人半年打造语音识别引擎同城语音识别自研之路
导读:大多数人会认为研发语音识别技术是一条艰难的道路,投入会巨大,道路会很漫长。我们于2019年11月组建了3人团队自主研发语音识别技术,包括2名算法工程师和1名后端工程师,历经半年,自研语音识别引擎效果超过第三方采购厂商,成功打造了58语音识别引擎。本文将分享我们自研语音识别技术历程,望对走在自研道路上的同行有一定借鉴意义。
本文收益:了解语音识别基本概念、语音数据标注、算法模型、工程架构。
背景
近年来,AI智能语音应用在58同城广泛落地。2018年10月,我们研发了智能外呼语音机器人(参见: 人机语音对话技术在58同城的应用实践),在销售、客服、产品运营等场景广泛使用。2019年5月,我们研发了智能语音质检系统,实现对呼叫中心销售、客服电话录音的全量质检。2020年5月,我们将智能语音质检系统升级为智能语音分析平台(代号“灵犀”,参见 人物|詹坤林:语音语义技术打开58同城的另一扇门),广泛接入各前台业务线C端用户和B端商家电话、微聊语音沟通录音,打造各类应用。2020年8月,智能外呼机器人升级为智能语音交互平台,在原始电话语音沟通场景下支持呼入、转人工等功能,并新增支持网络音频沟通场景下的人机语音对话,打造了招聘面试机器人(神奇面试间)。
这些智能语音应用中的语音识别技术初期都是从第三方语音厂商采买,在语音对话场景采买一句话识别(短语音)接口或者实时语音识别(长语音流)接口,这两类接口都属于流式语音识别,可以实现边输入语音流边获得识别结果的功能,在语音分析场景采买录音文件识别,客户端上传录音文件,上传完成后,异步查询识别结果。一句话识别一般按次数收费,实时语音识别和录音文件识别按语音时长收费,如数元每小时,价格昂贵。此外,在采买初期,语音厂商一般会基于需求方业务场景下的语音数据进行定制优化以达到所要求的识别效果,但随着需求方业务场景数据的不断变化,或者新增了一些有差异的场景,语音识别效果会下降,这时候若找语音厂商优化效果,需要再次收费,且较昂贵,非常不灵活,尤其是58同城包含房产、招聘、黄页、车等多条有差异的业务。
在我们的应用中,语音对话场景请求量小,语音数据少,年采买成本为数十万元,我们直接采买了大厂的一句话识别技术。我们最大的应用场景是语音分析,例如呼叫中心销售、客服电话录音时长每年达数百万小时,C端用户和B端商家电话沟通场景数据量更大,所有录音总计近千万小时。2019年7月,我们以一年数百万元的价格采买了一家语音厂商的录音文件识别技术来支持呼叫中心销售、客服录音质检,合同为期一年,到期后续费。
我们的语音数据量庞大,全部采买第三方技术一年花费巨大,并且第三方技术不能灵活支持关键场景的持续优化,因此我们决定自主研发语音识别技术,不仅可以节省采买成本,还可以针对不同业务特性持续定制优化,灵活打造各类智能语音应用。
2019年11月,我们正式组建团队,抽调2名算法和1名后端人员,开始投入语音识别技术研发。2020年5月,我们上线录音文件识别后端服务,6月初,我们的语音识别算法模型效果超过第三方采购厂商,由于和第三方采购厂商的合同为年包合同,不使用也需付费,我们继续使用了一段时间。7月3日,正式全量切换为自研语音识别引擎,在合同截止日的半个月之前彻底替换第三方厂商。自研语音识别引擎使得我们可以更快速、灵活地支持各前台业务需求,我们很快接入了各前台业务线C端用户和B端商家电话、微聊语音沟通录音,快速打造了各类语音应用。12月,我们上线了流式语音识别引擎,支持边说话边识别,识别效果超过第三方语音厂商,在语音对话场景下替换了第三方。
研发思路
近年来,随着深度学习的高速发展,图像、NLP、语音领域都取得了显著的进展,各大企业都自主研发了大量优秀的AI应用,尤以图像、NLP为主,语音类相对较少,这是因为语音技术的门槛相对较高,并且语音人才较缺乏,大部分企业只能选择采买几大巨头语音厂商的技术。尽管我们在半年时间内自主研发了语音识别引擎,但还属于新手,未来还有很大空间,下面从语音团队搭建、语音数据标注、算法模型和工程架构几个方面概览我们的研发之路。
团队搭建:
我们在2019年5月上线智能语音质检系统时就有自研语音识别技术的想法,但是团队内大部分是NLP工程师,无语音领域人才,并且团队AI项目多且工期紧,无足够精力来研发语音识别。初期我们准备通过招聘来搭建语音团队,但是因为这个团队需要从零开始搭建,难以吸引语音技术负责人的加入,我们的招聘持续了几个月,都很不顺利。2019年11月中旬,我们决定先行上路,从团队抽调了1名资深NLP算法工程师和1名资深后端工程师,同期招聘了一位具备不错语音基础的初级工程师,组成3人团队,开始语音识别技术的调研和研发。NLP和语音领域有很多相通之处,通过不断学习,我们很快摸清了语音识别的研发方法。
数据标注:
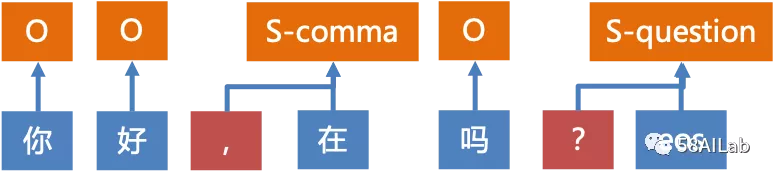
语音识别模型强依赖语音数据,训练一个好的语音识别模型需要有充足、高质量的语音标注数据,即人工标注好的语音片段和对应文字,一般情况下,标注的语音数据字准率需要在98%以上。初期,我们使用开源语音数据集来做模型实验,如AIShell-1、AIdatatang_500zh、THCHS30等。2019年11月底,我们上线了一套基于Wavesurfer.js插件开发的语音数据标注系统,如下图所示,并搭建了4人标注团队来标注我们业务场景下的语音数据。标注系统有标注员、质检员、管理员等多种角色,支持标注任务分配、标注、质检、数据统计等功能。为提高标注效率,我们利用第三方语音识别接口(也可使用大厂免费语音识别接口)对语音文件进行转写,将转写文本展示在系统中,标注人员标注时只需要对文本进行改写,而不是从零开始听录音写文字,标注员人均单日可标注1小时左右的有效录音,标注的录音会交由质检员做质检以保证准确率,质检员人均单日可质检1.5小时左右的有效录音。在我们的场景下,有效录音指仅包含主叫与被叫的可听清人声,可以包括轻口音的方言,或背景中清晰干净的人声等。除此之外,还需要标注员标注上说话人标签,例如说话人性别、说话人角色(用户、坐席)等,说话人标签标注准确率不可低于98%。
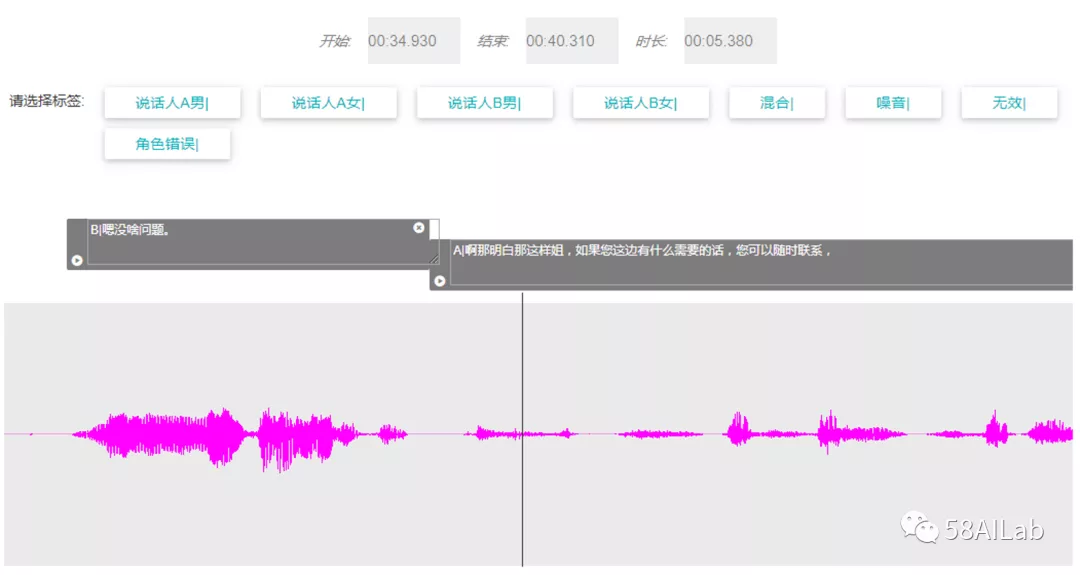
我们标注团队每天仅能标注3~4个小时的语音数据,而训练一个较好的语音识别模型往往需要数千甚至上万有效小时的语音数据,我们预估我们的场景下初期需要3500+小时有效录音,自主搭建标注团队标注成本过高,且标注周期长,业界有众多第三方语音数据标注厂商,成本相对较低,1小时有效录音价格为数百元,我们决定将语音数据标注工作外包给第三方厂商来做。
我们从2020年2月初就开始筹备语音数据标注外包工作,但由于疫情原因,直至2020年4月初,我们才成功招标一家语音数据标注厂商,我们要求其在3个月内完成3500小时语音数据的标注,以支持我们在7月份上线自研语音识别。我们的场景繁杂,总计有17个细分场景,包括房产、招聘、黄页、车四大业务线销售、客服人员在呼叫中心的电话录音,四大业务线C端用户和B端用户在58同城平台的电话沟通录音,这些都是8kHz的语音数据,此外还包括四大业务线C端用户和B端用户在微聊中的沟通语音,这是16kHz的语音数据。我们的目标是在所有场景都要超越第三方,我们不能盲目标注语音数据,需要覆盖所有场景,因此我们根据场景优先级将3500小时的任务进行拆分,重点场景标注多,其余场景标注少,此外,我们还制定了一个批次计划,分批次将语音数据给到标注厂商,我们在拿到每个批次的数据后就会训练模型,评测效果,若某个场景超越第三方,我们可以灵活调整后续批次中各场景的数据分布,例如在效果较差的场景多标数据,通过这种方式我们可以灵活把控我们的算法迭代节奏。值得一提的是,2020年6月初,我们基于外包标注的1700小时语音数据训练了语音识别模型,整体效果超过了第三方语音厂商,17个细分场景中仅3个非重点场景比第三方略低。
在具体数据标注工作中,第三方标注厂商会利用我们的标注系统做标注和质检,然后交付结果数据,对于第三方交付的数据,我们自建的人工标注团队会随机抽取一定比例的数据做质检,只有语音数据字准率不低于98%、说话人标签数据准确率不低于98%时,才会完成最终交付,否则所有数据会打回第三方重新标注。6月底,第三方完成了3500小时的语音数据标注,有效支撑了我们的模型迭代。此后,我们继续开展了数据标注,因为业务场景数据会持续变化,我们需要不断捕捉变化,只是需求量不再像初期语音识别模型冷启动时那么大,每天标注数十小时数据。当前,我们积累了超过5000小时的语音数据。
算法模型:
在2009年之前语音识别主要使用HMM-GMM模型,从2009年开始深度学习算法逐渐发挥优势,HMM-DNN模型成为主流,发展至2015年,端到端的语音识别模型开始出现,相比先前的模型包括特征提取、声学模型、语言模型、解码器多个模块,端到端的模型从输入到输出只有一个算法模型,输入是语音信号,输出是识别的词序列结果。我们选择了Kaldi语音识别框架来搭建我们的语音识别引擎,并选择被大家广泛使用的Chain Model作为我们的主要模型,Chain Model属于传统的HMM-DNN模型,是Kaldi之父Daniel Povey推崇的模型,在语音识别上取得了稳定的效果。在端到端模型上,我们也进行了探索,主要实践了ESPnet开源框架里的各类模型,在部分场景识别效果优于Chain Model,但由于解码效率问题,当前未广泛使用,下文中具体描述。
工程架构:
我们基于Kaldi实现了录音文件识别、实时语音识别服务,服务基于docker和grpc部署,支持CPU、GPU解码。在录音文件识别上,CPU机器上使用Kaldi中的nnet3-latgen-faster-parallel解码器,GPU机器上使用Kaldi中的batched-wav-nnet3-cuda解码器。在实时语音识别上,我们优化了Kaldi中的online2-wav-nnet3-latgen-faster解码器,实现了CPU机器上的实时解码,2020年12月,在智能外呼、招聘面试机器人(神奇面试间)等语音对话场景下我们替换了第三方语音技术。工程架构部分在下文中具体描述。
算法模型
58场景下的语音数据主要来源于8K的电话录音和16K的网络音频,为了保证语音识别系统的通用性,我们在训练和识别时,统一将所有音频转为16K的采样率,以实现混合带宽场景下的语音识别。
语音识别系统主要模块可以分为语音活性检测(Voice Activity Detection,VAD)、说话人分离(Speaker Diarizition,SD)、语音识别(Automatic Speech Recognition,ASR)和后处理模块。以下主要介绍各个算法模块的功能,以及迭代过程中遇到的困难和解决方案。
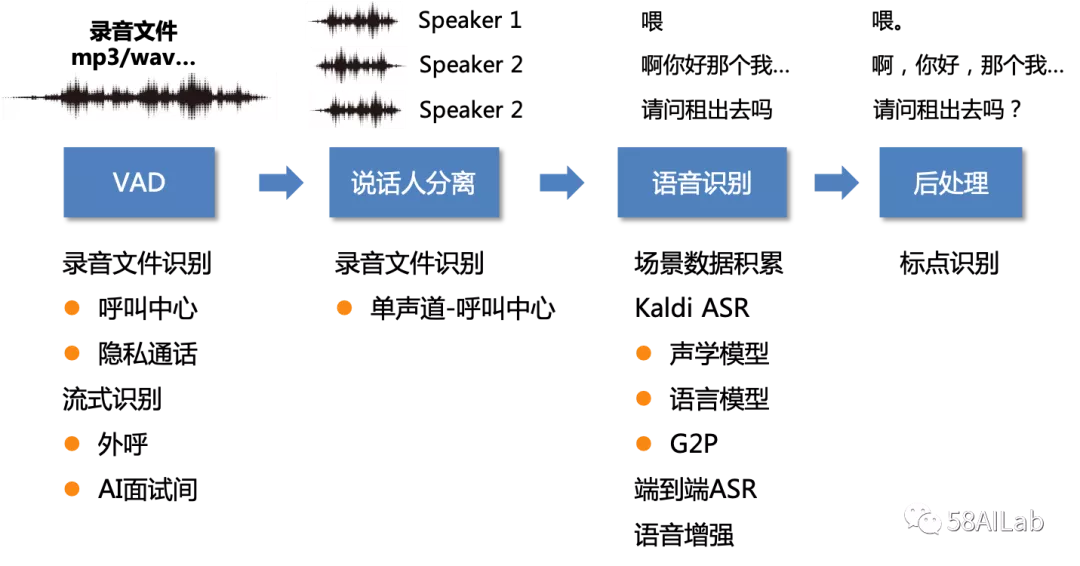
语音识别(ASR)模块将输入的音频转为对应的文字,为整个系统的核心。我们选择Kaldi的Chain Model 作为语音识别框架,模型主要分为声学模型、语言模型和发音词典。
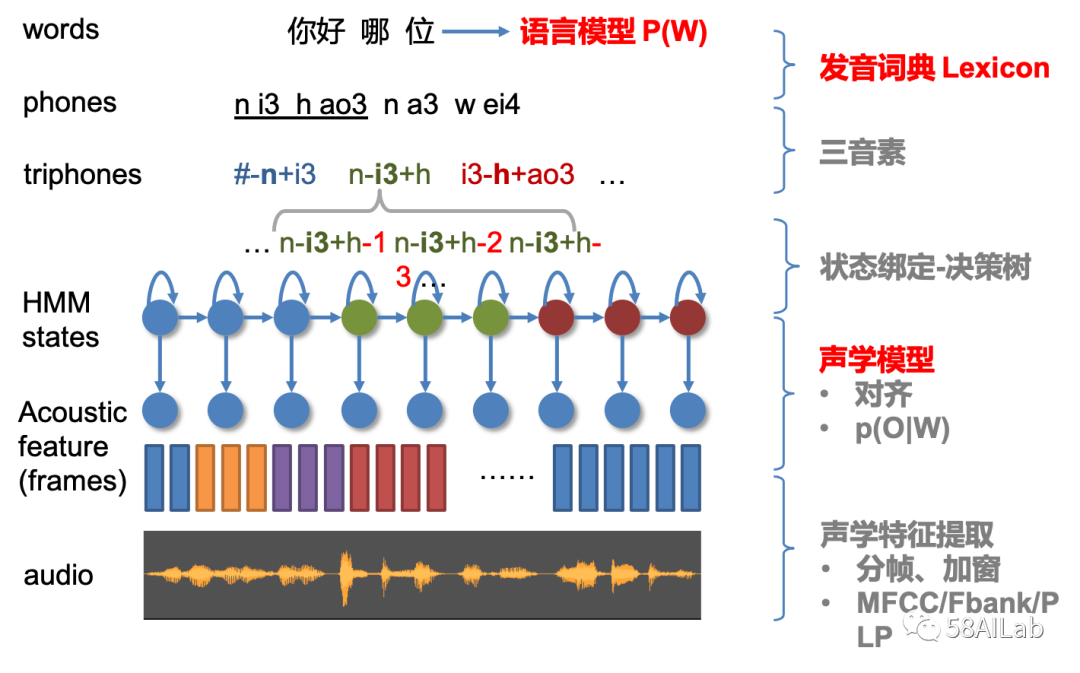
模型迭代前期,主要是针对声学模型进行迭代,我们采用CNN + TDNN-F作为主要的语音识别模型。在模型的冷启动阶段,主要是通过各场景数据积累使字错率(Character Error Rate,CER)绝对下降10%左右,而在数据积累到一定程度后,各场景的CER呈现细微波动而很难进一步下降,这个阶段主要通过特征和模型的大量调优实验获得进一步的性能提升。
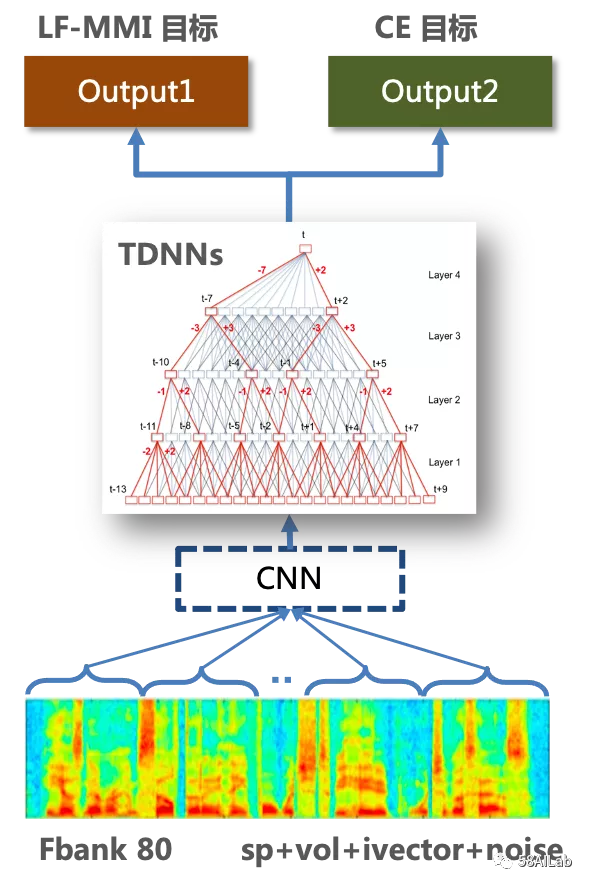
由于语音数据积累和声学模型的迭代周期较长,因此针对特定场景的识别效果优化,我们主要依靠语言模型和发音词典的快速迭代。我们开发了G2P(Grapheme-to-Phoneme,文字转音素)服务,实现了中英文音素的标准化、数字标准化,使用seq2seq模型实现对多音字的处理,借助新词发现算法构造了大量的业务发音词典,增加了业务专有词汇在解码图中的概率。从语言模型角度,使用不同场景数据训练多个语言模型插值,通过调整插值系数可以优化不同场景下的识别效果,对于数据少的场景,通过 rnnlm 扩充训练数据,可以有效弥补数据的不足,最终成功优化了语音标注数据少的场景下的识别效果,如招聘面试机器人(神奇面试间)、智能外呼场景。在电话音频数据中,存在很多噪音,通过噪音分析,整理了业务场景的噪音类型,针对性的进行训练数据加噪,结合变速、谱增强等数据增强方法,有效的提高了模型在复杂环境下的鲁棒性。
后处理模块的主要功能是为识别文本加标点,增加了识别结果的可读性,我们使用实体识别对标点任务建模,通过自标注数据的训练,达到了很好的效果。
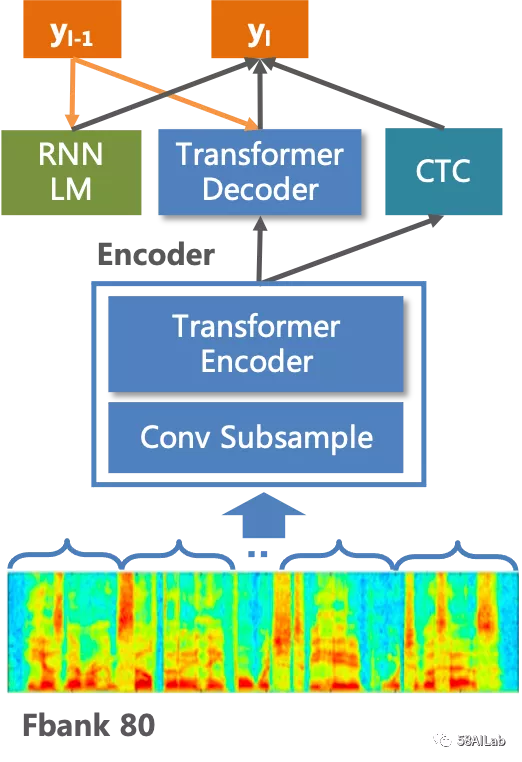
在端到端语音识别上,我们尝试了多种方案,其中基于ESPNet实现的Transformer + CTC的方法整体效果最优,如下图所示。ESPNet中解码速度较慢,我们通过实现批量解码、实现预测时的动态batchsize分配、优化下采样策略、调整beam-size、实现Attention辅助对齐等方法使端到端解码效率绝对提升60倍。
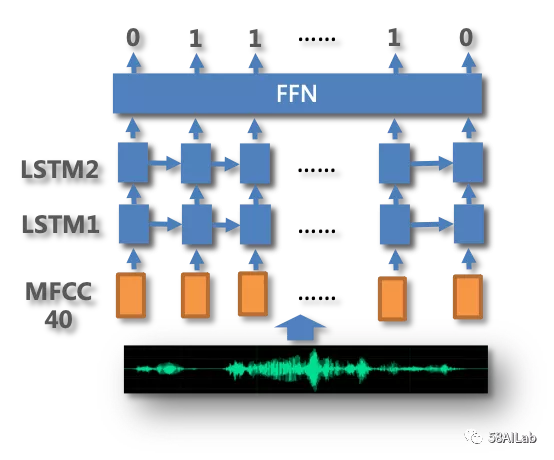
VAD模块的任务是从一段录音或者语音流中找到并提取人声部分,VAD在录音文件识别和实时语音识别中都会应用到,所有的音频数据首先经过VAD模块处理,只有被VAD判别为“人声”的音频才会流转至ASR模块转译成文字,它是语音识别系统的第一道关口。能否精确的判断人声的起始位置,并在复杂场景中有效过滤噪音等非人声片段是VAD的核心任务。电话场景的环境音非常复杂,除了常规的噪音之外,还有机器人的回声、背景电视音乐声等等。我们最开始使用webrtc中的VAD模块配合合适的平滑策略实现,webrtc的效率高、效果稳定,但对噪音的过滤效果较差。因此,后期采用了深度学习的方法,通过自有训练数据提升对特定噪音类别的过滤能力。为了兼顾性能和效率,经过大量实验,VAD模型最终使用双层单向lstmVAD对每一帧音频进行打标(即判断是否为人声),如下图所示,与webrtcVAD相比在很大程度上提升了噪音过滤能力,同时可以识别并过滤掉录音中的机器人声、以及回声消除的“残留物”。
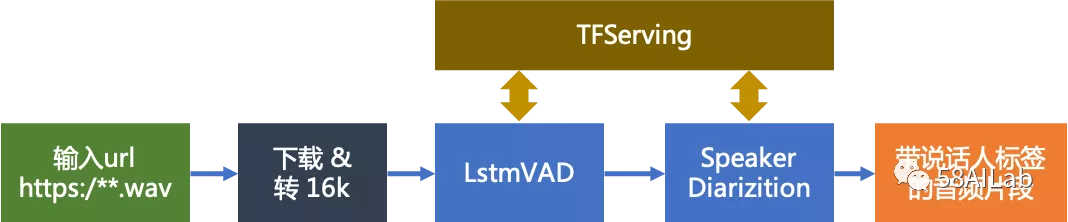
作为语音识别系统的第一道关口,VAD的预测耗时要求很高,我们针对VAD耗时做了优化。在录音文件识别场景下,主要问题就是每个录音的长度较长,对于lstm来说耗时较高,我们应用了分段延时预测LSTM,同时使用CUDNN加速,实现对长录音的并行预测,同时又保证了识别效果与整段预测相同。在实时语音识别场景下,VAD则通过窗口切分后,记忆对话内的上下文状态信息,同时有效的控制了传输耗时,在降低整体预测耗时的同时保证识别效果不受影响。
SD(说话人分离)模块应用于分离单声道录音中的两个说话人,为了分离不同说话人的发音片段,SD在拿到VAD的人声片段后,根据说话人特征进一步切分、聚类和平滑。SD的主要难点在于强噪音干扰、说话人音量差别太大以及背景人声较多等问题,优化SD模块主要就是优化说话人身份向量的提取,再由KMeans根据通话中说话人数量完成聚类。说话人向量表示方面,我们从IVector迭代到深度学习版本,网络方面使用ResNet在VoxCeleb数据上的预训练模型,结合DSSM、Triplet等方式在自有数据上微调,增大实际场景下不同说话人之间的区分度,最终获得了大幅度提升。
VAD和SD的级联方式最初使用 webrtcVAD + IVector PLDA + KMeans的方式,但分离效果受到说话人音量、噪音、环境音等因素影响严重。使用基于ResNet的说话人向量表示模型与lstmVAD级联后,与webrtcVAD+IVector的方案相比,分离错误率(DER,Diarization error rate)绝对降低10%。
未来我们会进一步在多场景、多方言、多口音的场景下进行深度优化,持续跟进业界前沿技术。本文由于篇幅限制,未详细描述相关技术细节,未来会持续输出相关文章。
工程架构
语音识别引擎在工程架构上主要包括录音文件识别服务、实时语音识别服务。录音文件识别服务将批量录音文件作为输入,识别完成后,将整段录音的识别结果回传。实时语音识别服务将语音数据流作为输入,实时返回识别结果,达到边说边识别的效果。
语音识别引擎架构如下图所示:在接入层上,对于录音文件识别服务,我们提供了接收请求的RPC接口,以及查询识别结果的HTTP接口,对于实时语音识别服务,我们提供了Java/IOS/Android版本的SDK,供业务方调用。在逻辑层上,录音文件识别服务、实时语音识别服务提供核心的文字转写功能;接入了日晷ABTest平台,用于线上模型分流,对比线上效果;接入了WPAI人工智能平台,用于非Kaldi框架模型的训练、推理。在数据层上,我们使用各类存储系统,完成服务配置、数据存储、数据统计。
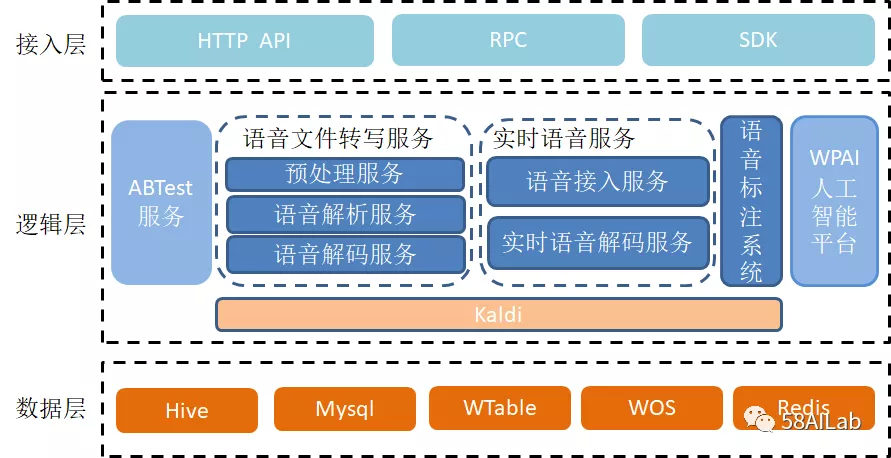
录音文件识别服务:
录音文件识别服务对录音文件进行批量转写,一般包括回调、轮询两种设计方式。在回调方式下,由调用方将HTTP服务的回调地址作为参数发送给服务方,服务方转写完毕后将结果返回。在轮询方式下,调用方发送转写任务请求后,不断请求服务方是否转写完毕,如果转写完毕,则将结果取回。我们采用了回调的设计方式,这样的好处是避免了无效的请求和服务端资源的浪费,异步提交的方式对调用方的服务设计也是友好的。
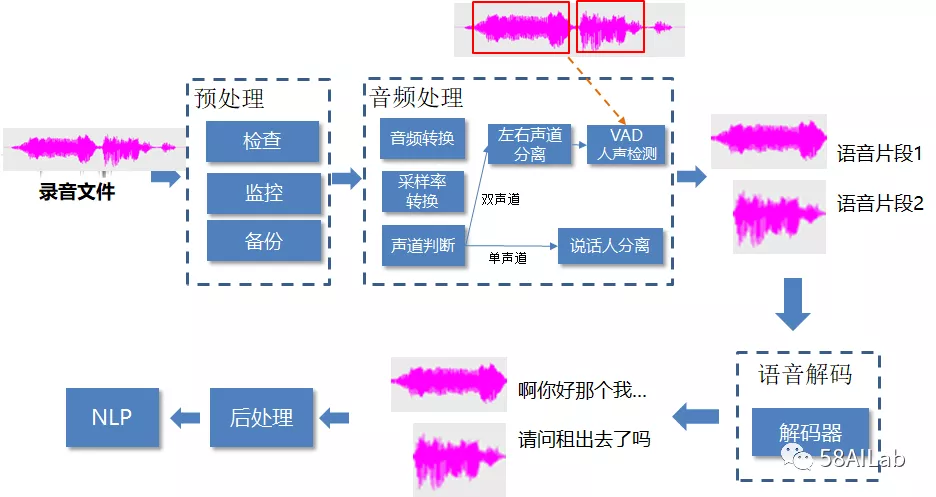
录音文件识别服务包括预处理服务、音频处理服务、语音解码服务以及后处理服务。录音文件识别服务流程如上图所示:录音文件请求发送至预处理服务(RPC)上,由预处理服务进行鉴权、有效性检查、时长监控及消息备份。在音频处理服务上,对音频进行转换,统一转换为16k/16bit pcm格式文件,进行声道判断,如果是双声道录音,则先进行声道分离再进行VAD,将语音切分为说话人语音片段,如果是单声道录音,则进行说话人分离(SD),再进行vad人声检测,切分为说话人语音片段。语音解码服务处理输入的说话人语音片段,进行解码,再调用后处理服务添加标点,将结果回传给调用方,在语音解码中,我们使用批量解码器,对人声语音片段进行批量转写。
我们使用了Kaldi中的解码器,CPU机器上使用nnet3-latgen-faster-parallel解码器,1小时可以解码20小时音频,GPU机器上使用batched-wav-nnet3-cuda解码器。
实时语音识别服务:
实时语音识别服务可以实现边说话边返回识别结果,服务包含客户端SDK、实时语音接入服务、实时解码服务三个部分。如果要提供实时的流式服务,就需要客户端和服务间建立全双工的长连接以流式的方式交互数据。SDK和服务间约定了事件、回调函数、以及返回转写状态。相应的,我们开发了Java/IOS/Android版本的SDK,适用于不用的调用需求。语音接入服务还包括鉴权、限流等功能。实时语音解码服实现对接收的语音片段进行实时解码,后处理服务对转写出的结果添加标点。
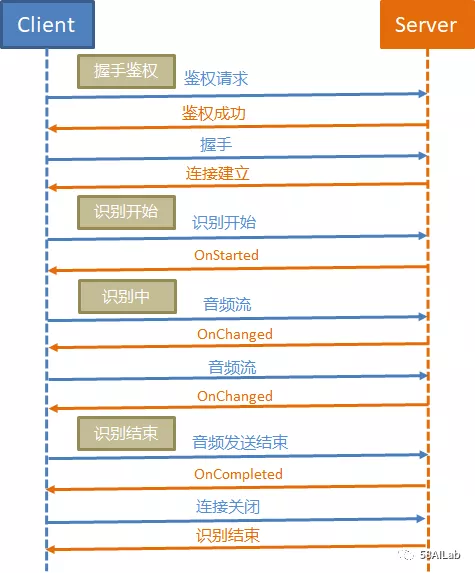
实时语音识别场景下客户端和服务端交互流程如上图所示,首先进行握手鉴权,服务端根据token和签名来判断是否为合法请求,然后开始识别,定义了识别开始、识别进行中、识别结束、识别失败四种状态来控制整个流程。值得一提的是,该交互流程实际为云厂商中的一句话识别流程,基于该流程加上VAD即可实现云厂商的实时语音识别。
我们对kaldi原生的解码器online2-wav-nnet3-latgen-faster进行了改造, Kaldi原生的语音解码器性能差,没有并发处理能力,无法在生产环境中直接使用。我们对解码器进行了一系列优化改造使得单机解码性能提升一倍,并构建了基于多线程的流式语音识别服务,同时优化了在边说边识别过程中获取中间识别结果的耗时,最终流式识别服务在生产环境中正常上线。
在流式语音识别解码服务上我们做了如下的优化:
(1)Kald开源框架中的解码器仅能接受完整的音频文件作为输入,是一个基础API。实现了对流式音频的处理能力,并基于多线程实现了实时解码服务,每个线程对应一路解码器。
(2)解码服务中原始解码器性能低下,解码服务会随着并发路数的增加耗时逐渐升高。在32核物理机上最多支持16路并发,16路并发以上耗时会有较大升高。这里做了如下优化:
- 通过调整解码器参数降低了解码网络搜索规模。
- 在解码网络中选择路径时,去除了对于选择路径无关的音素和词的遍历,降低了网络搜索耗时。
- 修改内存分配/释放方式,使用tcmalloc代替原始的malloc,减少了内存碎片、降低了内存操作耗时。
最终使得解码并发路数可以和物理机CPU核数相等,并可以保证语音识别准确率维持不变,在物理机器上,可支持CPU核心数相等的并发路数。在相同测试集下对比优化前后流式解码耗时,由567ms降低至97ms。
(3)优化了在边说话边识别过程中获取中间识别结果的耗时。流式语音识别在边说边识别过程中获取中间结果是一项基础能力,应用方可以不用等整句通话结束即可提前获得中间识别结果以做灵活的语义分析,如在通话过程中客服持续辱骂用户可快速识别并自动转接电话。原始解码器在获取中间结果上存在两个问题:
- 获取每次中间结果的性能差、耗时高。
- 每次发送给解码服务的语音单位时长影响获取中间结果的耗时,单位时长越长,获取中间结果的耗时越高。获取每次中间结果耗时高,持续积累后,当用户说话结束时获取最终识别结果的耗时会越长,会出现用户说话结束了但最终结果还没解码完成的情况,大大影响用户体验。
通过分析源码发现原始实现方式每次获取中间结果时都是从整个词图(lattice)中搜索最优路径,耗时较高。优化为从已经走过的最优路径中回溯出一条最优路径,使得获取中间结果的耗时低且稳定,不受发送给解码服务的语音单位时长大小的影响,且不影响返回最终识别结果的耗时。在相同测试集下对比获取中间结果的耗时,每次给解码服务发送的语音单位时长为100ms时,平均耗时从优化前的104ms降低至18ms。
当前,我们已经在语音对话如招聘面试机器人(神奇面试间)、智能外呼场景下上线了自研实时语音识别服务,替换了第三方语音厂商。
总结和展望
以往我们总认为自研语音识别技术是一条艰难的道路,投入会巨大,道路会很漫长,总是不敢踏出第一步。最终我们走下来发现并非开始想象的那么难,这得益于团队成员持续学习的精神,以及当下我们处在一个技术开放的时代,我们从开源社区、业界技术沙龙吸取了前人成功的经验。
自2019年11月我们抽调2名算法和1名后端人员正式组建3人团队开始,至2020年6月初我们的语音识别模型效果超过第三方采购厂商,刨除期间春节假期和疫情休假等,我们大约花了半年时间,真正实现3人在半年时间研发了一套语音识别引擎。由于疫情原因,我们的社招不是很顺利,6月之后,我们通过校园招聘和社会招聘引入了多名人才,当前团队规模达到8人。
自研语音识别技术打开了58技术的另一扇门,使得我们在语音这一领域有广阔的发挥空间,可以灵活地支持各前台业务需求。作为半路出家者,未来我们将继续持续学习,跟进业界前沿,优化效果,并不断引进优质人才,扩充团队,打造声纹识别、语音合成等新的语音技术,为58同城产业化转型贡献力量。
附语音技术团队照片一张,欢迎加入我们!
欢迎联系:zhankunlin@58.com

作者简介
詹坤林,58同城AI Lab负责人、算法资深架构师、技术委员会AI分会主席。2015年5月加入58,目前主要负责AI相关产品规划和技术研发,致力于推动AI技术在58同城的落地,打造AI中台能力,以提高前台业务人效、收入和用户体验。目前负责的主要产品包括智能客服、语音机器人、语音分析平台、语音识别、智能写稿、AI算法平台、CRM商机智能分配系统等。曾任腾讯高级工程师,从事推荐算法研发。2012年硕士毕业于中国科学院大学。
周维,58同城AI Lab算法资深工程师。2018年5月加入58,目前主要负责语音识别算法研发,曾先后从事智能客服、语音机器人、写稿机器人算法研发。2016年硕士毕业于中国科学院大学,毕业后参与AI方向创业,从事对话机器人算法研发。
王焱,58同城AI Lab后端架构师。2017年2月加入58,目前主要负�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%BA%E5%8D%8A%E5%B9%B4%E6%89%93%E9%80%A0%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB%E5%BC%95%E6%93%8E%E5%90%8C%E5%9F%8E%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB%E8%87%AA%E7%A0%94%E4%B9%8B%E8%B7%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


