亚马逊畅销书的分析推荐系统评论分类和主题建模
作者:Ellen Tang
编译:ronghuaiyang
导读
本文介绍了对亚马逊畅销书的NLP分析,并通过这些分析为客户产生了价值。

背景信息和目标
与所有其他零售公司一样,亚马逊努力解决客户评论中存在的欺诈和质量差的问题,并开发系统来识别公正和可靠的信息,以获得更好的客户体验。该分析试图将自然语言处理、情感分析和主题建模领域的现有工作应用到从 Amazon 检索的数据中。
随着数据分析和应用技术的发展,文本和自然语言分析越来越受到人们的关注,因为它为传统的定量方法带来了更有价值的见解。本文所要解决的问题包括三个方面:1、建立用户兴趣档案,更好地向用户推荐产品。2、设计一个系统,对新的评论进行“有用性”的“预评价”,以解决亚马逊客户评论的质量差的问题。3、构建能够从这些评论中发现关键见解(主题)的智能系统,使客户能够快速提取评论所涵盖的关键主题。
数据源规范和数据采集细节
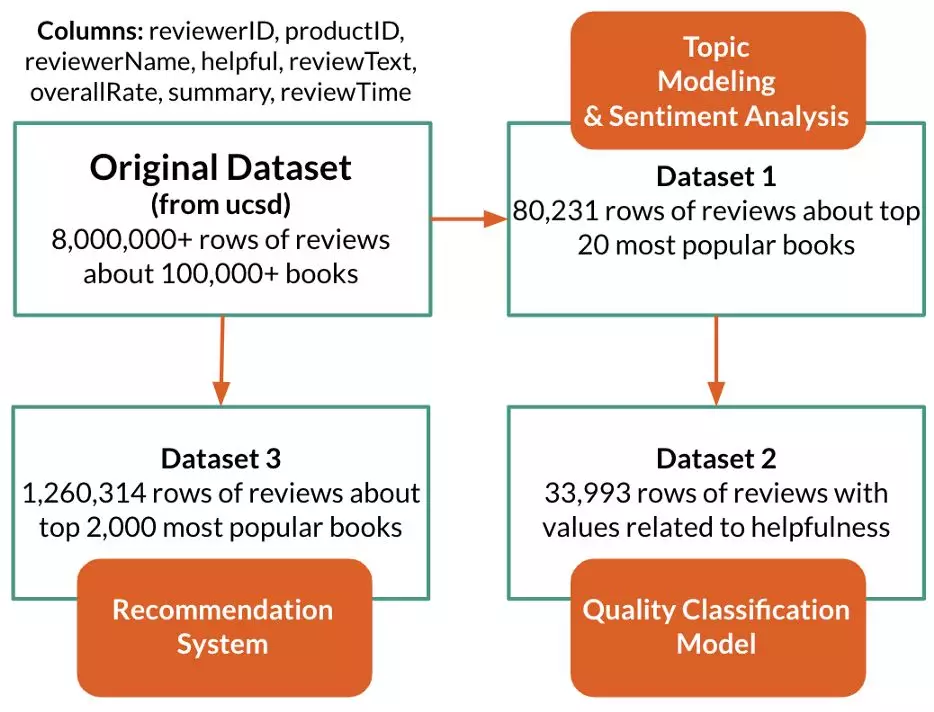
本项目使用的数据集是从 UCSD Julian McAuley 教授的研究门户网站导入的。目前的数据集包含从 2013 年到 2014 年的超过 80,000 篇书评,并被分割为只包含前 20 名畅销书的书评,从而具有比最常见的基线更高的预测能力和准确性。
数据采集过程中的主要任务之一是建立一个文本规范化器,将以下操作串联起来进行文本数据预处理:去除重音字符,对缩写进行复原,删除特殊字符,词干提取,词型还原,删除停止词以及去除重复词。
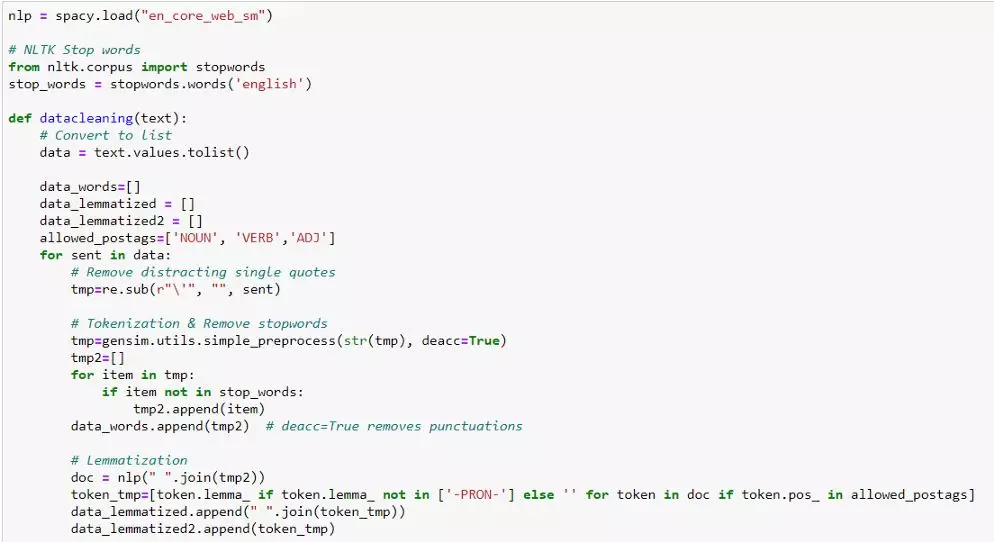
设计选择和实现方法的基本原理
主题建模和分类
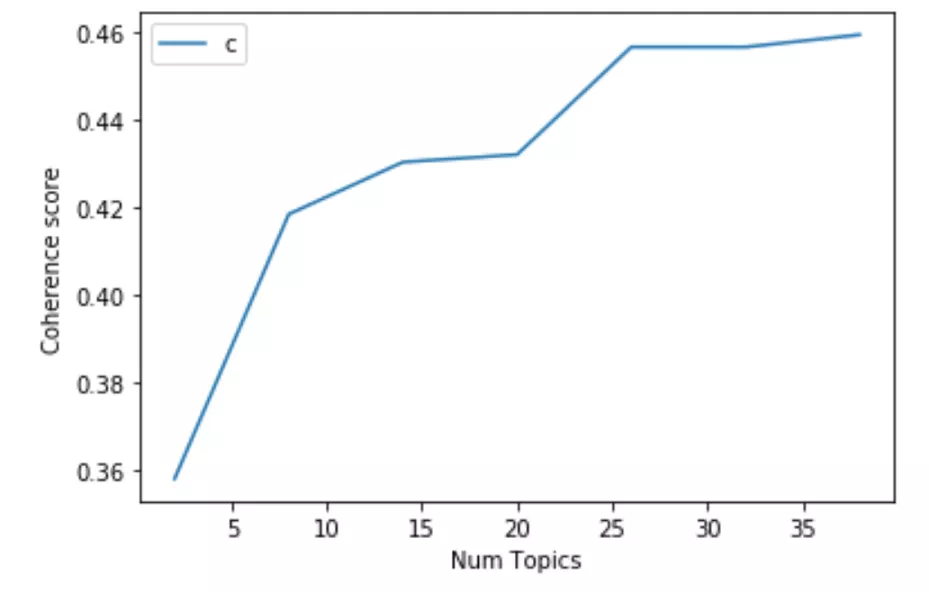
通过对两种不同的主题建模方法进行网格搜索和比较,结果表明 Mallet 的效果更好,25 个主题的一致性和稀疏性最好。基于这 25 个主题,我们可以简单地提取一个关于评论内容的简要想法。例如,第 14 个主题可能与《五十度灰》相关,第 25 个主题可能与《饥饿游戏》相关。

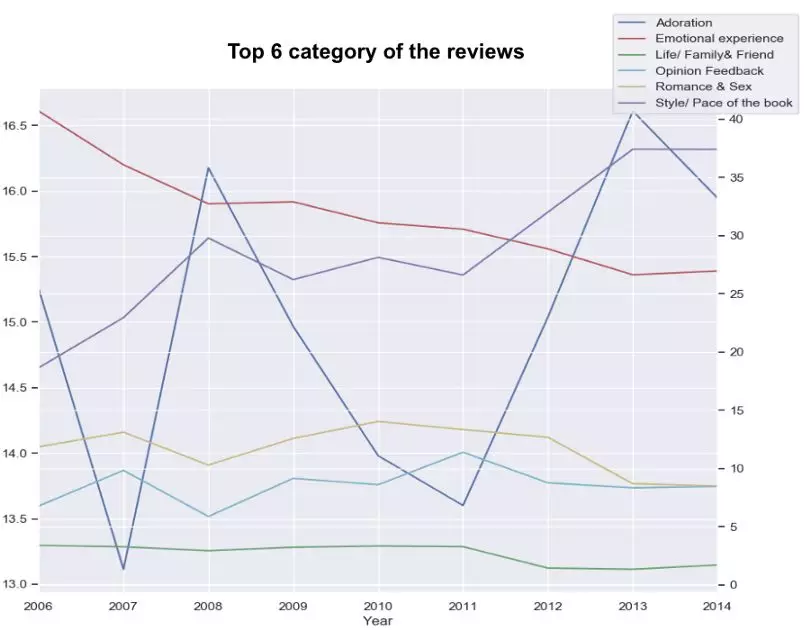

分类法中包含的类别和节点代表有价值的评论者对畅销书的反馈,图书销售商可以使用评论类别中的更改来监视和更改销售策略。下面三种评论可能针对特定的读者,因为这些评论的内容多年来都是一致的。
命名实体识别+购物篮分析。

情感分析
为了进行情感分析,我为情感建模添加了一个积极与消极的列,并将 1-3 的得分转化为消极的评价,将 4-5 的得分转化为积极的评价。这里的情感分析包括三种传统的机器学习算法,包括朴素贝叶斯分析、多项式贝叶斯和使用 Tfidf 方法的逻辑推理。我使用准确性评分和 F-1 评分来比较这三种模型的性能和预测能力。分析表明,与多项式贝叶斯相比,使用 TF 的 Logistic 算法具有更高的准确率,但是朴素贝叶斯分类器计算出了三种模型中准确率最好的数和 F-1 的得分。
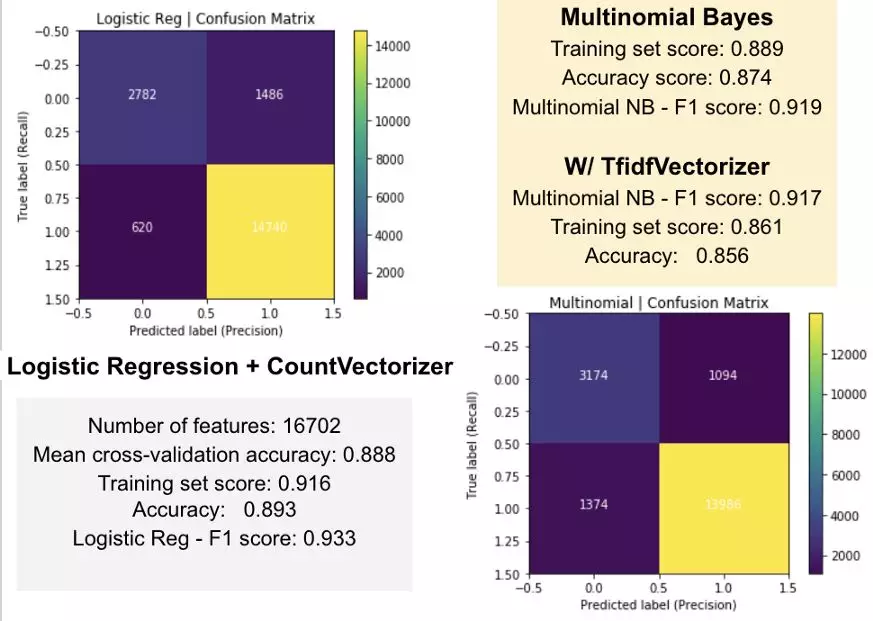

评论质量分类模型
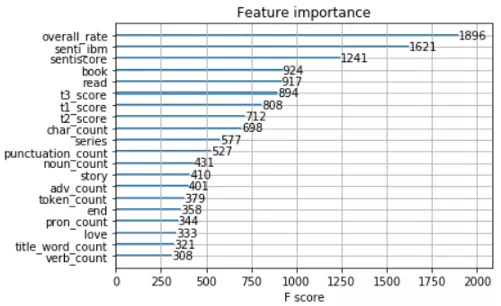
分类模型的目的是帮助亚马逊判断每条新评论的质量。在原始数据集中,有用的评论被标记为“helpful_rate”,范围从 0 到 1。helpful_rate 分数越高,评论越有帮助。因此,我使用 0.5 作为阈值,将数据分为“有用的”和“无用的”两个级别,作为因变量。在特征工程过程中,使用 unigram TfidfVectorizer 将所有的评论转化为向量是第一步。这个过程产生了 1500 个 n-gram 特征,包含了 bigram 和 trigram。计算每个文档中的单词、字符、标点符号、大写单词、标题单词和 pos 标签的数量。主题建模、分类、情绪分析和命名实体识别的结果也包括在内。在测试这些特征之后,n-gram 特征被删除,因为它们没有帮助。
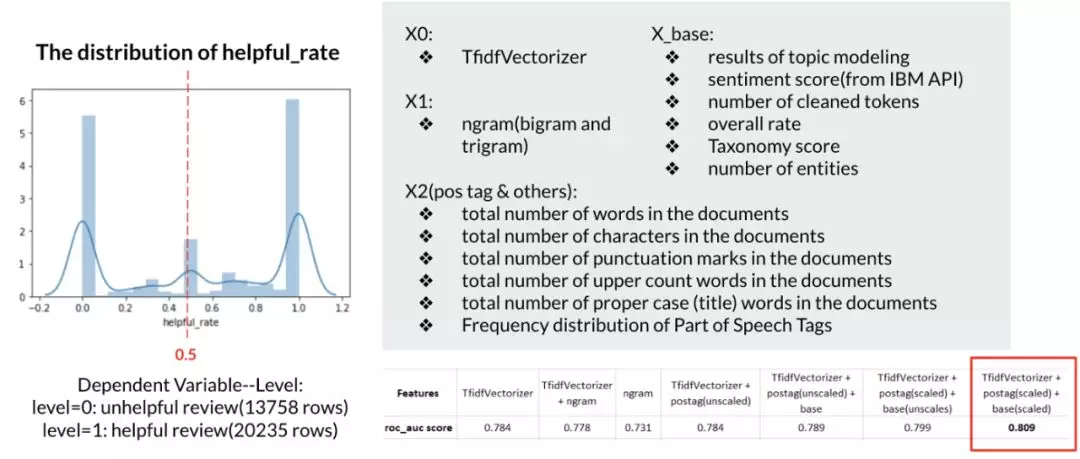
分类器方面,在 hugging face transformer 中,教程中实现了预先训练好的 RoBERTa 模型。然而,它的表现并不好。在这种情况下, RoBERTa 适合这个问题。如果 Amazon 想要使用这种预先训练好的模型,那么事先对 RoBERTa 的评论数据集进行调优会更有帮助。对所选择的特征进行了 GaussianNB、Logistic 回归、Random Forest、XGBoost 的测试,XGBoost 的性能最好。最后的模型是在对 max_depth、min_child_weight 和 gamma 等参数进行网格搜索后构建的。
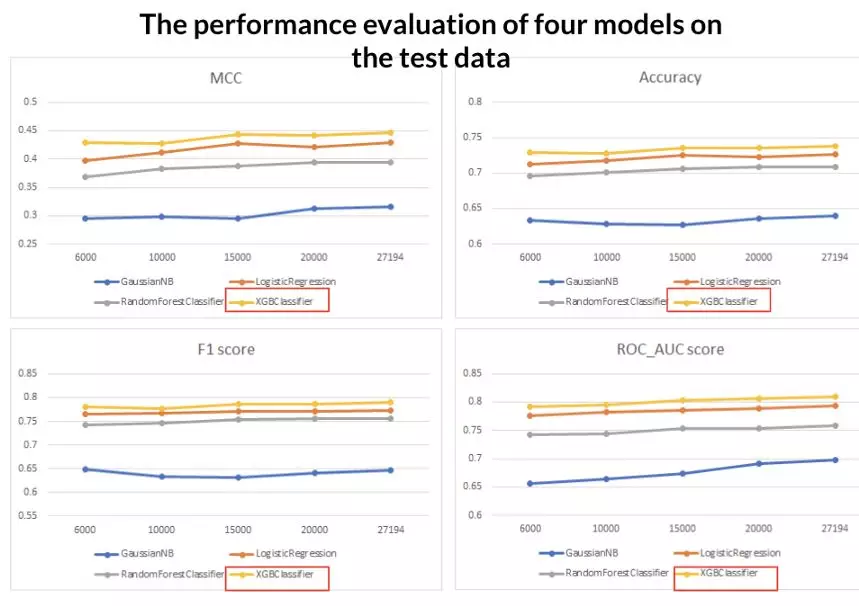
部分网格搜索后的最终模型结果:

推荐系统
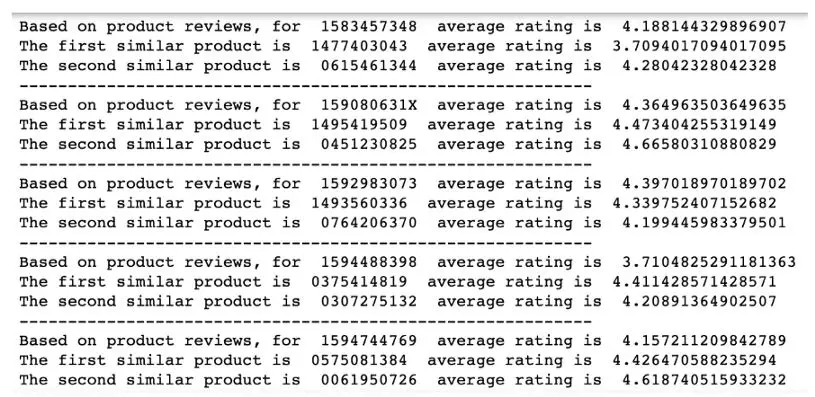
亚马逊 35%的利润来自于推荐系统和消费者对产品使用的评论和意见,这是一个强大的信息来源,可以用于推荐系统。Amazon 目前使用的是项目到项目的协同过滤,它将用户购买的每件商品与相似的商品进行匹配,然后将这些相似的商品组合成用户的推荐列表。本推荐系统是以产品描述和顾客购买行为为基础的。这项分析包括了一个推荐系统,该系统基于亚马逊(Amazon)对 2000 本最畅销图书的客户评论,利用 k 近邻查找最相似的前两本图书。该系统提供了一种排序机制,用于根据消费者评论的表示对产品相似性进行优先排序。
评估标准及量度
分类模型
分类模型采用 Matthews 相关系数、准确率评分、F1 分和 roc_auc 分来评价模型的准确性和精确度。分数越高,模型越好。基于这些分数,将 XGBoost 作为最终模型。在最后的模型中,我们使用 5000 棵树来训练模型,学习率设置为 0.01,最大深度设置为 4,最小子权重设置为 6。最终模型的 MCC、准确率、F1、roc_auc 分别为 0.488、0.7561、0.8013、0.8297。
推荐模型
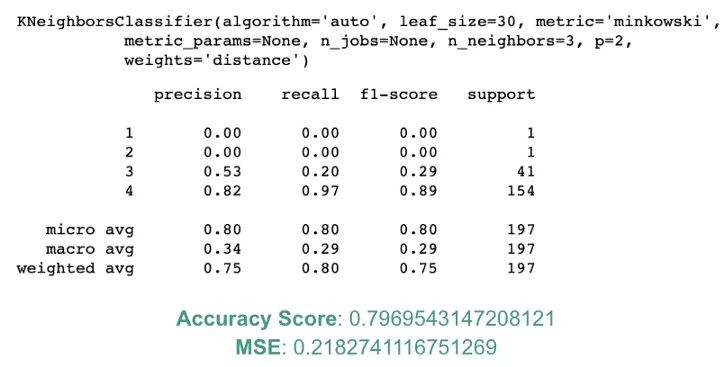
为了建立一个基于客户评论的推荐系统,我首先对 Amazon 图书的整体评分和评论数据集进行逻辑回归,并将每本书的所有客户评论内容转化为一个“词袋”。然后使用 k 近邻进行基于项目的协同过滤,找出最相似的两本书。这里应用的关键评估指标包括使用 MSE 来确定预测模型的准确性和计算预测精度数。与 k= 5 的 kNN 和算法=KD_Tree 相比,使用 ball_tree 模型的 k=3 具有更好的准确率(80%)和更小的 MSE(0.21)。
结果和结论
根据分析结果,本项目所开发的功能适用于解决客户评审中存在的欺诈和质量差的问题,识别公正可靠的信息以获得更好的客户体验。特别是,关键特征和 NLP 技术有助于解决以下业务问题:
评论的质量:为了提高客户评论的质量和在线购物体验,开发了一个系统,在新评论的“帮助程度”上对新评论进行评估。目前的模式建议亚马逊鼓励顾客用更多的名词、动词、副词和代名词来描述阅读体验,因为这些可以让评论更有帮助。
推荐�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%95%85%E9%94%80%E4%B9%A6%E7%9A%84%E5%88%86%E6%9E%90%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E8%AF%84%E8%AE%BA%E5%88%86%E7%B1%BB%E5%92%8C%E4%B8%BB%E9%A2%98%E5%BB%BA%E6%A8%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


