京东搜索在线学习探索实践
文章作者:刘露、张颖、段学浩、王东旭
内容来源:京东算法架构
出品平台:DataFunTalk
导读: 随着京东零售搜索业务的快速发展,对数据的时效性要求越来越高,要求搜索模型有捕捉更实时信号的能力,在线学习体现了业务对模型时效性的追求,希望能根据在线系统反馈的数据实时得对模型进行调整,使得模型能快速反应环境的变化,提高在线预估的准确率。
01 背景
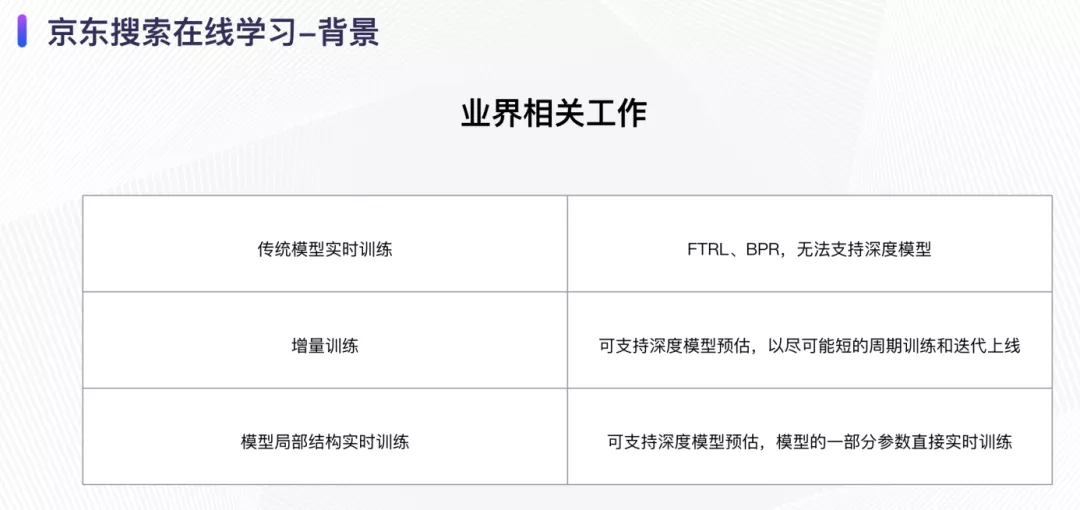
目前传统模型的实时训练(如FTRL等)无法支持深度模型,这些模型预估的准确率较低,比较适合一些简单的场景;第二种是类似增量训练的一种方式,可支持深度模型预估,这种方式以尽可能短的周期进行模型训练和迭代上线,是一种类实时的更新方式;第三种是以实时更新方式更新模型的局部结构,可支持深度模型的预估,模型的一部分参数直接参与实时训练。
02 系统概述
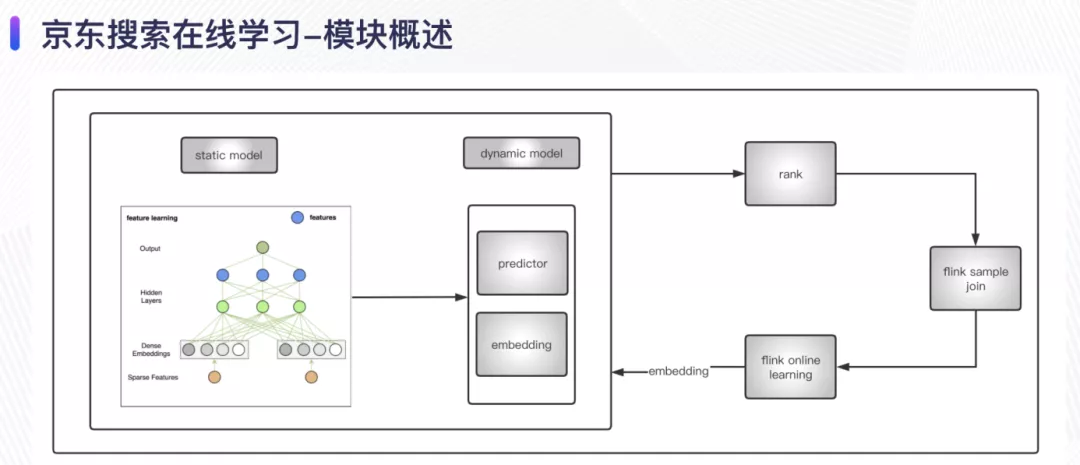
- 模型预估服务:在加载模型时,分为 static 部分和 dynamic 部分,static部分由离线数据训练得的到,主要学习 user 和 doc 的稠密特征表示,dynamic 部分主要包含 doc 粒度的权重向量,这部分由实时的 online learning 的任务进行流式更新;
- Rank:主要包括一些排序策略,在排序后会实时落特征日志,将当时的特征写入特征数据流,作为后续实时样本的数据源(feature);
- Flink 样本拼接任务:将上面的 feature 和用户行为标签数据作为数据源,通过flink 的 union + timer 数据模型关联成为流式样本数据;
- Online Learning 任务:负责消费上游生成的实时样本做训练,在训练得到新参数后更新 PS。
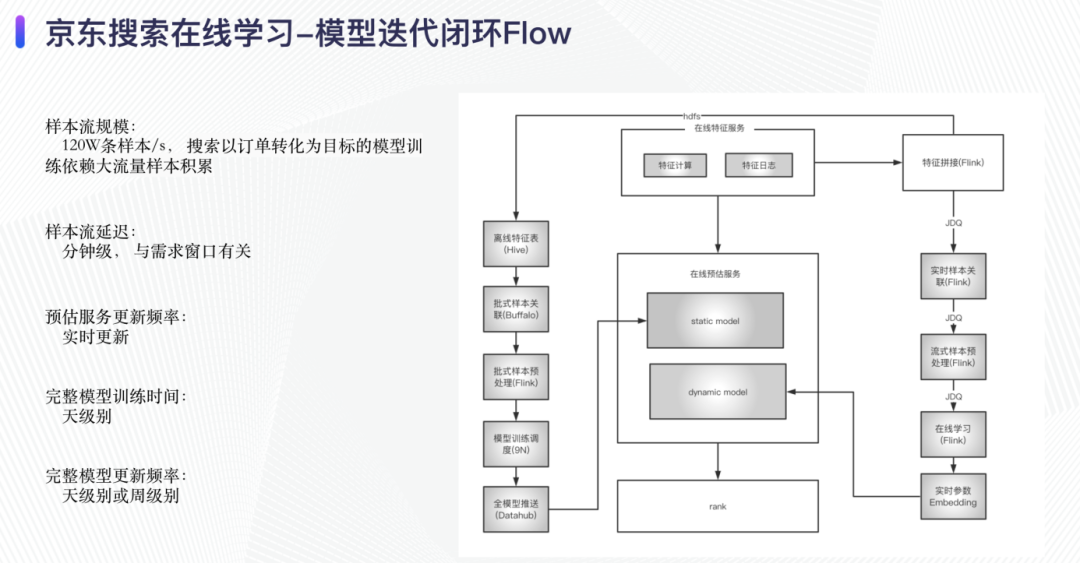
这里我们介绍整个链路的迭代过程:
- 经过离线样本拼接之后生成离线样本表,然后在模型训练平台训练之后将模型推送至模型仓库,同时将离线训练的参数推送至ps,之后predictor load 这个全量的离线模型;
- 经过实时样本拼接之后生成实时样本表,经过flink 的online learning 组件将实时的embeding 参数推入ps,将ps 作为dynamic model 的数据源;
- 预估服务predictor 加载全量的模型文件和实时训练的参数,提供在线服务;
- 离线模型提供 周/日 级别的周期模型校正。
03 实时特征和样本处理
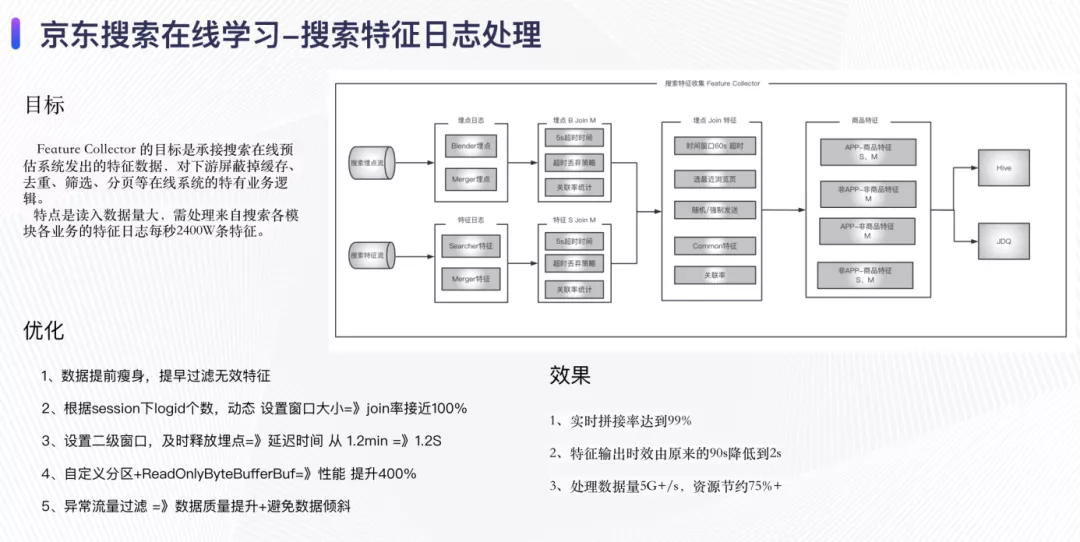
实时特征收集的目标是承接搜索在线预估系统所发出的特征数据,对下游屏蔽掉缓存、去重、筛选、分页等搜索系统特有的业务逻辑,提前滤除掉下游一定不会使用的数据,构建出标准Schema的原始特征流。该组件承接来自于搜索召回、排序、相关性等模块的实时特征,每秒需处理约2400W条特征数据。
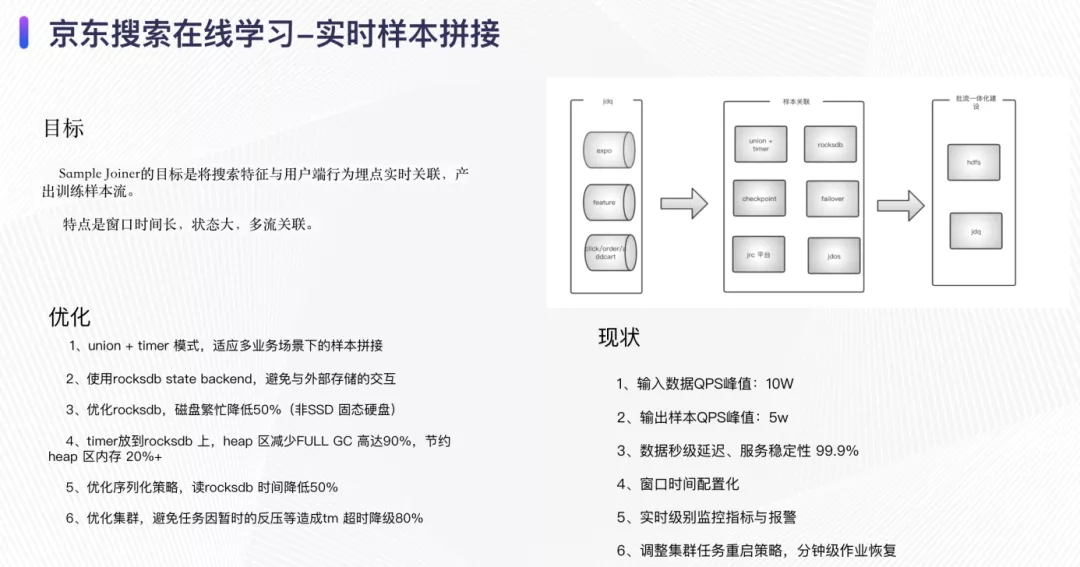
实时样本拼接的目标是将搜索特征与用户端的行为埋点实时关联。目前我们的数据数据过滤后的QPS峰值大概在10w,拼接完产生的样本QPS峰值在5w,该flink 任务的特点是多流拼接、时间窗口长、checkpoint size 大。我们采用union + timer 的模式实现多任务场景下的样本拼接,该实现策略的特点是可以随意扩展至N流并进行拼接;为了减少与外部存储的交互来降低网络的开销,我们使用flink 内部的rocksdb state backend,并且对rocksdb 的序列化手段和存储进行了相当的优化。
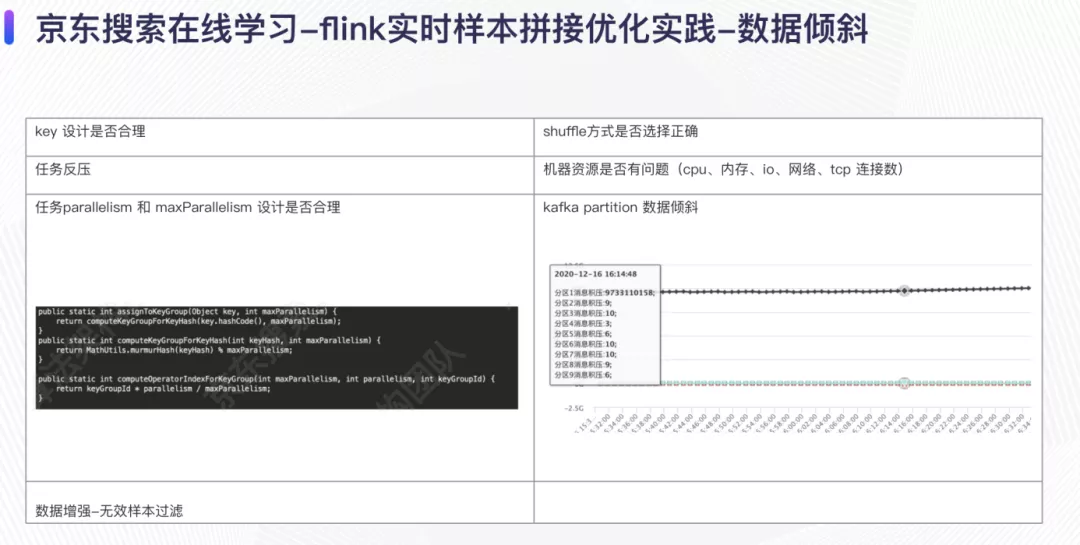
这里首先列举了一些常见的数据倾斜,比如说key 的设计不合理、flink 的shuffle 方式选择有问题、任务反压、机器资源的问题等,这里我们着重介绍一下这个任务的一些数据倾斜问题。
无效样本过滤策略,在最开始的时候我们发现某些subtask每次都会在固定的时间点发生checkpoint失败的现象,经过排查我们发现在实际的样本拼接数据里面会有很多的作弊数据,这导致那些checkpoint失败的subtask处理数据的QPS是其它subtask 的好几倍,过滤了这些作弊数据之后,任务恢复正常;我们还遇到过的一个数据倾斜现象是这样的:kafka source 所在的subtasks 莫名其妙的数据倾斜,机器的各个指标都没有到达瓶颈,经过排查之后是kafka producer 产生数据的时候produce 的key 指定了一个空的字符串"",这种经过hash 之后只会产生到kafka 的固定分区,flink 在接受数据的时候kafka source 所在的subtask是数据倾斜的,如果后面跟着的是一个map 操作(forward),那么后面的map 也就会数据倾斜。
样本拼接上线之后,任务运行稳定,但是某些subtask处理的数据量是一些数据量少的subtask 的1.5 倍,这种其实不算是严格意义上的数据倾斜,但是会造成资源的一定程度的浪费。利用 flink 中keygroup 的概念,和maxParallelism 大小相同,经过调整maxParallelism 的大小,保证了每个subtask 上面处理的数据量相同,解决数据倾斜问题。
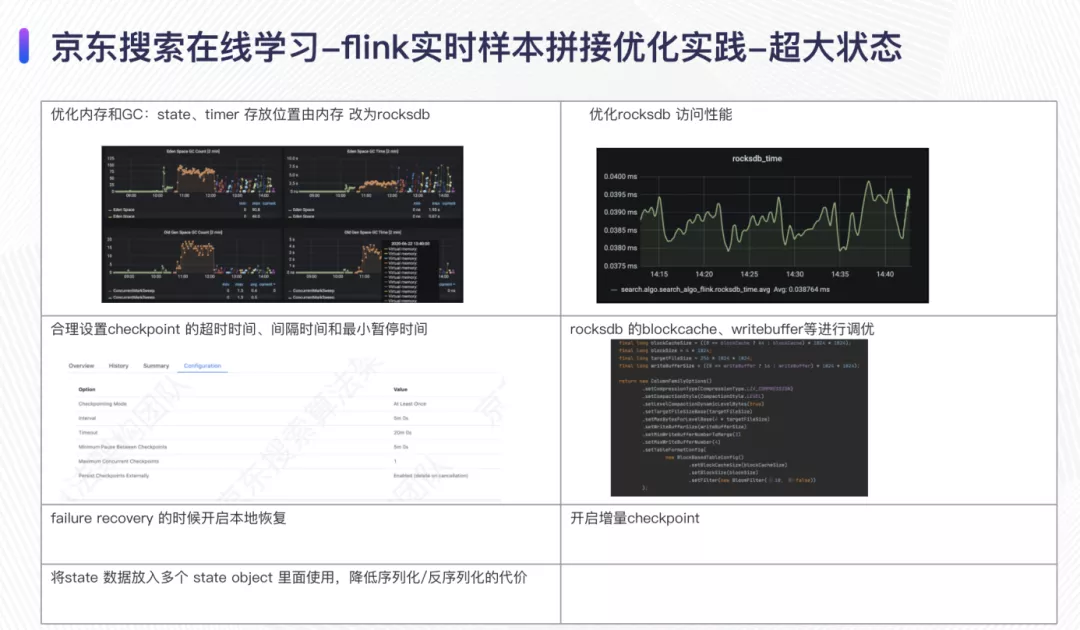
由于数据量大,且存储的特征比较多,导致任务的checkpoint size 达到了TB 级别。最开始的时候我们将数据放到了内存里面,但是因为数据量巨大,导致GC时间特别长,我们将数据放到了rocksdb 里面,并且我们对rocksdb 的blockcache、writebuffer等进行调优,添加了bloomfilter,使得rocksdb 的响应时间优化到了0.04ms 以内;通过合理设置checkpoint 的超时时间、间隔时间和最小暂停时间,使得任务在追数据的时候不至于导致qps突增太明显;最开始做拼接的时候我们将所有的pvid logid 和特征等值放入了一个valuestate,经过jstack 发现所有的线程都在做序列化和反序列化,其实我们做拼接只要pvid 和logid 就好了,因此我们将pvid 和logid 放入valuestate,将特征放入其它的state 里面,这样就少了很耗资源的序列化和反序列化操作,减少了很多系统开销;我们还开启了flink 特有的本地恢复和增量的checkpoint 操作来减少开销。
04 Flink 实时训练
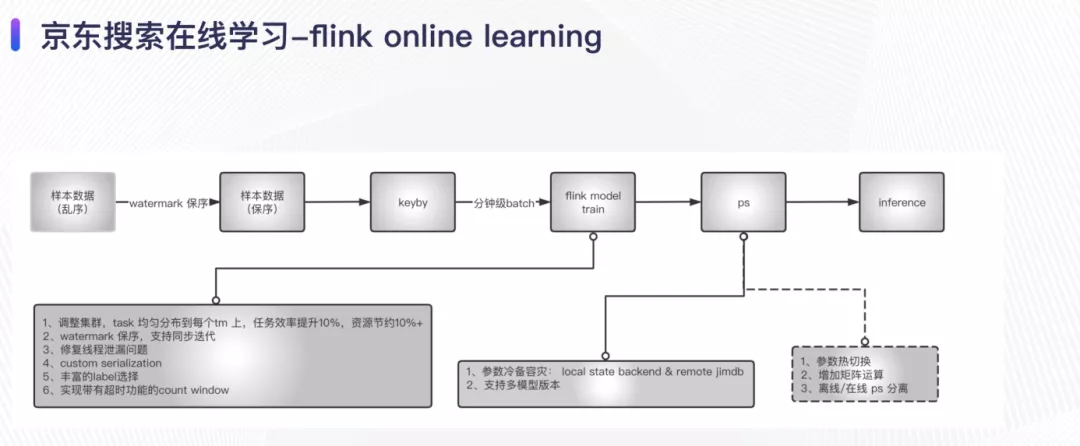
在线学习过程对实时样本具有一定要求,上游任务产生样本数据之后,因为是乱序的,我们为了保证样本流进入训练时最大程度还原真实事件顺序,利用flink 的watermark机制对样本进行了保序操作,之后我们实现了带有超时时间的countwindow 来做online 的train,通过ps 来更新参数,ps作为线上的inference 后端来直接查询。

- 采用 flink 的watermark 和eventtime 作为timecharacteristic 来保证顺序是有序的,尽可能的贴近事件当时的发生场景;样本一旦出现延时,且超过了系统的最大配置,我们会认为该样本不可用,直接丢弃。
- 为了允许在线学习任务自主配置每次训练迭代的数据规模,我们内部实现了带有超时时间的countwindow来精确控制每个batch 的大小;且我们支持任意维度的key组合来实现任意维度的batch 选择,这样方便实现session粒度、item粒度和user粒度的样本等。
- 当我们使用flink 的keyed state 的时候,采用异步更新的方式更新ps;当我们使用flink 的operator state 的时候,同步的方式更新ps。
- 目前对搜索算法接入了点击、加购、关注、下单、完成等多个标签流,支持丰富的标签选择。
- 支�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%AC%E4%B8%9C%E6%90%9C%E7%B4%A2%E5%9C%A8%E7%BA%BF%E5%AD%A6%E4%B9%A0%E6%8E%A2%E7%B4%A2%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


