京东推荐系统中的兴趣拓展如何驱动业务持续增长

作者: 彭长平 转载自 京东推荐系统中的兴趣拓展如何驱动业务持续增长
大家好,我是京东推荐广告的彭长平。今天主要跟大家介绍一些我们过去一两年在京东推荐系统里做的一些算法的创新。
演讲主要分三部分:
第一部分是简单描述一下电商的推荐与普通的、大家熟知的其他推荐系统的一些差异。电商推荐系统它自身有哪些特点;
第二部分我会从几个维度讲一下在 京东推荐系统 上做的一些创新,尤其是在用户兴趣拓展这个维度上。因为电商场景来说,所有的电商推荐系统都是分成捕捉用户兴趣和满足用户兴趣,然后也包括兴趣的拓展。在电商来说,用户兴趣的拓展相对他类型的推荐系统可能会更重要一些,实际上,在京东推荐系统里面,用户兴趣拓展这部分的曝光占比超过了一半以上。
第三部分我会简单介绍一下,我们现在正在做的一些相对前沿的技术方向。
推荐系统驱动业务增长
推荐系统应该大家都比较熟悉了,从PC 时代开始,国内外的所有的互联网公司,尤其是平台型的互联网公司,随着Iterm 候选的增多,已经远远超过了人脑能够处理的范围,所以它必然要通过算法去刻画人的兴趣,以及Item 的属性,去满足人和Item 的匹配。
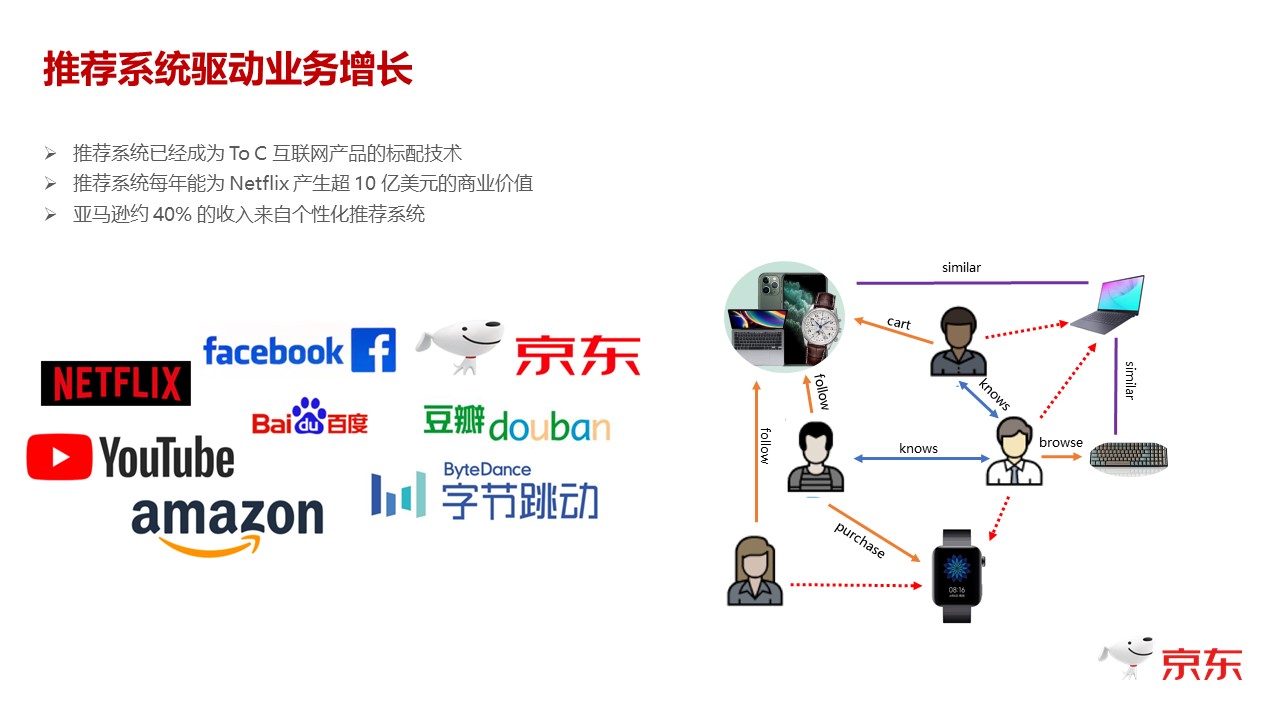
国内外大家能够看到的一些报道,像Netflex、 Amazon、Facebook、国内的 BAT,尤其是移动时代开始之后,手机屏幕这种手指和屏幕自然的交互方式,自然而然使得推荐进系统几乎成为每一家移动互联网公司的标配。推荐系统是公司花费非常多的人力和财力去打造的一个系统,同时这个系统也为各个企业带来了非常大的商业的价值。
在传统的推荐系统里,其实最主要是记录人的行为,因为最传统的推荐系统的算法就是协同过滤,后台的思想就是——物以类聚,人以群分。那么,类似的行为,或者商品属性类似的东西,就可以去做拓展。所以它最基础的一个逻辑,就是能够去记录用户的行为,基于这个行为去识别他的兴趣,去推荐跟他兴趣相关的属性的商品,或者是其他的一些 Item。
兴趣拓展驱动业务持续增长
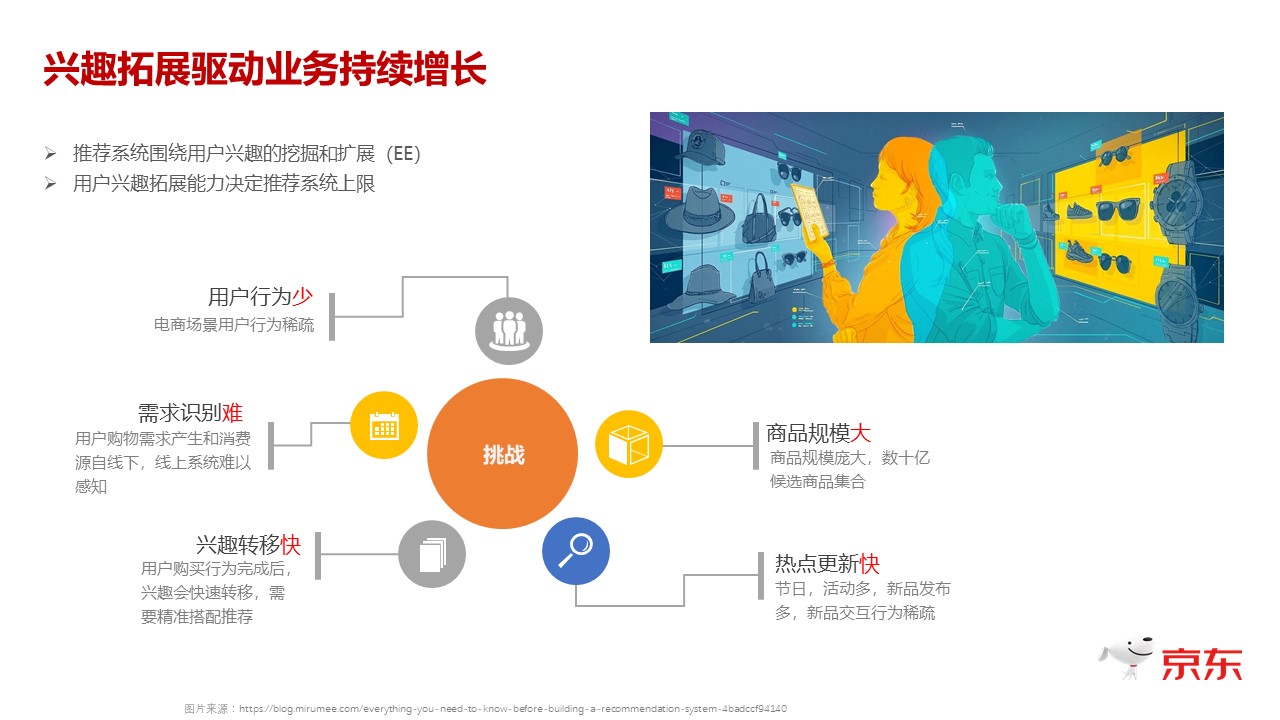
对于电商推荐系统来讲,我开始也简单提到了,在推荐系统里头分成两类,第一类是你识别他的兴趣,然后去推荐跟他的兴趣相匹配的一些商品。第二类,就是你要找到一些他没有明确表达出来的兴趣,我们用算法去猜测他有这方面的兴趣,然后去帮他做拓展。兴趣的拓展,其实对于各种推荐系统都很重要,但对于电商来说尤其重要。因为对于电商来说,你需要引导他去买,在你的平台上下单,如果你只是满足了他买的这个商品,其实也就意味着你的系统的上线是有限的,不管是对于用户也好,或者对于你平台上的商家也好,那么它其实成长的空间是有限的。所以拓展用户兴趣以及基于拓展出来的兴趣帮他做推荐,对于电商系统来说尤其重要。但这个事情对于电商系统来说,又是个特别难的事情。我们从用户和商品两个纬度来讲一下。
从用户纬度考虑,第一,如果说你去跟资讯类的、信息流这种推荐系统相比,那么它的用户行为是相对少的,因为用户不可能每天花 60 分钟、70 分钟,甚至更长的时间在你的系统上。第二个困难还是从用户角度来说,对于资讯类平台的推荐系统来说,用户消费你的内容就是在线上,你能够完整地记录到这个用户观看或消费平台内容的过程。但是,对于电商系统来说,它只是交易的过程产生在线上,用户为什么要买这个商品?以及买完商品之后的所有的消费过程,都是在线下的,难以数字化的。第三个困难跟前面两个点是也相关的,就是大多用户买完商品之后,在短期内不会再来买这个商品,不会再来买同类的商品,也就是说他的需求和兴趣会发生转移,这也就是为什么说,在电商的推荐系统里,仅仅捕捉用户的兴趣,基于捕捉到的兴趣去做推荐是不够的,这是从用户纬度来讲,我们面临的挑战。
从商品的维度来讲,第一、商品的规模是特别大的,我们正常看到的大部分平台的推荐系统所推荐的 Item 集合可能是几十万,几百万这个量级的,但是对于 电商系统 来说,它后台真正的侯选级都是数十亿SKU 的侯选,也是因为现在这个时代,已经进入了一个供过于求的状态,所以它更依赖于这些中长尾的商品,更依赖于推荐系统,去找到合适的用户。第二个特点,从电商平台角度来说,大量的热点是随着一些节日或者平台自己做的一些临时性的活动带来的用户,那么从逻辑上来说,这些商品其实它们的前续的用户行为一段时间内也是缺乏的,所有的这些点都表明:第一、兴趣拓展对于电商推荐系统来说特别重要。第二、它依赖于传统的协同过滤,依赖于用户行为的这种方式是不够的,所以后面我主要是介绍一些,我们在这方面做的一些尝试性的创新。我主要会介绍一些理念性的东西,讲得会相对粗略一些,每个方面介绍几个方法,不会讲特别复杂的推理过程,就是希望我们解决这个问题的一些思路对大家有些启发。
大家能看到下图这个PPT 中的三个环节,左边这个图是描述传统的、我们记录下来的用户的行为,包括他的浏览、购买、加购等所有电商平台能够在线记录下来的行为,正常的推荐系统都是分为几个环节:
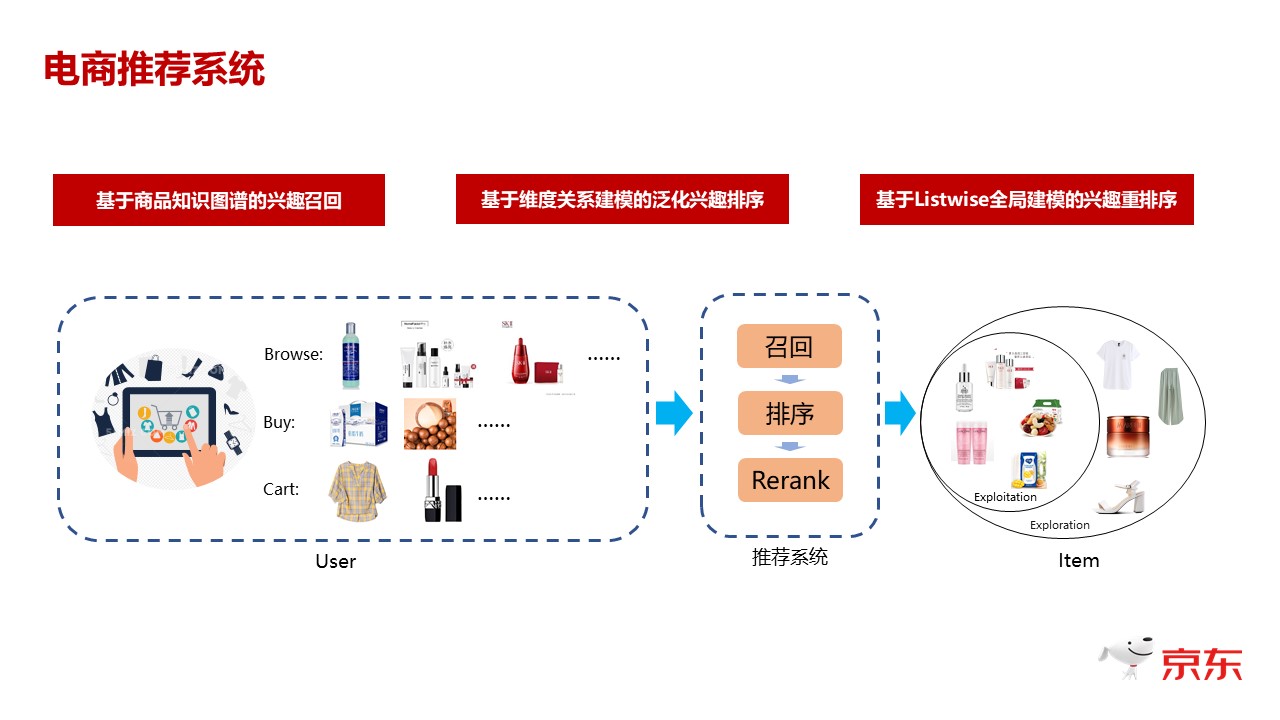
第一个环节是要从刚刚所说的数十亿的SKU 集合里,召回出来大概数千级别的侯选SKU。第二个环节是要对召回出来的数千级别的SKU 去做CTR,去做点击率或者转化率的这个预估,就是对每一个后选的商品,跟用户打一个预估的CTR 的分,或者预估的转化率的分。第三个环节是拿到打完分的这一千个侯选之后,怎么推出来最后返回给用户看到的那几条,或者几十条的侯选的过程。那么最后,呈现给用户的商品包括两部部分:第一部分,其实已经知道它对这些商品是感兴趣的。第二部分是去帮他探测,或者说把他感兴趣的、探索过的商品推荐出来。
几乎工业界的系统都是这种漏斗型的环节,我刚才讲的那三个环节都是漏斗型的,所以我们在每一个环节都需要去解决探索出来的商品怎么出来的这个问题。其实你已经识别出了用户的兴趣,然后基于兴趣打分,这个技术相对成熟的,但是如何去召回CTR 预估,以及最后的排序环节,如何保证我们探索出来的东西能够出去而且有一个合理的排序,每个环节都会有对应的一些解决方案。我这里主要介绍三个点的创新,第一个点就是基于商品知识图谱的一个召回。第二个环节是 CTR 预估 的环节,第三个点是在 Rerank,在最终的排序环节,怎么去做一个全局的建模。
基于商品知识图谱的兴趣召回

下面我们来详细说明下各个环节。第一个环节是讲基于商品知识图谱的兴趣召回,就是刚刚提到的,我们不管是从用户纬度来说,还是从商品纬度来说,存在大量的用户行为缺失,商品也缺少对应的行为。它依赖于传统行为的这种方法,不管是 CF 也好,还是基于用户行为去训练各种向量模型,或者其他的各种模型化的召回方法,在行为缺失的时候都失效了。
电商里有几个典型的场景,是商品行为特别缺失的,而这些场景在电商当中又特别重要:第一个就是新品的上架,比如小米 10 发布了,华为 10 或者 P40 发布了,或者 iPhone12 发布了,这些新品上来的时候,其实是完全没有用户行为的,这个时候你依赖于行为的模式去召回,都会面临商品本来很热,但是如果你依赖行为,它是推不出去的;第二个场景就是平台做活动,大家可能感知比较明显的是每年的 618、双十一,但是其实整个平台,每天都在做大大小小的活动,那么这种活动的商品,也是突然地从一个常规的销售要变成一个突然热门的销售,去依赖于传统的行为也是推不出来的;第三个场景一个时效的热点,这个热点可能不一定是平台做的活动,就是可能是社会上发生的某一个事件。这里举了一个例子是今年的疫情期间,其实平时有些商品它们之间是没有关联的,但是在疫情期间,比如说口罩、方便面、洗手液这些东西,正常的情况来看,它们其实不会建立关联的,但是因为疫情,它们之间建立了关联关系。第四个场景就是搭配购买,这个搭配购买大家都有买东西搭配的概念,大家都知道,买完手机之后,可能你要去买手机壳、手机贴膜,或者是你如果打游戏,手机可能还要配一些水冷的设备。那么正常来说,用户买完手机,推手机壳这是没有问题的,但是如果在电商场景时候,你推的这两个东西不是搭配的,比如说你推的是 P40 手机,你推出来是某个 iPhone 的保护壳,这对用户的体验伤害是很大的。基于这种场景来说,它其实大量的是依赖于除了行为之外的一些知识,这些知识才能去辅助帮你在这种场景下去帮用户做兴趣的拓展,而且要保证你拓展出来的东西是精准的,是满足用户需求的。
所以,基于我刚刚提到的,在用户行为失效的这个情况下,那么知识图谱这种东西就显得尤为重要。我们构建了一个商品之间的知识图谱。
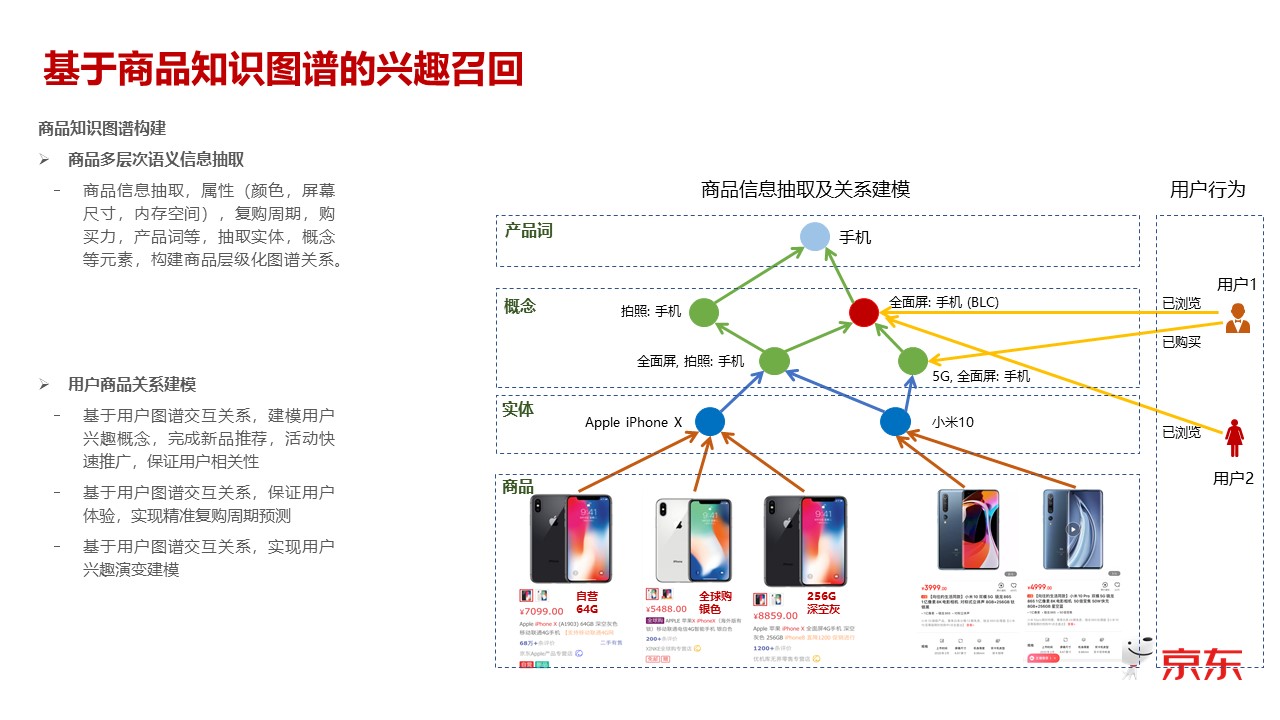
在右侧的图中,最底下这层是基础的商品,就是我刚刚提到的京东场景下数十亿的 SKU 的这些基础的商品。那么这层商品,其实它的各个商品都是各异的,再上一层,是我们需要算法能够抽取出来的,就是最主要是通过商品的一些的标题、描述,以及一些商详页一些属性,甚至包括用户评论的一些属性,一些信息,去抽取出来上一层的实体。这个实体的概念其实主要是在用户感知的概念里头,它是唯一的一个商品的集合。所以它的基础过程,第一步是基于标题、上下文的文本描述抽取出的这个过程,第二步是基于一些用户行为所做的一些具促之类或者是说一些数据清洗之类的逻辑去做的一个实体。实体再上面一层,我们叫概念层,这个概念层体现出来的也是一些用户关注的商品的属性,比如说这里举个手机的例子来说,那可能它关注这个手机的主打的功能是不是拍照,是不是全面屏,是不是带 5G,也就是类似于这种用户特别关注的某一个属性,我们叫概念层。
再上面一层才是手机,所以其实你可以看到这是一个从细到粗、逐步抽象出来的知识网络的结构。所以它结合了一些商品抽取的信息,也结合了一些用户的行为,那么有了这个基础的商品层次的结构之后,我们很多的关系构建就不需要基于最底下这层,因为最底下这层的量级是特别大的,数十亿级别的,在这个级别下面的东西其实没有泛化能力,如果说你想去做基于行为,或者基于其他方式去构建,构建出来的 数据 都会是特别稀疏的,所以我们更多的关系是基于上面那三层,尤其是中间那两层构建的一些商品的信息。
这里举一下基于这个图谱,我们在推荐中大概应用的方式。
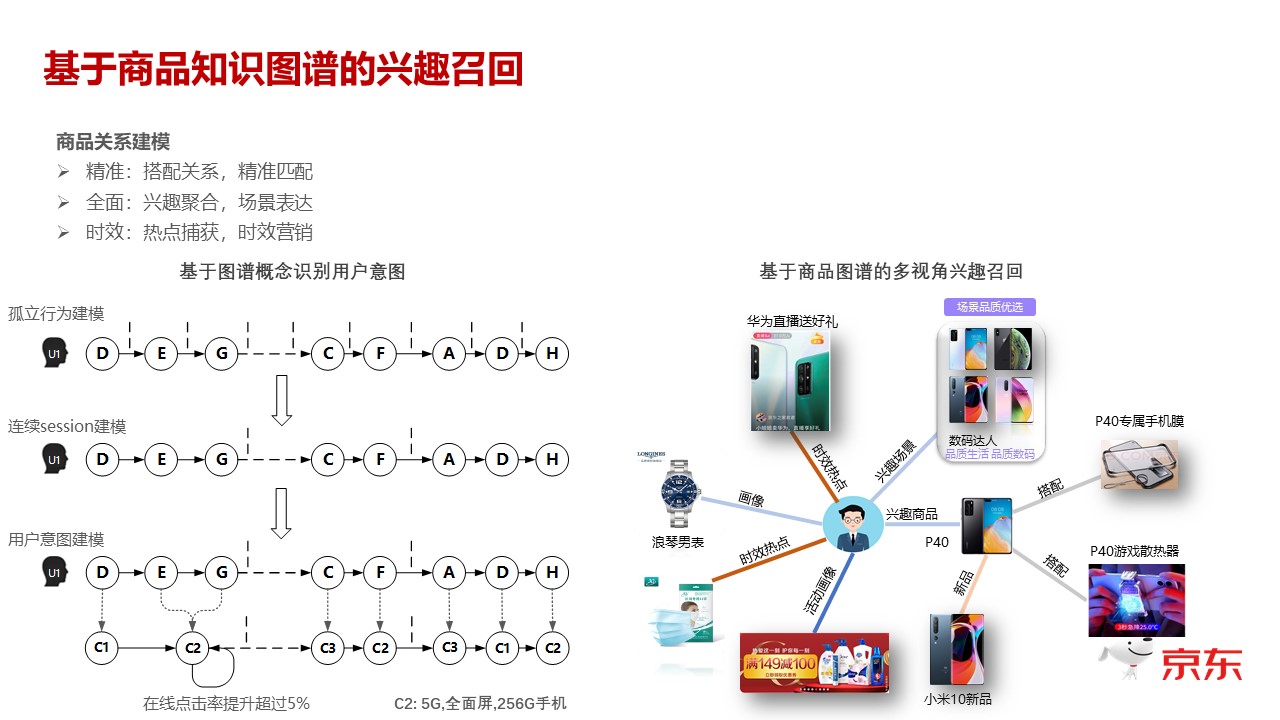
正如我前面所讲,如果基于最初始的协同过滤来说,用户的每一个行为,比如他过去某一个点击或者某个购买,你是基于某个孤立的行为去构建用户之间或者商品之间的关联关系的,其实这种构建的是你认为用户的每个行为都是孤立的,它其实并没有充分地利用户行为的关联关系。我们刚刚提到,用户的兴趣其实涉及到用户的演化过程,你基于孤立行为是刻画不出来用户的演化过程的。
所以,第一个自然反应是,我把这个孤立的行为,变成一个连续的行为,我把整个的用户行为建成一个链,基于这个链去做用户行为刻画。但是基于这个链刻画,碰到的第一个问题就是组合爆炸的问题。正如刚刚提到,这个链条如果你用到的是最底层商品的集合,它就面临着数据稀疏的问题。所以如果说数据特别稀疏,那其实输入的就跟噪音差不多。因此,大家看到我们第三步做的过程,上面那条链还是用户的基础行为,下面那条链是我们刚刚提到的那个图里面,从下往上数第三层,就是Concept 概念。你可以看到商品的个数特别多,但是用户的跳转行为,它的Concept 其实只有三个,它主要是围绕着C2 那个Concept 在跳转的,整个过程就把用户的行为降维了,基于下面这个链条去做建模,去做用户兴趣的刻画和跳转,那么召回来的东西就可以基于正常的建模的方式去做操作了。不管你是CF 的方法也好,还是其他的模型化的方法也好,都是能够工作的。
上图右侧的图,其实刚刚已经大概提了,其实就是说在一个用户跟一个商品发生关联之后,那么基于商品的知识图谱,你就可以建立出来很多关联。这是在召回方面我们所做的一个创新,其实最主要的工作就是知识图谱的构建。
基于维度关系建模的泛化兴趣排序
接下来,我们来讲一下CTR 预估。
CTR 预估这块我们面临问题都是一样的,都是存在大量的中长尾商品。因为电商这两年大家都在讲下沉,下沉之后,我们会有越来越多的新用户拉进来,不管是从商品的纬度,还是从用户的纬度,都会有大量的缺少行为的用户和商品。那么如果说你只是把它召回回来, CTR 预估 给它打的分还是低或者不准,那么召回来也是无用的。所以我们在模型方面要做同样的一些能力去保证我们对于用户行为缺少的这些商品和用户,也能够做合理的打分,这里介绍下我们所做的一个创新。
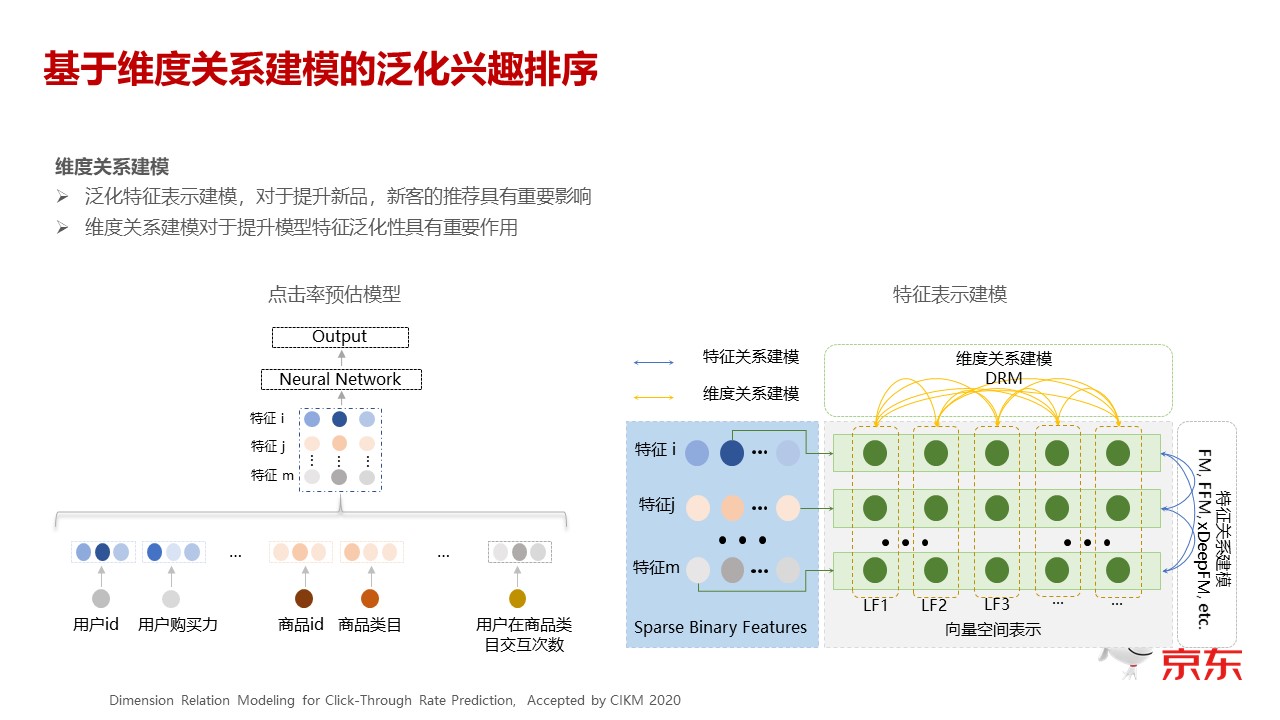
我们可以先来看一下左边的这个图,通常我们的模型结构都是这样的。最底下一层是用户行为类的特征,分为用户类的、商品类的、以及用户和商品之间的一些交叉的特征。那么最简单,最早期,大家的做法就是把这些特征转成一个 embedding 向量,embedding 向量再 concat 一起,就直接进入到神经网络层。
最近,大家觉得这个 Concat 做得比较糙,通常的做法不再是横着 Concat,而是把它组成一个矩阵。这个矩阵进去之后,在特征的纬度之间,大家可以看到右边这个图,就是通常的 FM,或者 FMM,或者一些常用的方法,这些都是我们在不同的特征之间去建立关联。我们的创新是在不同的纬度之间也建立同样的关联,去构建纬度之间的关系,就是想把这个 embedding 的特征刻划得更精细一些,以提升整个模型的表达和泛化能力。
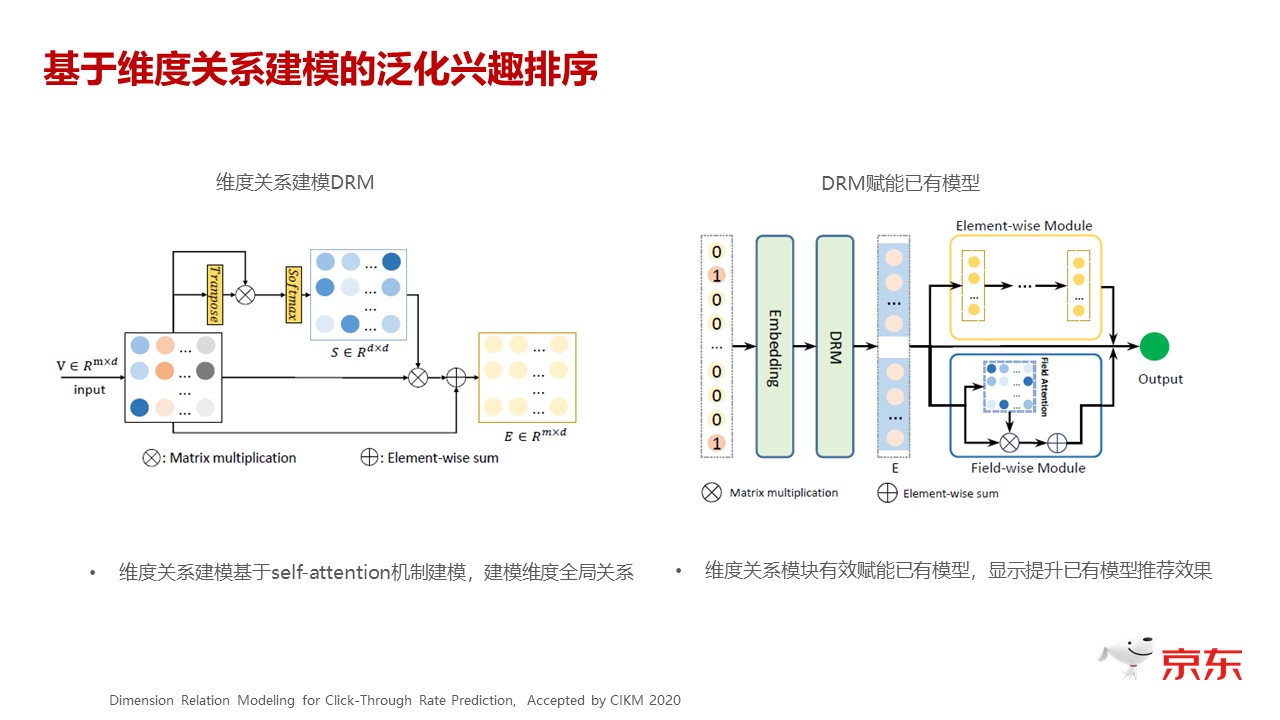
上图就是我们构建出来 DRM 模块。左边是实现的过程,可以看到,其实过程并不复杂。上面是矩阵,这个矩阵其实就是一个 self attention 的过程,下面只是一个这个支链的边,能够保证模型的迭代、收敛会更快,所以这是一个特别简单的通用的组件。
大家可以看下右边的图,右边是我们把它嵌到模型里的过程,最左边还是 sparse 的特征,后面跟着 embedding 然后是 DRM 这个纬度的模型,后面接的通畅深度网络,所以它是一个特别通用的模型,在任意的模型里,这个操作都是可以内嵌进去的。
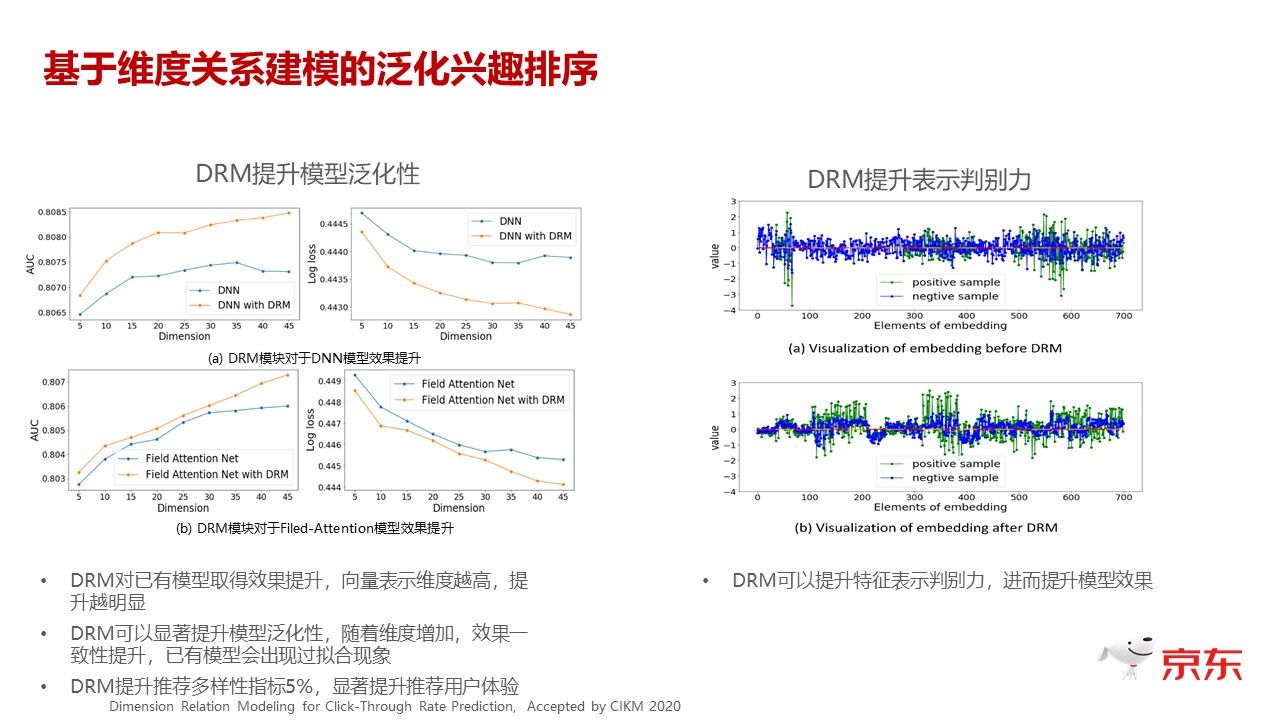
上图是嵌进之后,模型泛化能力的表现。我们从两个纬度来看,第一个纬度是模型的 AUC 和它的 loss 的情况,图中横坐标是 embedding 纬度,纵坐标是 AUC 和 Loss。可以看到很明显的就是,通常在没有加 DRM 这层的情况下,随着 embedding 纬度的提升,从模型表现来看,可以看到它是进入了一种过拟合的状态,它到一定阶段之后,纬度增加,并不能带来模型效果的提升,纬度高到一定的阶段,甚至还反而是下降的。但是加入这个 DRM 层之后,可以看到无论在哪一个纬度,带 DRM 层都是要比不带 DRM 层效果好很多,而且随着纬度越来越高,这个之间的 Gap 会和争议都会越来越大。
所以我们可以看到,DRM 层引进之后,明显的改变就是对你输入的语言 sparse 特征转换过 embedding 刻画得更精细了,模型的泛化能力有了明显的提升,尤其是在 embedding 纬度高的时候,它能够明显地解决原有模型的过拟合的现象。
图的右边是我们对进模型之前和进模型之后的特征变化的一个可视化。图中,绿色的是正例,蓝色的是负例,上面是进 DRM 之前,下面是进 DRM 之后。大家可以明显看到,过完我们的 DRM 模块之后,正例和负例明显有了更大的区分性。这个在我们系统中上线了之后效果也非常明显,我们多样性的指标 AB Test 相对提升了五个点。
基于 Listwise 全局建模的兴趣重排序
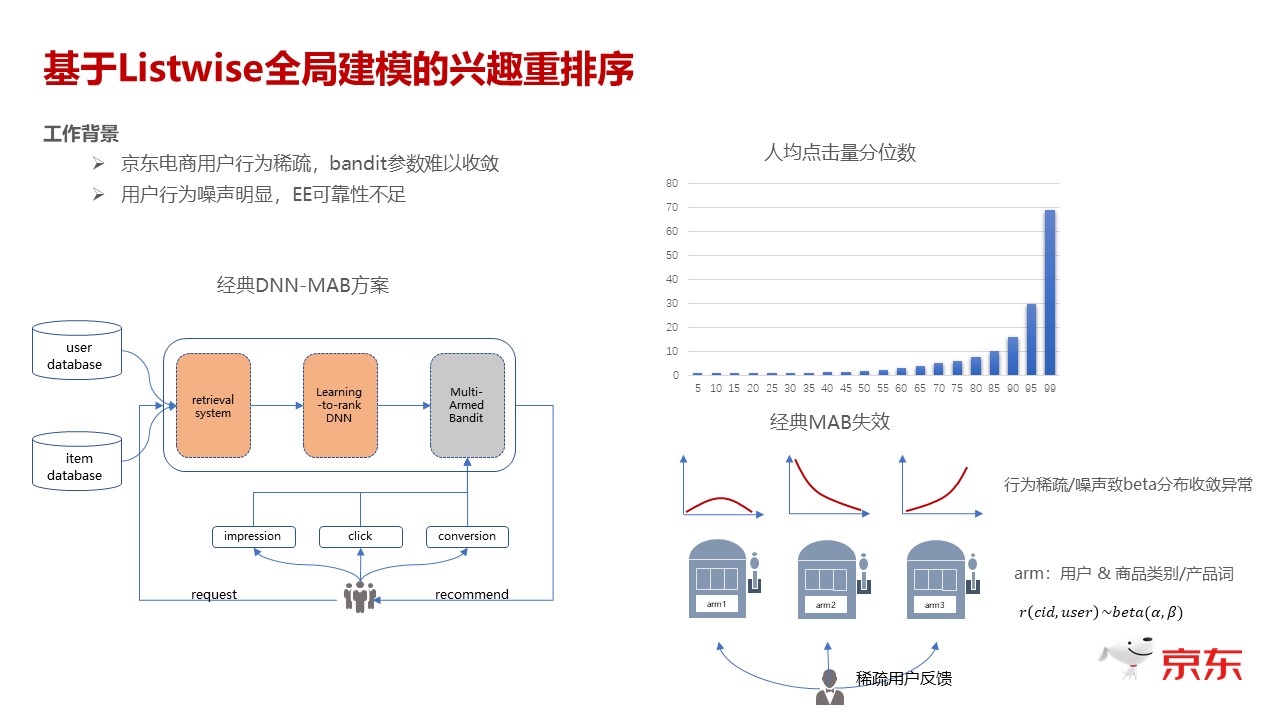
讲完 CTR,最后,我们再来看一下,当我们预估出来 CTR 值和 CVR 值以后,对每条预估出来的结果进行最终的排序。正常情况下,如果不考虑多样性,不考虑 Explore 这些特征,其实只要按 CTR 预估值从高到低排就行了。如果按照这种方式排序,那么你 Explore 出来的东西,大概率是出不来的。传统的方式是,我会在 CTR 预估后面再加一个 Explore 层。我这里画了一个用户人均点击的分类图,可以看到,绝大部分用户的点击都是处于长尾的,用户行为很少,如果画商品,分布趋势会更明显。因为我们数十亿的商品可能绝大部分都是有用户行为特别稀疏的。最早我们尝试这个事情的时候,用多臂老虎机,我们基于每个用户看过或者点击过的商品的品类和产品词来做 arm。那么在用户行为缺失的情况下出现的问题,要么就是多臂老虎机基于 Data 函数,学到的 Beta 分布,要么就是数据量太少,它是不收敛的,要么就是几个正例,或者几个负例,实际上是带着噪音性质的,所以它画出来 Beta 分布出的曲线,都是因为稀疏,或者是噪声导致整个 Beta 分布是没办法收敛的。
我们做的一个尝试,就是做聚类。其实就是简单地基于用户整个的 Session 行为,把商品和用户都转成对应的 embedding,基于 embedding 之后,做简单的 kmeans 聚类,一个用户簇和一个商品簇,这两个的组合构成了我们的一个 arm。因为聚类后的簇是可以控制的,你可以通过超参去寻优的。从 Beta 收敛情况能够很明显地看到,聚完簇之后,每个簇内的行为,都是相对充分的,那么不管是哪种情况,它都能比较快地进入收敛状态。这是我们跟一些常见的方法做的一些对比,我们这个方法最大的优势在于,在做 Explore 时候,它其实没有牺牲点击,因为正常大家都会觉得,我去做 Explore 之后,那一定是探索一些用户没表达出来的东西,那么这个东西一定是不那么相关的,点击率会下降,或者是说一些排序类相关性的指标会下降。但是这个方法,在我们的数据里验证的结果,不管是从离线还是在线结果来看,它是能够同时做到点击基本上持平略涨的情况下,多样性有了显著的提升。在线的效果是,用户的下拉深度,也就是用户浏览的时长有了一个非常显著的提升。
前面讲了 Explore,就是我们把用户不感兴趣的商品,没有明确表达感兴趣的商品探索出来,但是探索出来的东西和用户已经表达出感兴趣的东西怎么做合理的组合?怎么呈现给用户最终的那个合理的队列?这是排序里要解决的另一个问题。

上图中,大家看一下左边的示意图。我们发现用户已经主动浏览了一些手机和图书,那么我通过一些其他的行为能够猜测出,他还会感兴趣的东西是耳机和茶叶,那么我怎么去做合理的搭配?这里边举了一些例子,如果说你做得不合理,有可能出现的是大量已知的兴趣,或者反过来,大量的结果是你 Explore 的,不管哪种情况,效率都是低的,甚至是说你两种情况都搭配出来,但是如果说他们呈现出来的顺序不合理,那么最后的效果也是不好的。
所以它的核心的问题是 CTR 预估或者 CVR 预估可能是几百,或者千这个级别的侯选集合,在这个集合里面,怎么出来一个最终的队列,让用户看到的这个队列是效果最优的?最简单的思想就是,我用贪婪的方式,我先挑那个最好的,然后后面就是类似于队列生成的过程,那么基于第一个,去生成第二个,基于第二个去生成第三个,依此类推。如果再综合一下性能和效果,那么可能每次不是生成出来一个,而是生成出来 N 个,也就是说是 context 序列生成,再加一个 BeamSearch 这个过程,这是通常的几种方式。
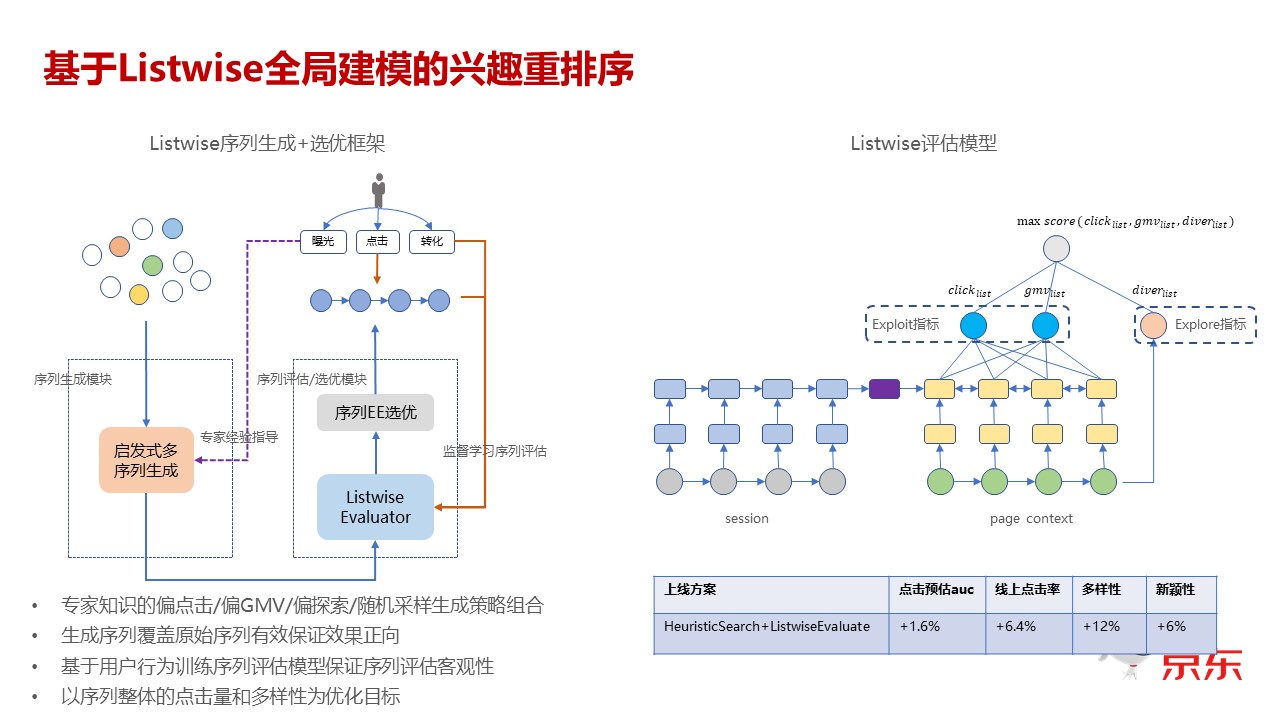
那么我们采用的一种方式是先基于启发式的搜索,再来做队列的打分。上图左边就是我们大概的过程。我生成侯选之后,先做一个启发式的队列生�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%AC%E4%B8%9C%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%9A%84%E5%85%B4%E8%B6%A3%E6%8B%93%E5%B1%95%E5%A6%82%E4%BD%95%E9%A9%B1%E5%8A%A8%E4%B8%9A%E5%8A%A1%E6%8C%81%E7%BB%AD%E5%A2%9E%E9%95%BF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


