到五百亿人民币,主战场在欧洲和北美洲,最大增速在非洲,中国占10%左右,国内主要的语种是中英互译,利润主要来自于外单。
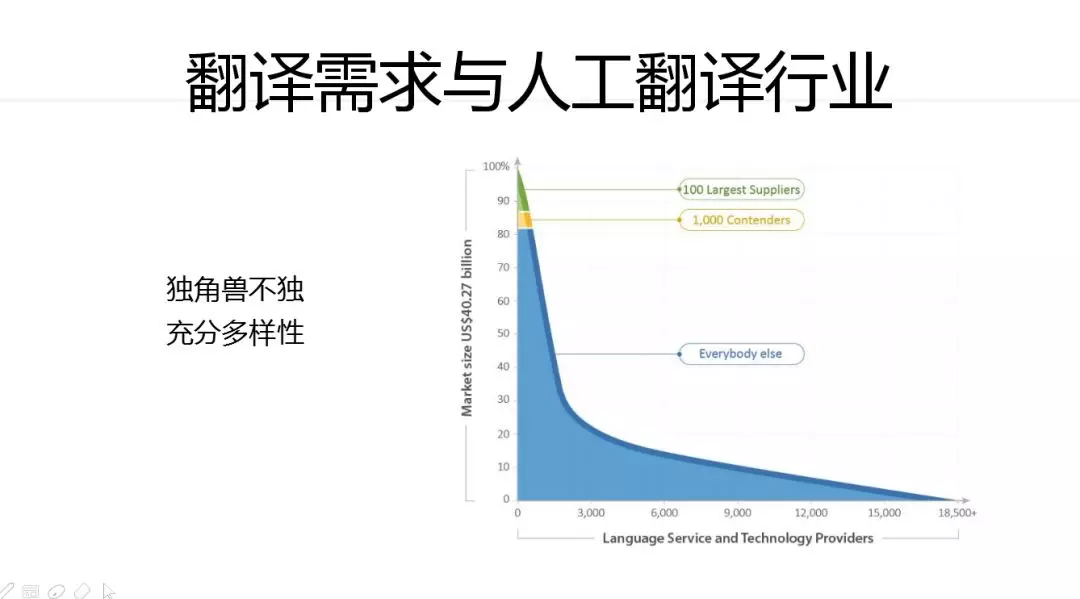
独角兽不独,充分多样性。其他领域独角兽往往比重很大,占据70%左右的市场,但是翻译市场不是这样。从2005年到2016年头部公司的排名和占比区别不大。
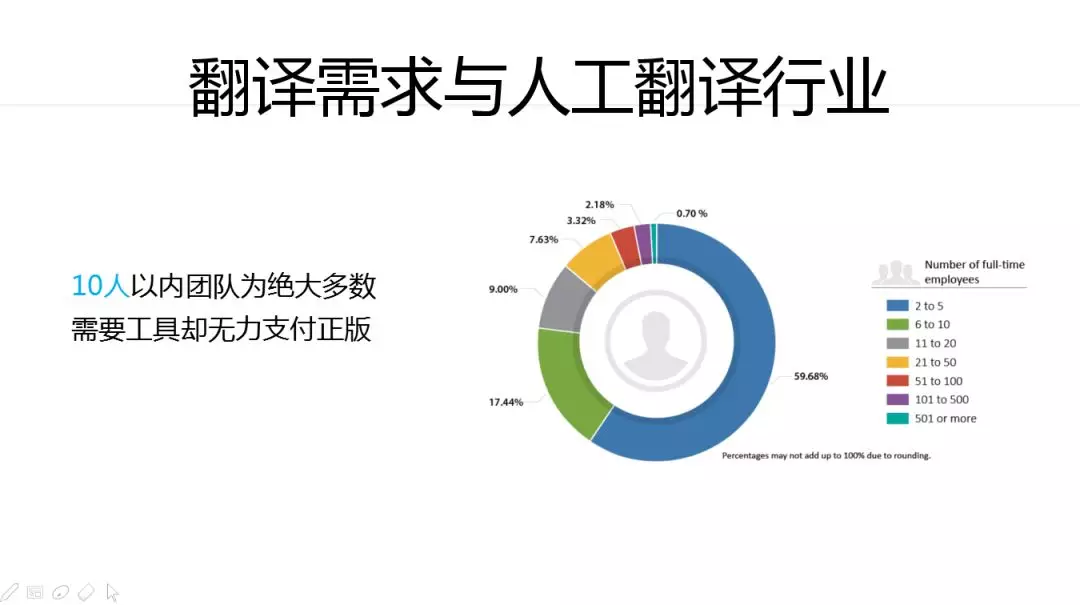
10人以上团队需要工具却无力支付正版。
人机交互式机器翻译技术:
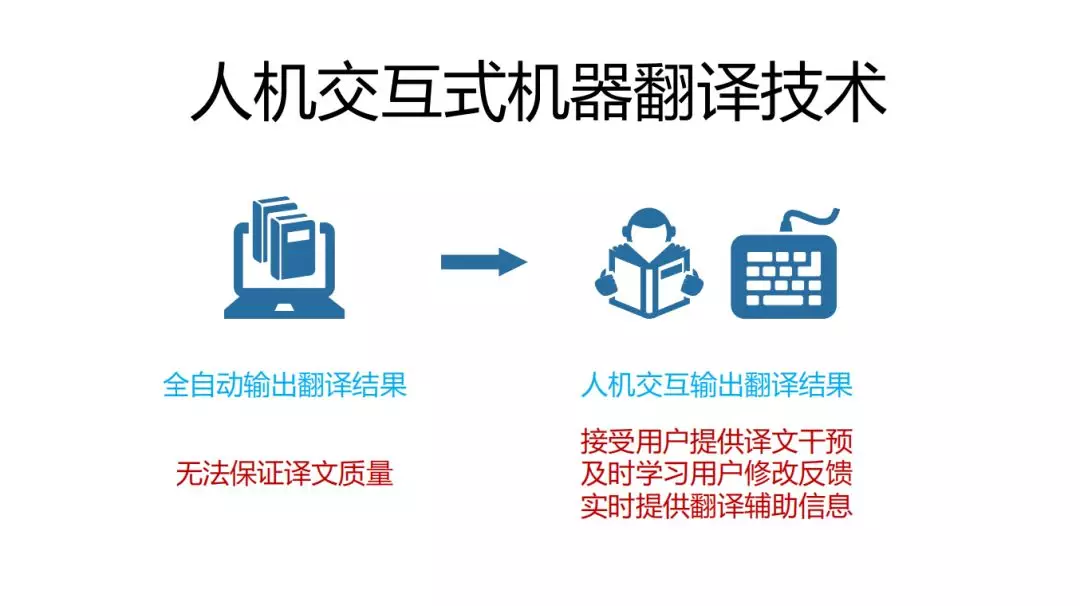
背景:全自动输出翻译结果无法保证译文质量,这时候就需要人机交互,实现下面三个任务:
1. 在翻译过程中接受用户提供译文干预,能根据干预结果生成更好的结果;
2. 及时学习用户的修改反馈,不能一个愚蠢的错误反复出现;
3. 实时提供翻译辅助信息。
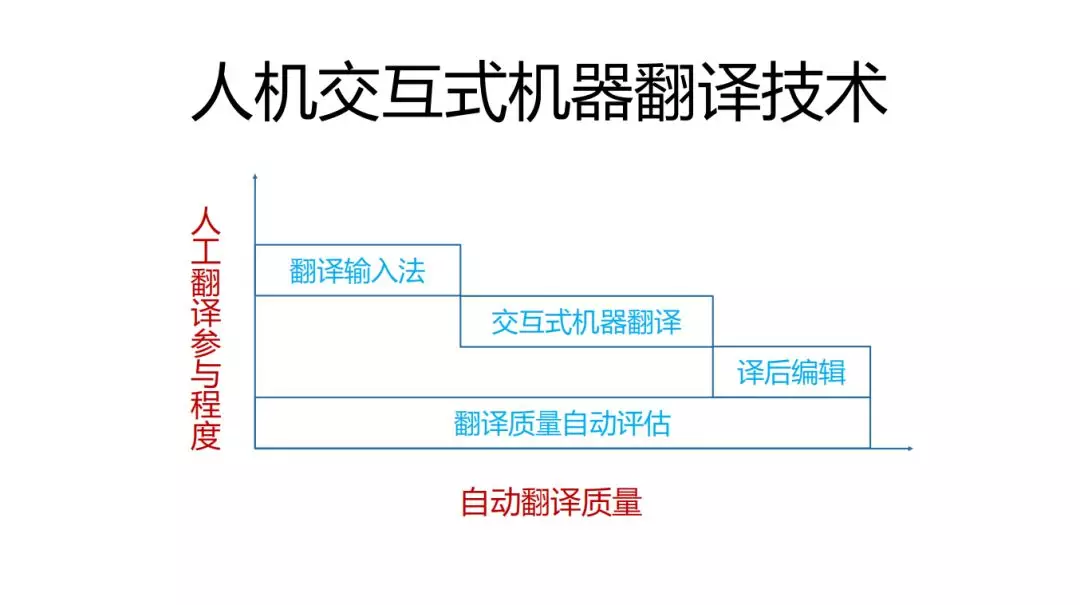
人工翻译如何和机器翻译产生交互?人工翻译参与程度与自动翻译的质量相关,如果自动译文的质量较高,那就机器翻译直接发挥作用了(人工只需要在自动译文之后进行校验),如果自动译文的质量比较低,就需要比较高的人工介入,像翻译输入法(相当于比较多的人工标注),如果主动译文的质量不好不差的情况下,可以用交互式机器翻译来解决翻译质量的问题(人工标注比较难的部分)。
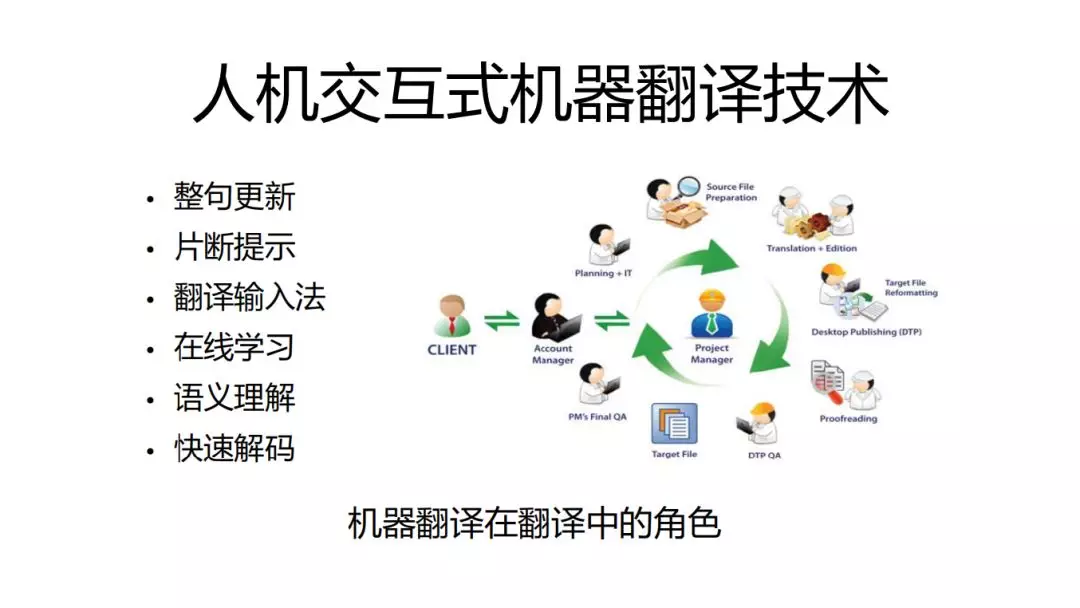
在自动翻译过程中,机器翻译可以扮演的角色:
整句的更新(高精度的翻译整个句子)、片段提示(在无法保证整句精准的情况下保证重点片段的精准)、翻译输入法、在线学习、语义理解、快速解码。
在整个过程中,除了AI技术,还涉及到产品设计能力。需要产品经理和技术人员之间的协调和共识。

最简单暴力的使用机器翻译的一种,就是译后编辑。就是首先机器翻译,然后人工编辑。

机器翻译不差不好的情况下使用交互式机器翻译,就是人工翻译片段和机器翻译片段交替进行。
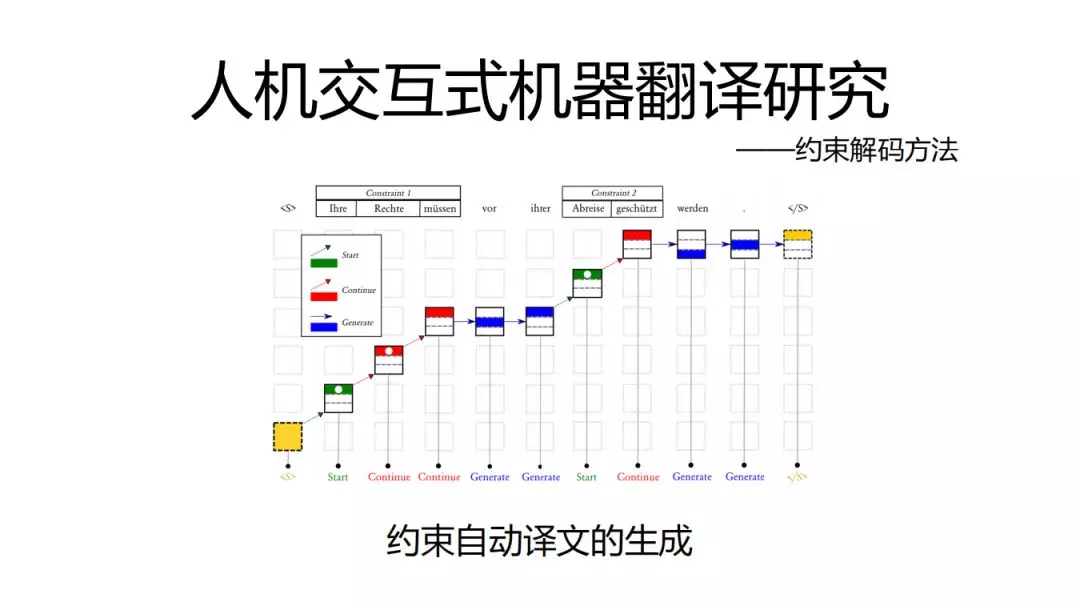
约束解码方式,就是强制在翻译中必须含有一部分术语,比如说一句话中必须把“深圳腾讯”,“社区”包含在内,这一点是目前难以做到的,主要是卡在翻译速度上,时间消耗严重。
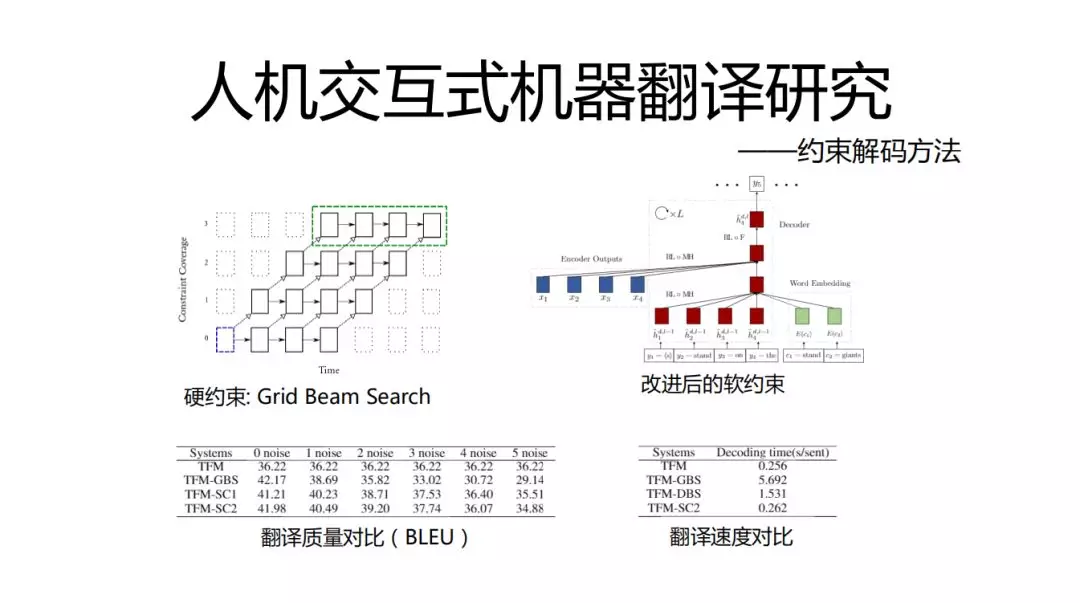
我们对算法进行了一些改进,如上图所示。
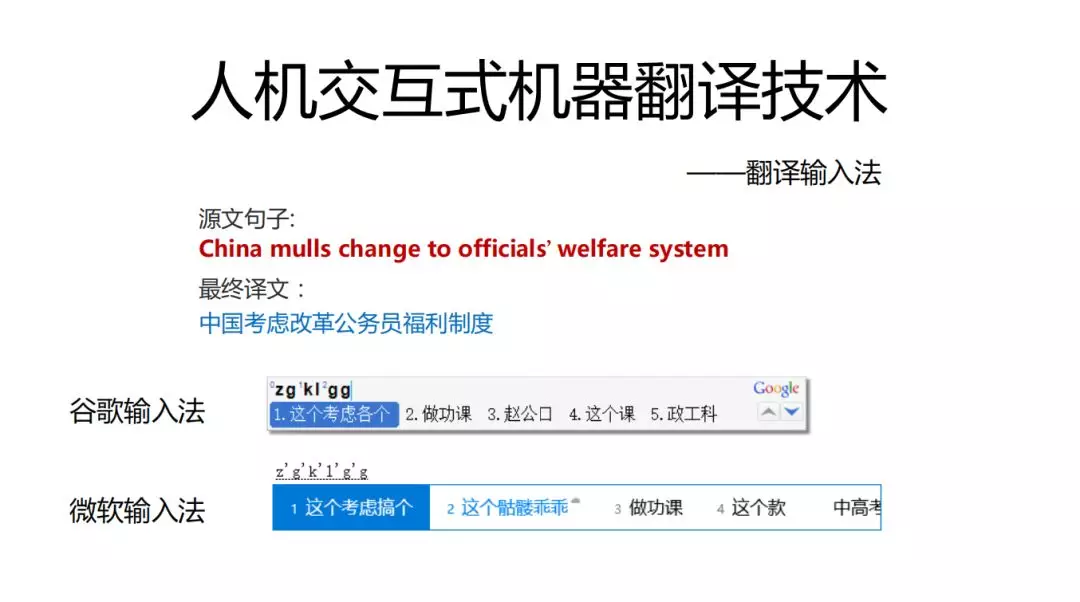
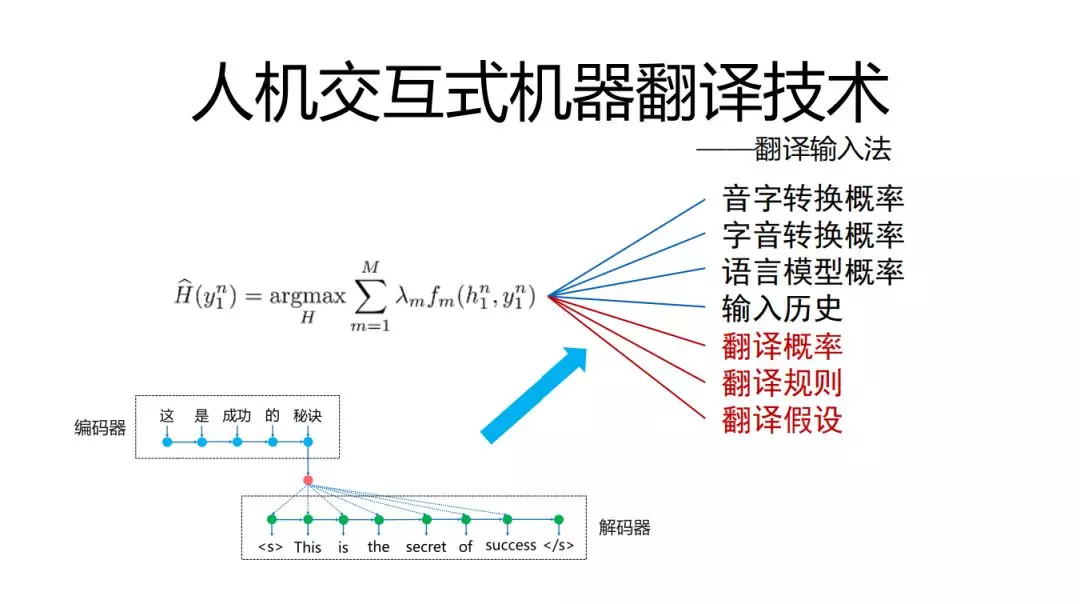
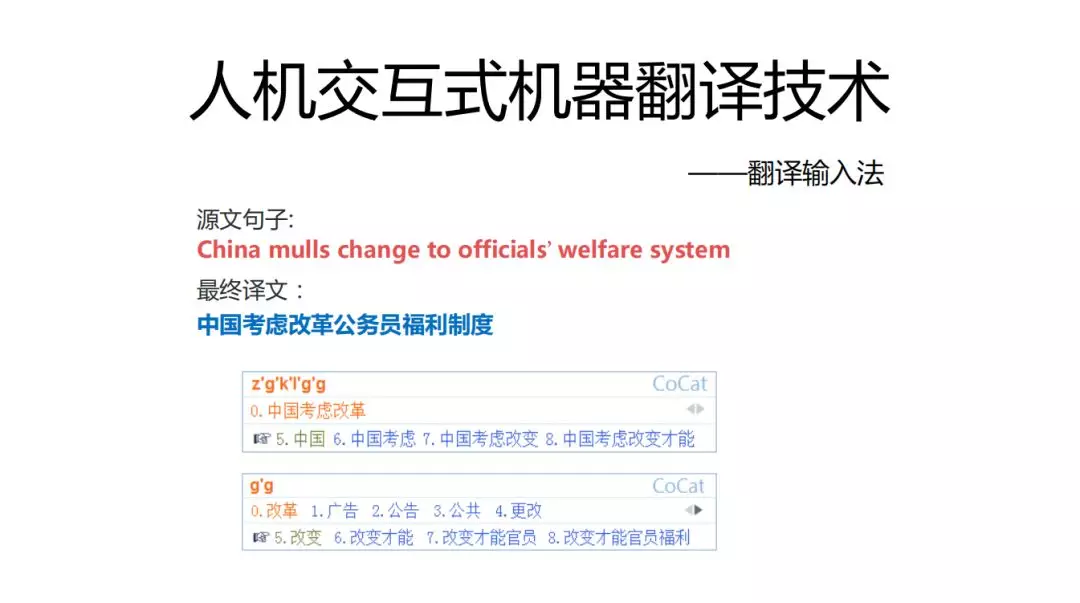
我们希望用户打完这句话用的按键数越少越好,用谷歌和微软输入法结果如下,因为一般的输入法去学习的是人的输入历史,我们引入机器翻译的东西可以改进过于依赖输入历史的情况。
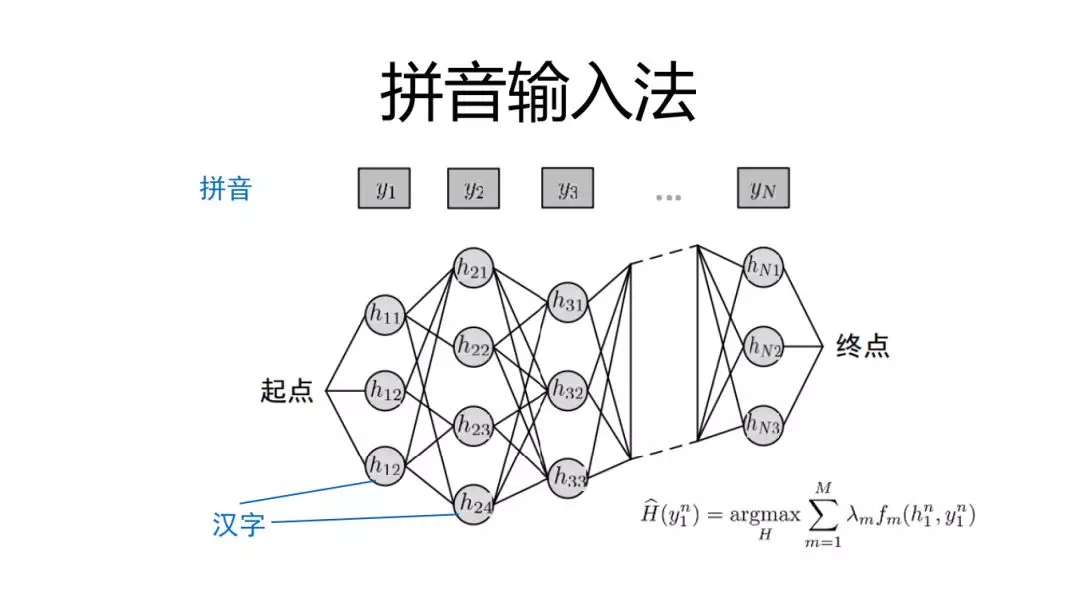
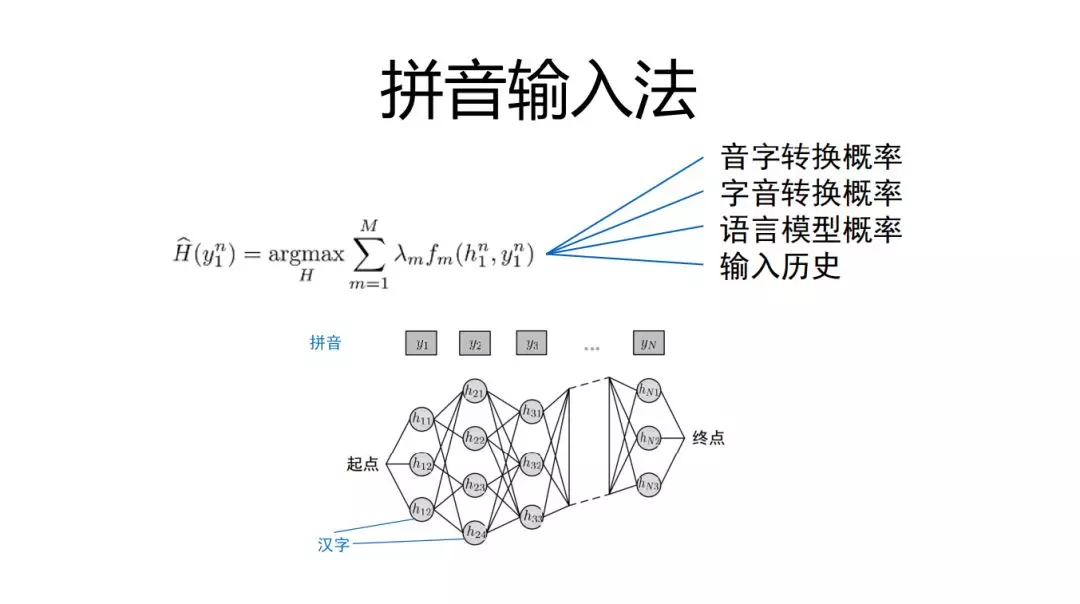
拼音输入法:是寻找最优解的过程,需要对过程进行打分,之前主要是音字转换概率,字音转换概率,语言模型概率,输入历史。这里我们可以进一步引入翻译技术。
人机交互式机器翻译研究-在线学习方法

在线学习,就是online learning,即时学习用户反馈,一般强化学习,增强学习比较多,我们采用的是基于随机森林的在线翻译模型,是一种投票机制。
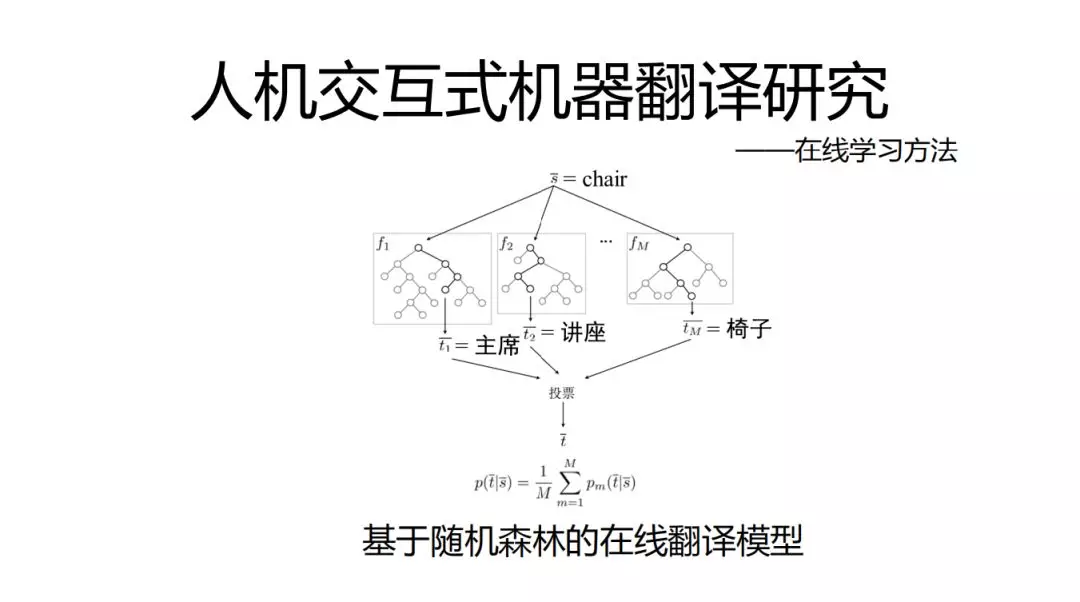
根据信息增益决定决策树上某一支是否要分叉,同时根据当前的错误率决定是否删除某棵树,方法比较简单,主要是基于解决实际问题以及当前可获得的有效资源的角度进行考虑,要找到适合当前环境的方法。
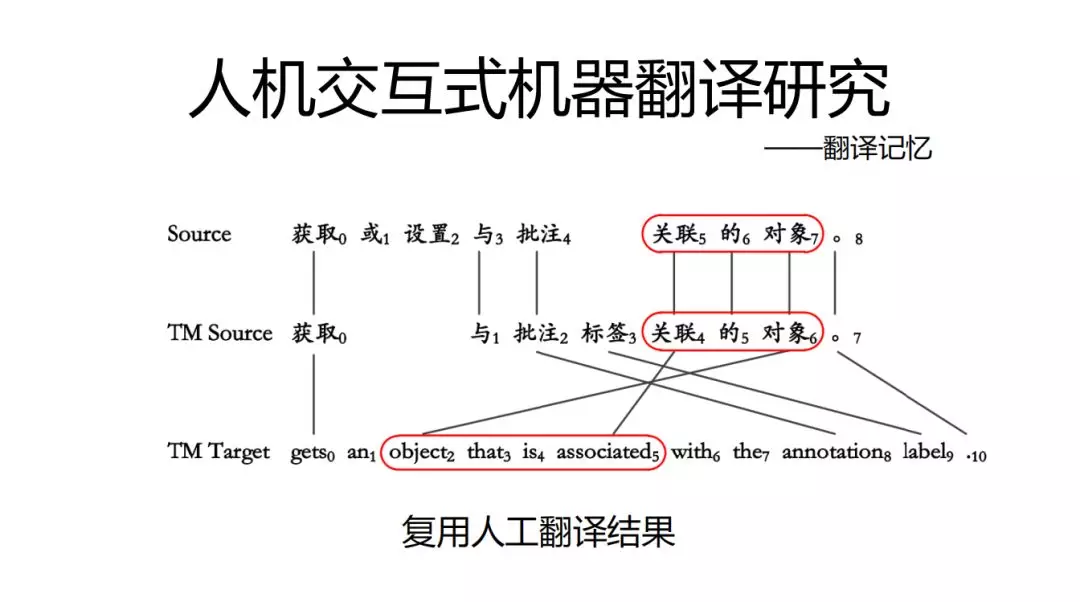
比如说需要翻译的句子A如下:“获取或设置与批注关联的对象”但是之前翻译过这样的句子包含了与A的公共子串“关联的对象”,这样就是如何复用以前的翻译结果?这就是我们需要找到简单、高效、适合当前团队实现能力的方法,我们的方案是容易翻译记忆的NMT(Transformer)如下图:
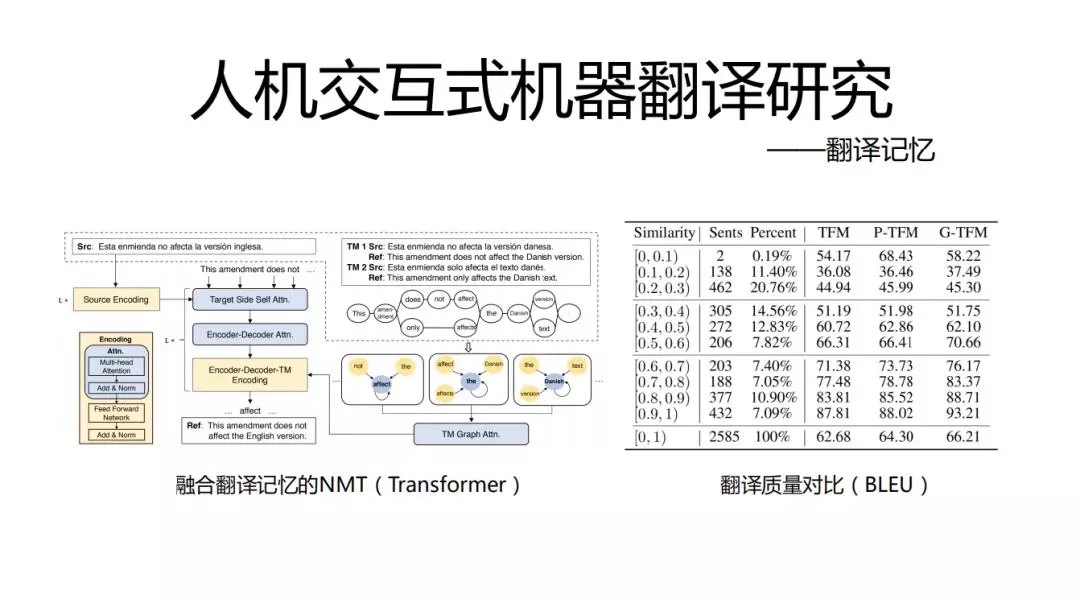
不一定最新的论文就能解决当前团队下我们的问题,很多东西还是要结合实际去思考适合自己的,最后的效果不一定差。
人机交互式机器翻译应用:
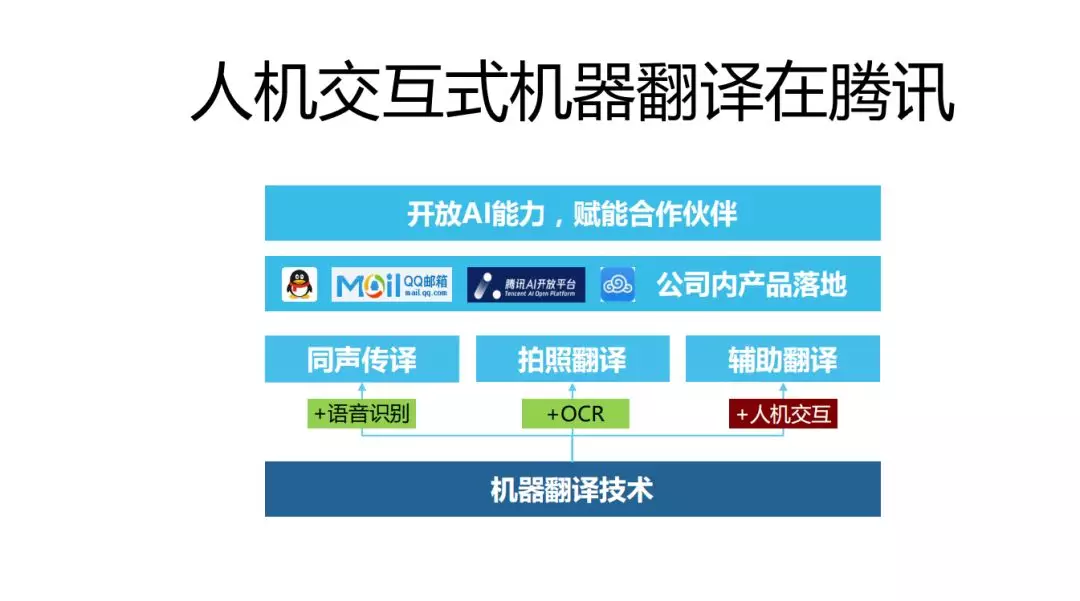
这里主要说人机交互式机器翻译在腾讯的主要应用场�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%BA%E6%9C%BA%E4%BA%A4%E4%BA%92%E5%BC%8F%E6%9C%BA%E5%99%A8%E7%BF%BB%E8%AF%91%E7%A0%94%E7%A9%B6%E4%B8%8E%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


