京东线性模型的重构与优化实践

分享嘉宾:郑瑞峰 京东 资深算法专家
编辑整理:乔伊 51job
出品平台:DataFunTalk
导读: 随着机器学习乃至深度学习的火热发展,Spark家族中的Spark-ML频频出圈。Spark-ML是基于Spark Core与Spark SQL的机器学习库。因为其简单易用而被广泛应用于离线批处理的训练场景下。为了使其更高效地落地于生产项目,也为了使我们的工作服务于大众,Project Matrix应运而生。它针对Spark-ML线性模型进行重新审视与重构,下面将具体介绍我们目前的工作成果,以及对于后续工作的展望。
今天的分享围绕下面三点展开:
- 背景介绍
- 优化进展
- 未来规划
01 背景介绍
首先和大家分享下Spark机器学习库的现状和Project Matrix项目背景。
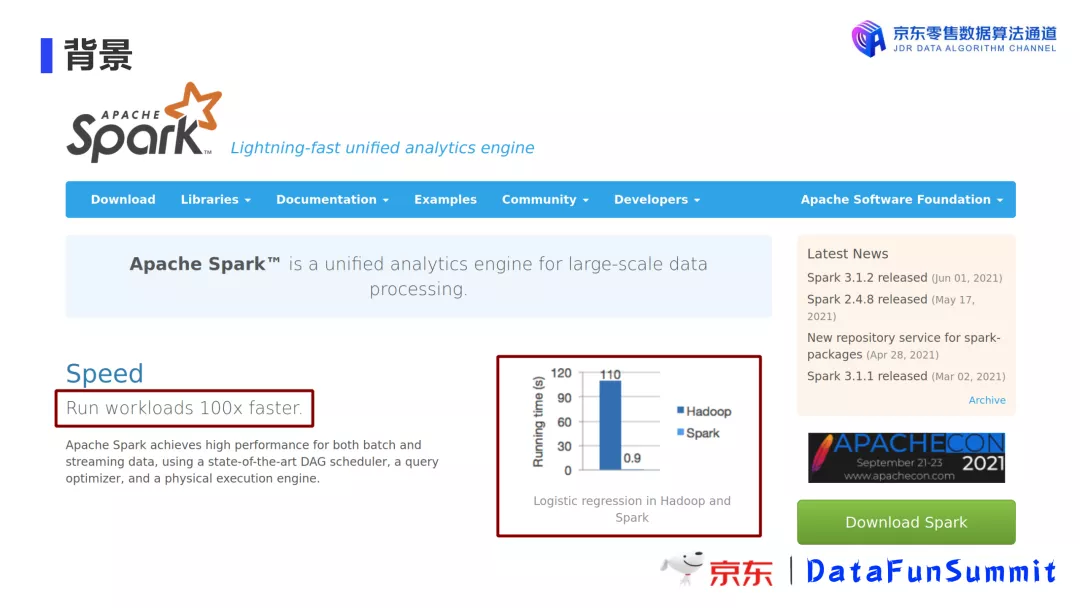
1. Spark vs Hadoop
Spark因为其基于内存的天生优势,在迭代计算的场景下胜出于Hadoop百倍千倍。
2. Spark-ML在京东的主要应用
Spark非常适合批处理与预测任务,使用简单的机器学习模型,可以快速满足某些需求,可解释性很强,且训练成本低廉。
目前,Spark-ML 在京东主要应用于以下场景:
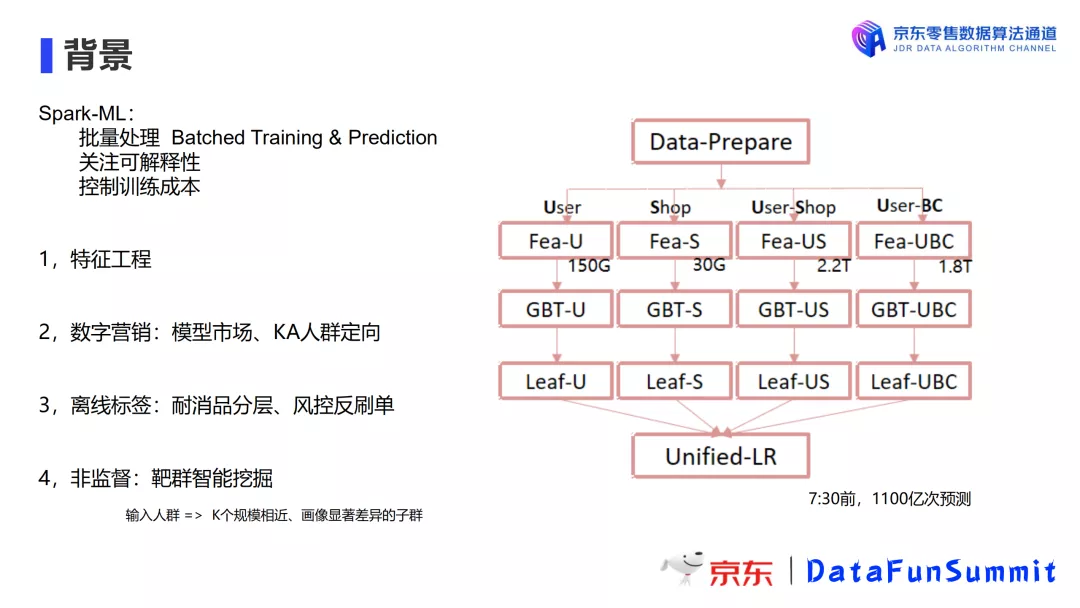
- 特征工程:SparkSQL结合Spark-ML构建特征工程,且Spark-ML提供了丰富的特征提取功能。
- 数字营销:模型市场、KA人群定向。在特征工程的基础上使用Spark-ML进行人群定向营销,根据用户过去30天行为,为店铺推荐合适的潜在用户。因为特征数量巨大难以join,我们借鉴Facebook的经典工作并加以改进,我们训练多个GBDT并进行线性加权。目前我们每天的预测次数达千亿以上。
- 离线标签:耐消品分层、风控反刷单
- 非监督:靶群智能挖掘。数据挖掘场景,例如使用k-Means将输入的10w人群分成k个规模相近、但是画像具有显著差异的子群。
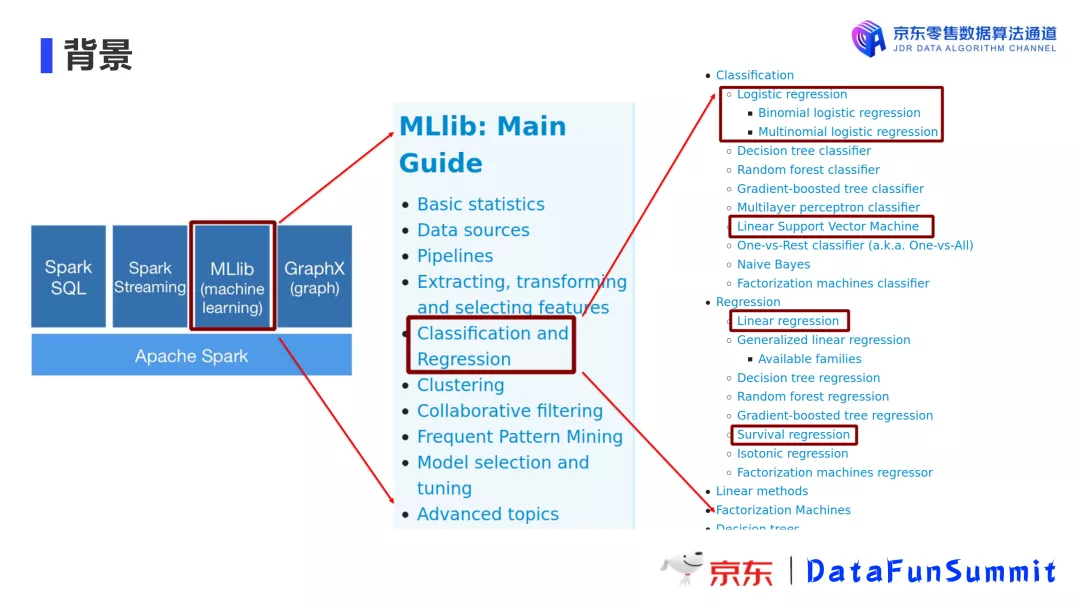
3. 优化重点
针对上述应用场景,我们选出以下四个最常用的线性模型进行优化。它们分别是:
- Logistic Regression
- Linear Support Vector Machine
- Linear Regression
- Survival Regression
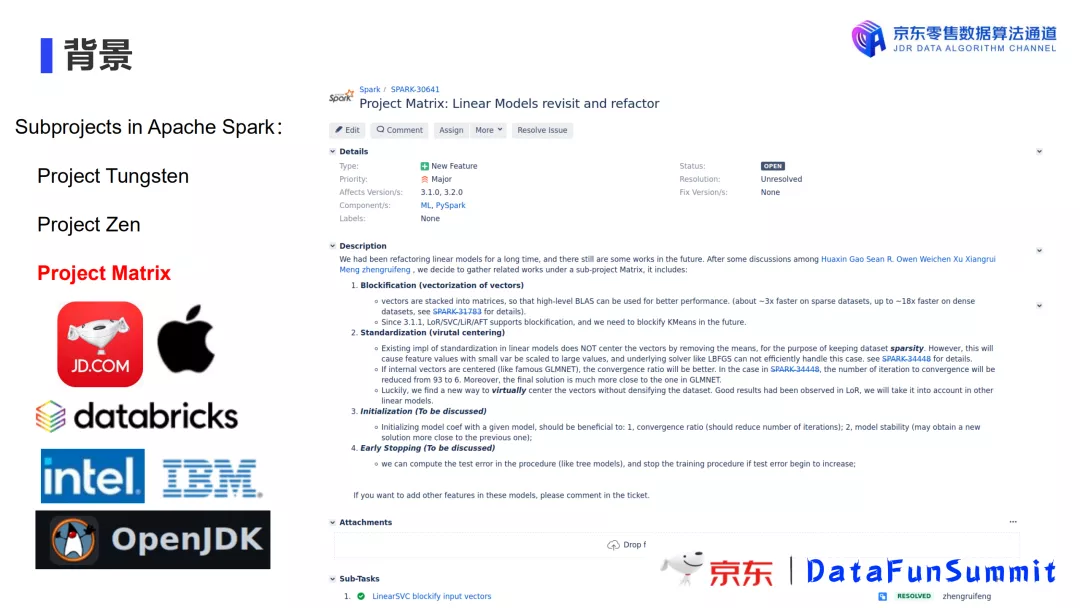
4. Project Matrix项目由来
自2015年以来,Spark-ML就没有很大的改动,我们在具体使用中也真真切切地遇到了一些问题。随着使用地愈加深入,对于它的改造工作也愈加迫切。秉持“人人为我,我为人人”的开源理想,我们决定成立一个新的项目——Project Matrix,专门针对Spark-ML的线性模型训练进行重构与优化。很高兴我们的工作获得了社区的广泛关注与支持。
02 优化进展
大家对算法的期待必定是“又快又准”。下面就从这两个方面展开介绍我们的优化工作。
1. Blockification
首先,Spark原生适合批处理计算,原有ML中的算法往往是逐条处理。提到批处理就不得不引出向量化(Vectorization)这个概念。通俗来讲,通过向量化的方式处理数据,相当于把本来按条处理的数据改为按批处理。举例来说,Spark支持Parquet、ORC文件的向量化读(vectorized read)。Spark在与Python和R的交互中使用ApacheArrow,使得数据可以更好的在外部程序中共享。上述都是Spark通过向量化处理对性能进行的优化。
那么,如何将向量化运用到Spark-ML上来?
向量化是减少代码for循环的艺术。在回答上面这个问题之前,这里先简单介绍下Spark-ML的训练过程。以逻辑回归为例。一个完整的训练过程需要以下三步:
① 初始化参数,也就是模型的系数;
② 根据选择参数指定优化器,一般是LBFGS、OWLQN等;
③ 分发模型到各个节点进行计算:
- 各个分区数据计算Grad与LOSS
- 节点上分区内数据聚合并传回driver端
- driver端根据计算的全局梯度进行模型系数的调整
- 循环直到模型优化完毕
现在来继续讲解我们的优化过程,在Spark 3.1版本之前,模型计算使用的数据存储对象是Instance,它包含标签、权重和特征矢量。
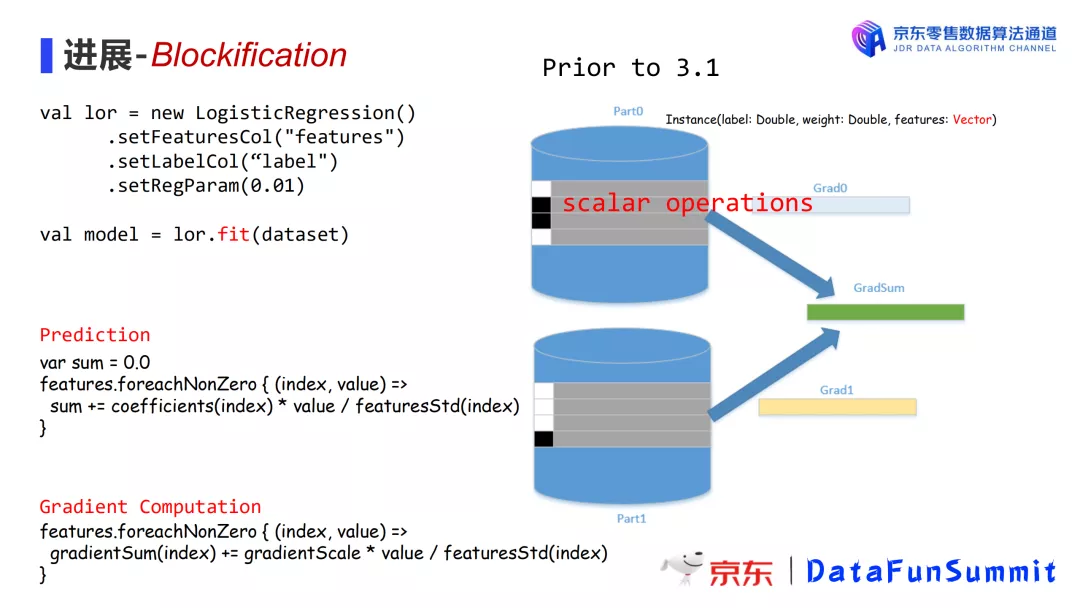
基于3.1版本,我们对模型训练的整个过程进行重构。
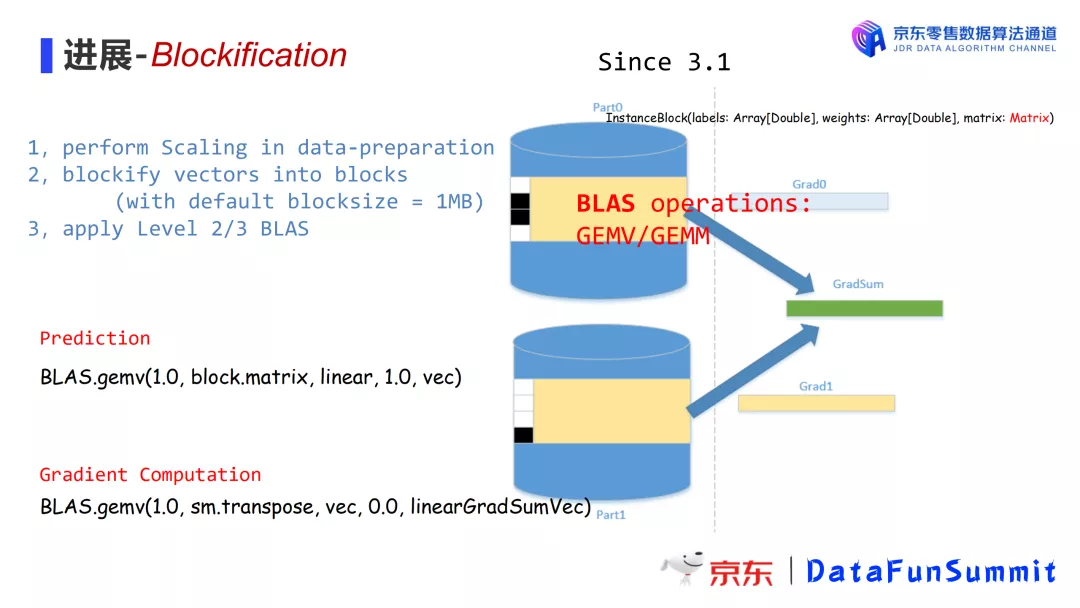
主要工作有:
-
Perform scaling in data-preparation:
数据缩放;
-
Blockify vectors into blocks(withdefault block size:1MB):
批量将向量压缩成矩阵;
-
BLAS(Basic Linear Algebra Subprograms):
优化使用线性代数计算库
什么是BLAS?
BLAS(Basic Linear Algebra Subprograms)是一系列基本线性代数运算函数的接口标准。这里的线性代数运算分别指:
- Level 1:矢量的线性操作
- Level 2:矩阵乘以矢量
- Level 3:矩阵乘以矩阵
目前,BLAS标准只针对稠密的数据。Spark-ML目前在处理稠密数据时,调用java的netlib,netlib会优先寻找native实现(也就是寻找openblas,或者是intel的mkl),如果找不到则使用java原生实现f2j。当处理稀疏数据时,则调用scala自己实现的API。
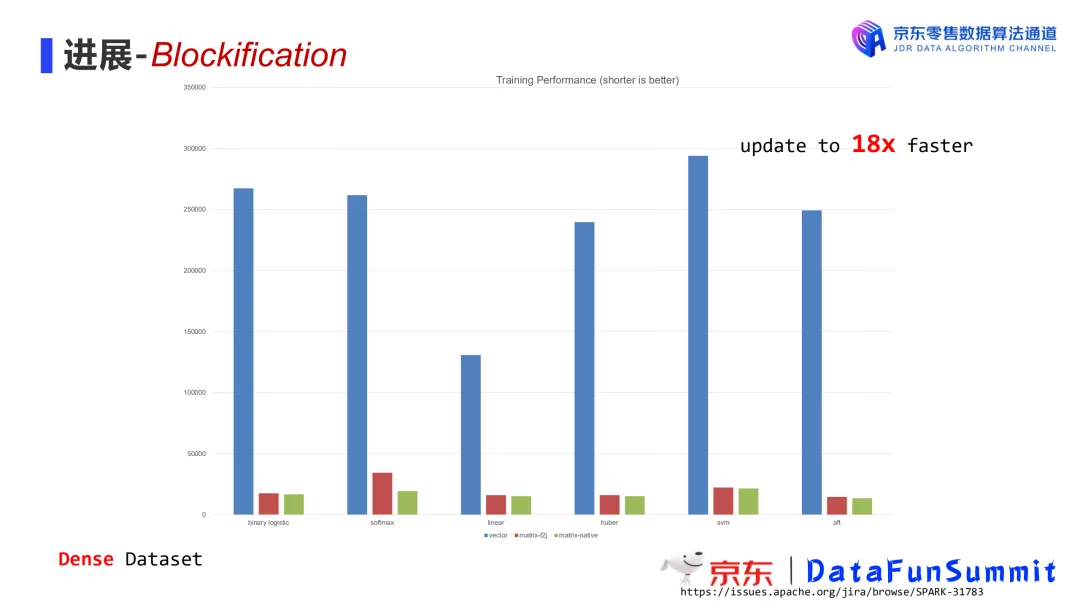
完成上述优化之后,我们的模型训练性能已经得到了显著提升。对于稠密数据集,提升达到18倍。下图中蓝色为原始的训练时长,红色为使用matrix-f2j,绿色为使用matrix-native。
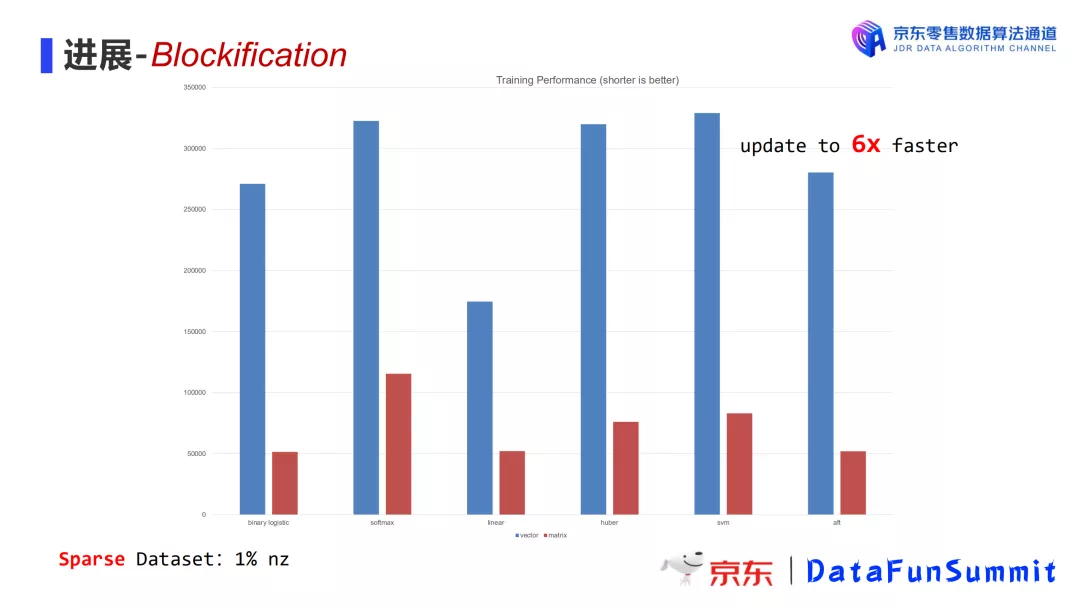
在稀疏数据上,无法获得和稠密数据一样的效果提升,但是新方法总体性能依然能提升3-6倍。下图中使用的数据稠密度为1%。
目前,上述优化都已经集中于3.1版本中发布。
2. Virtual Centering
3.1上线以来,我们得到很多用户的正向反馈。但是在今年收到一条投诉(SPARK-34448)引起了我们的重视,用户反馈的case中对比GLMNET,Spark-ML模型系数训练的不够准确。所以我们参考R语言的GLMNET代码库,继续优化Spark-ML线性模型实现。经过对比与深度地剖析我们发现,GLMNET在训练模型系数的时候不仅对输入数据进行了缩放,还进行了标准化,而Spark MLlib和Scikit-Learn因为性能原因,只进行了缩放。一般而言,标准化会使得线性模型的优化更准确。
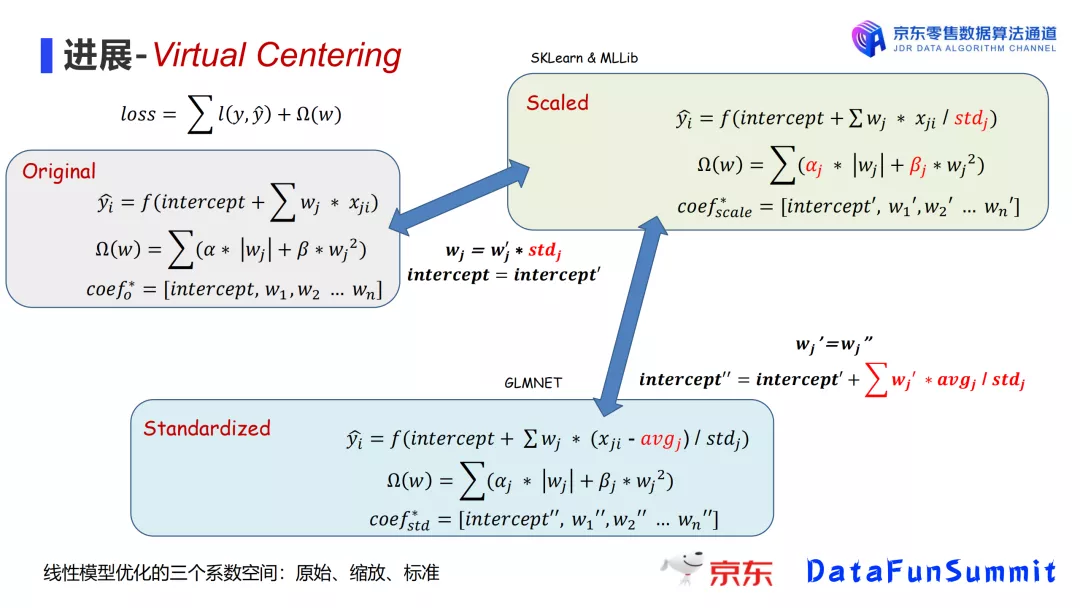
为什么不进行标准化?
主要是性能方面的考虑。一般线性模型的输入数据都是稀疏的,而稀疏数据进行标准化(例如减去差值)会导致内存使用飙升。

下图是线性模型现状:

挑战:如何在避免数据膨胀的情况下,实现GLMNET 的优化效果?
为了解决这个问题,我们提出新的思路:
- 对输入数据只进行缩放不进行标准化,从而避免破坏稀疏性;
- 计算过程中,在前向环节(计算预测值)引入一个预计算,在后向环节(计算梯度)进行梯度调整,从而达到与标准化相同的效果。这项黑魔法被我们称为virtual centering。
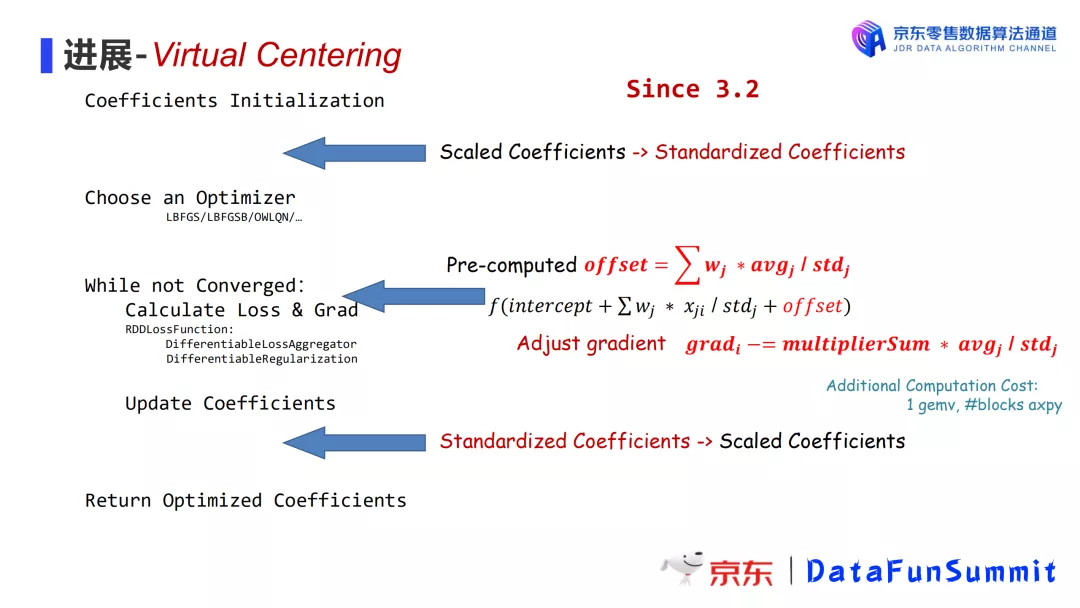
优化后我们进行对比测试,发现训练出的模型系数与GLMNET训练结果更接近,减少发散问题,且能减少20% ~ 50%的迭代次数。

目前,该项优化也已经集中于3.2版本中发布。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%AC%E4%B8%9C%E7%BA%BF%E6%80%A7%E6%A8%A1%E5%9E%8B%E7%9A%84%E9%87%8D%E6%9E%84%E4%B8%8E%E4%BC%98%E5%8C%96%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


