主流预估模型的演化及对比
学习和预测用户的反馈对于个性化推荐、信息检索和在线广告等领域都有着极其重要的作用。在这些领域,用户的反馈行为包括点击、收藏、购买等。本文以点击率(CTR)预估为例,介绍常用的CTR预估模型,试图找出它们之间的关联和演化规律。
数据特点
在电商领域,CTR预估模型的原始特征数据通常包括多个类别,比如[Weekday=Tuesday,
Gender=Male, City=London, CategoryId=16],这些原始特征通常以独热编码(one-hot encoding)的方式转化为高维稀疏二值向量,多个域(类别)对应的编码向量链接在一起构成最终的特征向量。
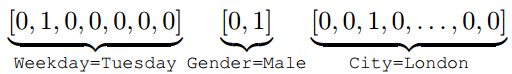
高维、 稀疏、 多Field 是输入给CTR预估模型的特征数据的典型特点。以下介绍的模型都假设特征数据满足上述规律,那些只适用于小规模数据量的模型就不介绍了。
Embedding表示
由于即将要介绍的大部分模型都或多或少使用了特征的embedding表示,这里做一个简单的介绍。
Embedding表示也叫做Distributed representation,起源于神经网络语言模型(NNLM)对语料库中的word的一种表示方法。相对于高维稀疏的one-hot编码表示,embedding-based的方法,学习一个低维稠密实数向量(low-dimensional dense embedding)。类似于hash方法,embedding方法把位数较多的稀疏数据压缩到位数较少的空间,不可避免会有冲突;然而,embedding学到的是类似主题的语义表示,对于item的“冲突”是希望发生的,这有点像软聚类,这样才能解决稀疏性的问题。
Google公司开源的word2vec工具让embedding表示方法广为人知。Embedding表示通常用神经网络模型来学习,当然也有其他学习方法,比如矩阵分解(MF)、因子分解机(FM)等。这里详细介绍一下基于神经网络的embedding学习方法。
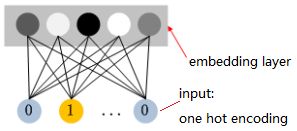
通常Embedding向量并不是通过一个专门的任务学习得到的,而是其他学习任务的附属产出。如下图所示,网络的输入层是实体ID(categorical特征)的one-hot编码向量。与输入层相连的一层就是Embedding层,两层之间通过全连接的方式相连。Embedding层的神经元个数即Embeeding向量的维数(
 )。输入层与Embedding层的链接对应的权重矩阵
)。输入层与Embedding层的链接对应的权重矩阵
 ,即对应
,即对应
 个输入实体的
个输入实体的
 维embedding向量。由于one-hot向量同一时刻只会有一个元素值为1,其他值都是0,因此对于当前样本,只有与值为1的输入节点相连的边上的权重会被更新,即不同ID的实体所在的样本训练过程中只会影响与该实体对应的embedding表示。假设某实体ID的one-hot向量中下标为
维embedding向量。由于one-hot向量同一时刻只会有一个元素值为1,其他值都是0,因此对于当前样本,只有与值为1的输入节点相连的边上的权重会被更新,即不同ID的实体所在的样本训练过程中只会影响与该实体对应的embedding表示。假设某实体ID的one-hot向量中下标为
 的值为1,则该实体的embedding向量为权重矩阵
的值为1,则该实体的embedding向量为权重矩阵
 的第
的第
 行。
行。
常用模型
1. LR
LR模型是广义线性模型,从其函数形式来看,LR模型可以看做是一个没有隐层的神经网络模型(感知机模型)。
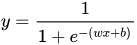
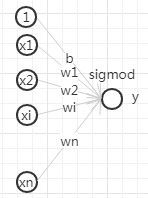
LR模型一直是CTR预估问题的benchmark模型,由于其简单、易于并行化实现、可解释性强等优点而被广泛使用。然而由于线性模型本身的局限,不能处理特征和目标之间的非线性关系,因此模型效果严重依赖于算法工程师的特征工程经验。
为了让线性模型能够学习到原始特征与拟合目标之间的非线性关系,通常需要对原始特征做一些非线性转换。常用的转换方法包括:连续特征离散化、特征之间的交叉等。
连续特征离散化的方法一般是把原始连续值的值域范围划分为多个区间,比如等频划分或等间距划分,更好的划分方法是利用监督学习的方式训练一个简单的单特征的决策树桩模型,即用信息增益指标来决定分裂点。特征分区间之后,每个区间上目标( y)的分布可能是不同的,从而每个区间对应的新特征在模型训练结束后都能拥有独立的权重系数。特征离散化相当于把线性函数变成了分段线性函数,从而引入了非线性结构。比如不同年龄段的用户的行为模式可能是不同的,但是并不意味着年龄越大就对拟合目标(比如,点击率)的贡献越大,因此直接把年龄作为特征值训练就不合适。而把年龄分段后,模型就能够学习到不同年龄段的用户的不同偏好模式。离散化的其他好处还包括对数据中的噪音有更好的鲁棒性(异常值也落在一个划分区间,异常值本身的大小不会过度影响模型预测结果);离散化还使得模型更加稳定,特征值本身的微小变化(只有还落在原来的划分区间)不会引起模型预测值的变化。
特征交叉是另一种常用的引入非线性性的特征工程方法。通常CTR预估涉及到用户、物品、上下文等几方面的特征,往往单个特征对目标判定的贡献是较弱的,而不同类型的特征组合在一起就能够对目标的判定产生较强的贡献。比如用户性别和商品类目交叉就能够刻画例如“女性用户偏爱美妆类目”,“男性用户喜欢男装类目”的知识。特征交叉是算法工程师把领域知识融入模型的一种方式。
LR模型的不足在于特征工程耗费了大量的精力,而且即使有经验的工程师也很难穷尽所有的特征交叉组合。
2. LR + GBDT
既然特征工程很难,那能否自动完成呢?模型级联提供了一种思路,典型的例子就是Facebook 2014年的论文中介绍的通过GBDT(Gradient Boost Decision Tree)模型解决LR模型的特征组合问题_。_思路很简单,特征工程分为两部分,一部分特征用于训练一个GBDT模型,把GBDT模型每颗树的叶子节点编号作为新的特征,加入到原始特征集中,再用LR模型训练最终的模型。
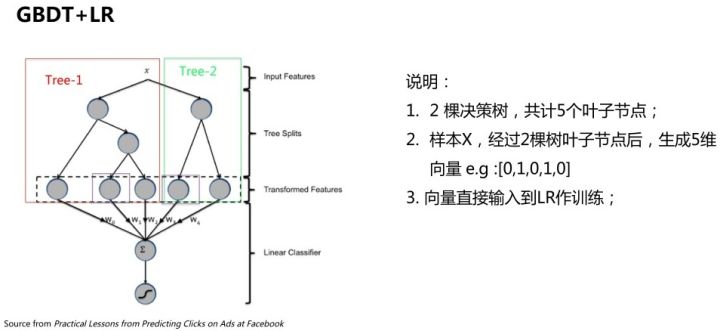
GBDT模型能够学习高阶非线性特征组合,对应树的一条路径(用叶子节点来表示)。通常把一些连续值特征、值空间不大的categorical特征都丢给GBDT模型;空间很大的ID特征(比如商品ID)留在LR模型中训练,既能做高阶特征组合又能利用线性模型易于处理大规模稀疏数据的优势。
3. FM、FFM
因子分解机(Factorization Machines, FM)通过特征对之间的隐变量内积来提取特征组合,其函数形式如下:

FM和基于树的模型(e.g. GBDT)都能够自动学习特征交叉组合。基于树的模型适合连续中低度稀疏数据,容易学到高阶组合。但是树模型却不适合学习高度稀疏数据的特征组合,一方面高度稀疏数据的特征维度一般很高,这时基于树的模型学习效率很低,甚至不可行;另一方面树模型也不能学习到训练数据中很少或没有出现的特征组合。相反,FM模型因为通过隐向量的内积来提取特征组合,对于训练数据中很少或没有出现的特征组合也能够学习到。例如,特征
 和特征
和特征
 在训练数据中从来没有成对出现过,但特征
在训练数据中从来没有成对出现过,但特征
 经常和特征
经常和特征
 成对出现,特征
成对出现,特征
 也经常和特征
也经常和特征
 成对出现,因而在FM模型中特征
成对出现,因而在FM模型中特征
 和特征
和特征
 也会有一定的相关性。毕竟所有包含特征
也会有一定的相关性。毕竟所有包含特征
 的训练样本都会导致模型更新特征
的训练样本都会导致模型更新特征
 的隐向量
的隐向量
 ,同理,所有包含特征
,同理,所有包含特征
 的样本也会导致模型更新隐向量
的样本也会导致模型更新隐向量
 ,这样
,这样
 就不太可能为0。
就不太可能为0。
在推荐系统中,常用矩阵分解(MF)的方法把User-Item评分矩阵分解为两个低秩矩阵的乘积,这两个低秩矩阵分别为User和Item的隐向量集合。通过User和Item隐向量的点积来预测用户对未见过的物品的兴趣。矩阵分解也是生成embedding表示的一种方法,示例图如下:
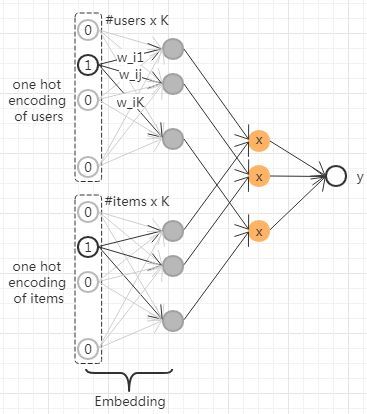
MF方法可以看作是FM模型的一种特例,即MF可以看作特征只有userId和itemId的FM模型。FM的优势是能够将更多的特征融入到这个框架中,并且可以同时使用一阶和二阶特征;而MF只能使用两个实体的二阶特征。
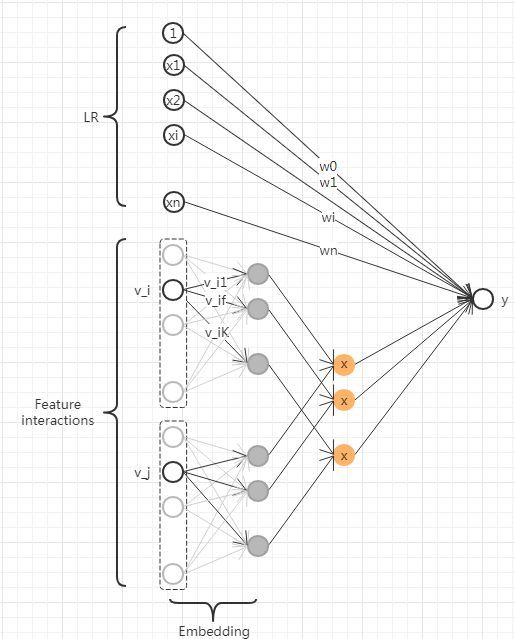
在二分类问题中,采用LogLoss损失函数时,FM模型可以看做是LR模型和MF方法的融合,如下图所示:
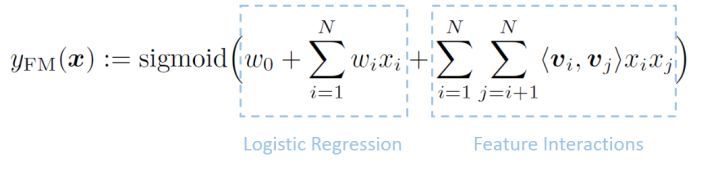
FFM(Field-aware Factorization Machine)模型是对FM模型的扩展,通过引入field的概念,FFM把相同性质的特征归于同一个field。例如,“Day=26/11/15”、 “Day=1/7/14”、 “Day=19/2/15”这三个特征都是代表日期的,可以放到同一个field中。同理,商品的末级品类编码也可以放到同一个field中。简单来说,同一个categorical特征经过One-Hot编码生成的数值特征都可以放到同一个field,包括用户性别、职业、品类偏好等。在FFM中,每一维特征


 。因此,隐向量不仅与特征相关,也与field相关。假设样本的
。因此,隐向量不仅与特征相关,也与field相关。假设样本的
 个特征属于
个特征属于
 个field,那么FFM的二次项有
个field,那么FFM的二次项有
 个隐向量。
个隐向量。

FM可以看作FFM的特例,在FM模型中,每一维特征的隐向量只有一个,即FM是把所有特征都归属到一个field时的FFM模型。
4. 混合逻辑回归(MLR)
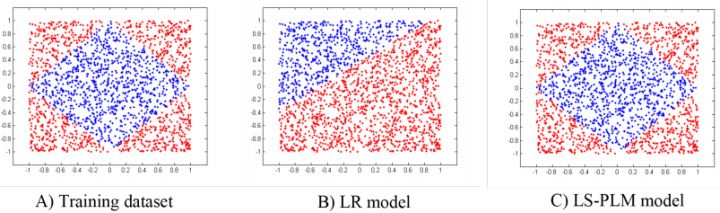
MLR算法是alibaba在2012年提出并使用的广告点击率预估模型,2017年发表出来。MLR模型是对线性LR模型的推广,它利用分片线性方式对数据进行拟合。基本思路是采用分而治之的策略:如果分类空间本身是非线性的,则按照合适的方式把空间分为多个区域,每个区域里面可以用线性的方式进行拟合,最后MLR的输出就变为了多个子区域预测值的加权平均。如下图(C)所示,就是使用4个分片的MLR模型学到的结果。

上式即为MLR的目标函数,其中
 为分片数(当
为分片数(当
 时,MLR退化为LR模型);
时,MLR退化为LR模型);
 是聚类参数,决定分片空间的划分,即某个样本属于某个特定分片的概率;
是聚类参数,决定分片空间的划分,即某个样本属于某个特定分片的概率;
 是分类参数,决定分片空间内的预测;
是分类参数,决定分片空间内的预测;
 和
和
 都是待学习的参数。最终模型的预测值为所有分片对应的子模型的预测值的期望。
都是待学习的参数。最终模型的预测值为所有分片对应的子模型的预测值的期望。
MLR模型在大规模稀疏数据上探索和实现了非线性拟合能力,在分片数足够多时,有较强的非线性能力;同时模型复杂度可控,有较好泛化能力;同时保留了LR模型的自动特征选择能力。
MLR模型的思路非常简单,难点和挑战在于MLR模型的目标函数是非凸非光滑的,使得传统的梯度下降算法并不适用。相关的细节内容查询论文:Gai et al, “Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction” 。
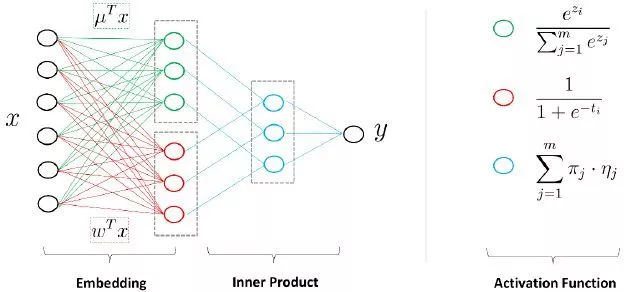
另一方面,MLR模型可以看作带有一个隐层的神经网络。如下图,
 是大规模的稀疏输入数据,MLR模型第一步是做了一个Embedding操作,分为两个部分,一种叫聚类Embedding(绿色),另一种是分类Embedding(红色)。两个投影都投到低维的空间,维度为
是大规模的稀疏输入数据,MLR模型第一步是做了一个Embedding操作,分为两个部分,一种叫聚类Embedding(绿色),另一种是分类Embedding(红色)。两个投影都投到低维的空间,维度为
 ,是MLR模型中的分片数。完成投影之后,通过很简单的内积(Inner Product)操作便可以进行预测,得到输出
,是MLR模型中的分片数。完成投影之后,通过很简单的内积(Inner Product)操作便可以进行预测,得到输出
 。
。
5. WDL(Wide & Deep Learning)
像LR这样的wide模型学习特征与目标之间的直接相关关系,偏重记忆(memorization),如在推荐系统中,wide模型产生的推荐是与用户历史行为的物品直接相关的物品。这样的模型缺乏刻画特征之间的关系的能力,比如模型无法感知到“土豆”和“马铃薯”是相同的实体,在训练样本中没有出现的特征组合自然就无法使用,因此可能模型学习到某种类型的用户喜欢“土豆”,但却会判定该类型的用户不喜欢“马铃薯”。
WDL是Google在2016年的paper中提出的模型,其巧妙地将传统的特征工程与深度模型进行了强强联合。模型结构如下:
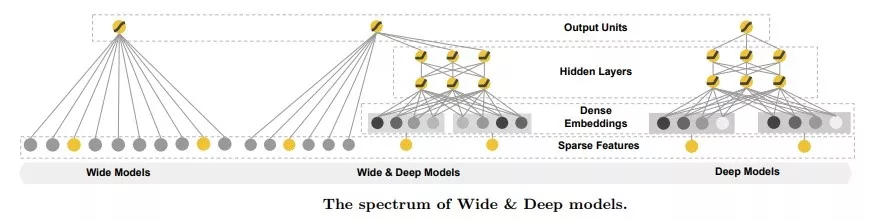
WDL分为wide和deep两部分联合训练,单看wide部分与LR模型并没有什么区别;deep部分则是先对不同的ID类型特征做embedding,在embedding层接一个全连接的MLP(多层感知机),用于学习特征之间的高阶交叉组合关系。由于Embedding机制的引入,WDL相对于单纯的wide模型有更强的泛化能力。
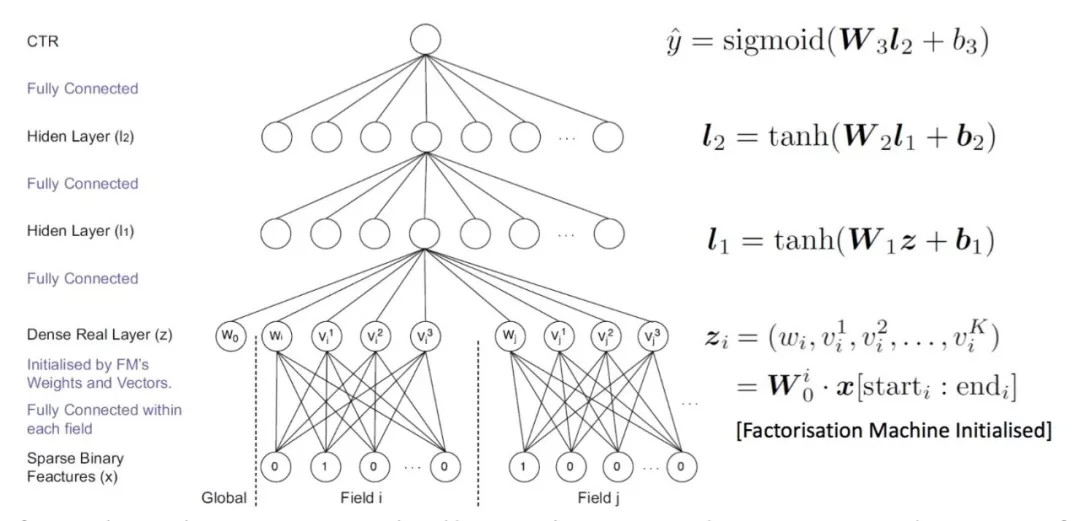
6. FNN (Factorization-machine supported Neural Network)
除了神经网络模型,FM模型也可以用来学习到特征的隐向量(embedding表示),因此一个自然的想法就是先用FM模型学习到特征的embedding表示,再用学到的embedding向量代替原始特征作为最终模型的特征。这个思路类似于LR+GBDT,整个学习过程分为两个阶段:第一个阶段先用一个模型做特征工程;第二个阶段用第一个阶段学习到新特征训练最终的模型。
FNN模型就是用FM模型学习到的embedding向量初始化MLP,再由MLP完成最终学习,其模型结构如下:
7. PNN(Product-based Neural Networks)
MLP中的节点add操作可能不能有效探索到不同类别数据之间的交互关系,虽然MLP理论上可以以任意精度逼近任意函数,但越泛化的表达,拟合到具体数据的特定模式越不容易。PNN主要是在深度学习网络中增加了一个inner/outer product layer,用来建模特征之间的关系。
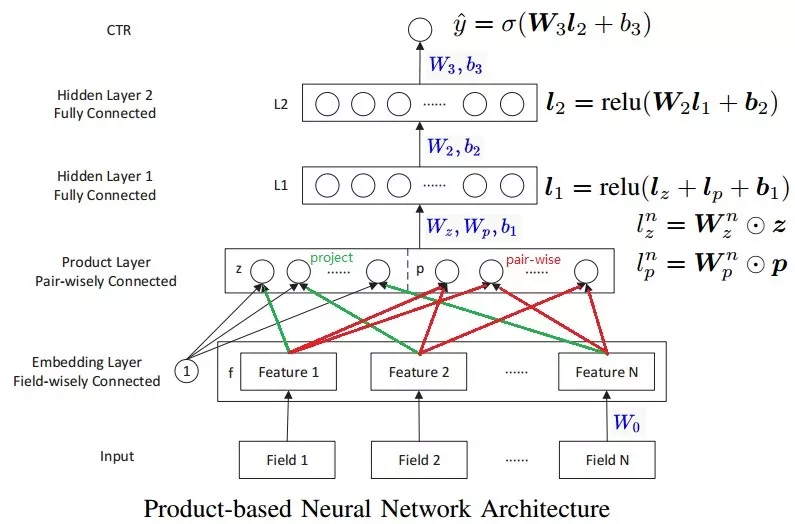
Embedding Layer和Product Layer之间的权重为常量1,在学习过程中不更新。Product Layer的节点分为两部分,一部分是
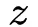 向量,另一部分是
向量,另一部分是
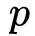 向量。
向量。
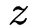 向量的维数与输入层的Field个数( N)相同,
向量的维数与输入层的Field个数( N)相同,
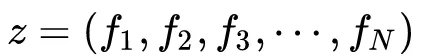 。
。
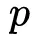 向量的每个元素的值由embedding层的feature向量两两成对并经过Product操作之后生成,
向量的每个元素的值由embedding层的feature向量两两成对并经过Product操作之后生成,
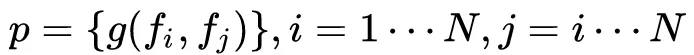 ,因此
,因此
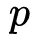 向量的维度为
向量的维度为
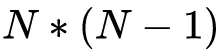 。这里的
。这里的
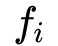 是field
是field
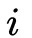 的embedding向量,
的embedding向量,
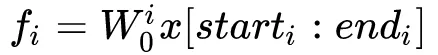 ,其中
,其中
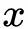 是输入向量,
是输入向量,
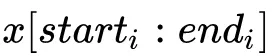 是field
是field
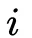 的one-hot编码向量。
的one-hot编码向量。
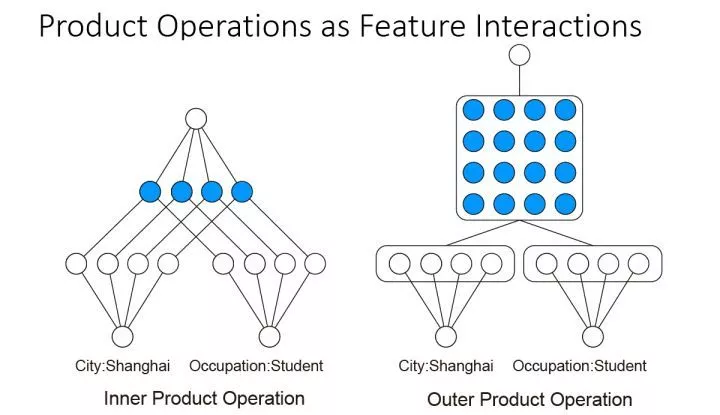
这里所说的Product操作有两种:内积和外积;对应的网络结构分别为IPNN和OPNN,两者的区别如下图。
在IPNN中,由于Product Layer的
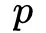 向量由field两两配对产生,因此维度膨胀很大,给
向量由field两两配对产生,因此维度膨胀很大,给
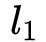 Layer的节点计算带来了很大的压力。受FM启发,可以把这个大矩阵转换分解为小矩阵和它的转置相乘,表征到低维度连续向量空间,来减少模型复杂度:
Layer的节点计算带来了很大的压力。受FM启发,可以把这个大矩阵转换分解为小矩阵和它的转置相乘,表征到低维度连续向量空间,来减少模型复杂度:
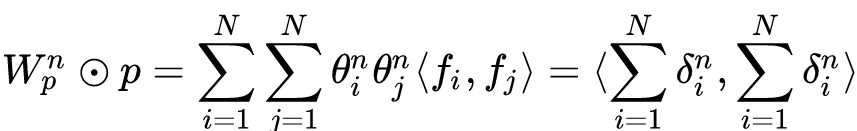
在OPNN中,外积操作带来更多的网络参数,为减少计算量,使得模型更易于学习,采用了多个外积矩阵按元素叠加(element-wise superposition)的技巧来减少复杂度,具体如下:
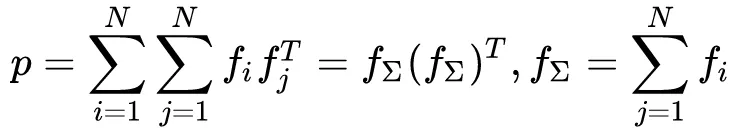 。
。
8. DeepFM
深度神经网络对于学习复杂的特征关系非常有潜力。目前也有很多基于CNN与RNN的用于CTR预估的模型。但是基于CNN的模型比较偏向于相邻的特征组合关系提取,基于RNN的模型更适合有序列依赖的点击数据。
FNN模型首先预训练FM,再将训练好的FM应用到DNN中。PNN网络的embedding层与全连接层之间加了一层Product Layer来完成特征组合。PNN和FNN与其他已有的深度学习模型类似,都很难有效地提取出低阶特征组合。WDL模型混合了宽度模型与深度模型,但是宽度模型的输入依旧依赖于特征工程。
上述模型要不然偏向于低阶特征或者高阶特征的提取,要不然依赖于特征工程。而DeepFM模型可以以端对端的方式来学习不同阶的组合特征关系,并且不需要其他特征工程。
DeepFM的结构中包含了因子分解机部分以及深度神经网络部分,分别负责低阶特征的提取和高阶特征的提取。其结构如下:
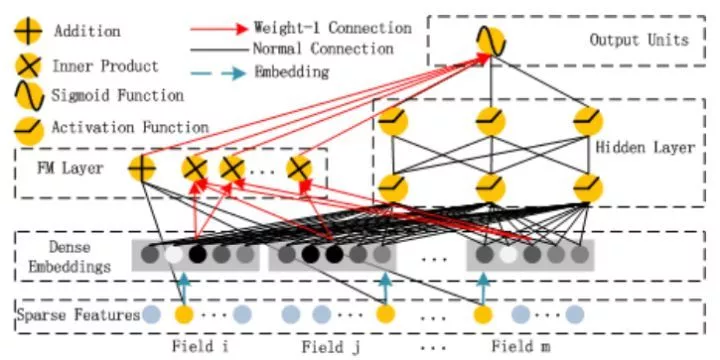
上图中红色箭头所表示的链接权重恒定为1(weight-1 connection),在训练过程中不更新,可以认为是把节点的值直接拷贝到后一层,再参与后一层节点的运算操作。
与Wide&Deep Model不同,DeepFM共享相同的输入与embedding向量。在Wide&Deep Model中,因为在Wide部分包含了人工设计的成对特征组,所以输入向量的长度也会显著增加,这也增加了复杂性。
DeepFM包含两部分:神经网络部分与因子分解机部分。这两部分共享同样的输入。对于给定特征
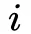 ,向量
,向量
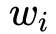 用于表征一阶特征的重要性,隐变量
用于表征一阶特征的重要性,隐变量
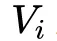 用于表示该特征与其他特征的相互影响。在FM部分,
用于表示该特征与其他特征的相互影响。在FM部分,
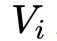 用于表征二阶特征,同时在神经网络部分用于构建高阶特征。所有的参数共同参与训练。DeepFM的预测结果可以写为
用于表征二阶特征,同时在神经网络部分用于构建高阶特征。所有的参数共同参与训练。DeepFM的预测结果可以写为
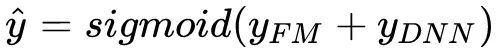 其中
其中
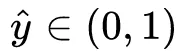 是预测的点击率,
是预测的点击率,
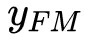 与
与
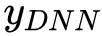 分是FM部分与DNN部分。
分是FM部分与DNN部分。
FM部分的详细结构如下:
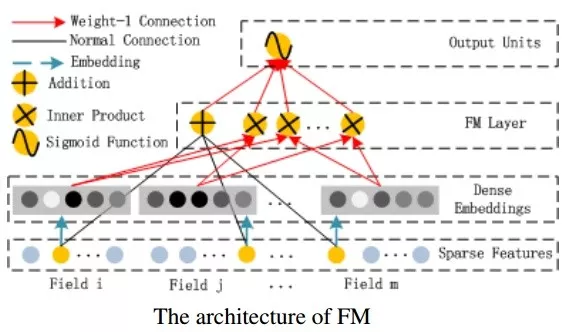
FM的输出如下公式:
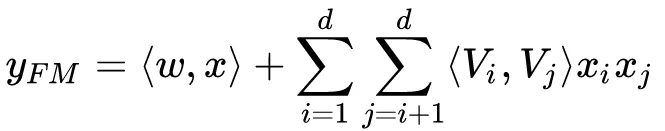
其中
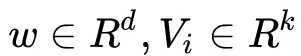 。加法部分反映了一阶特征的重要性,而内积部分反应了二阶特征的影响。
。加法部分反映了一阶特征的重要性,而内积部分反应了二阶特征的影响。
深度部分详细如下:
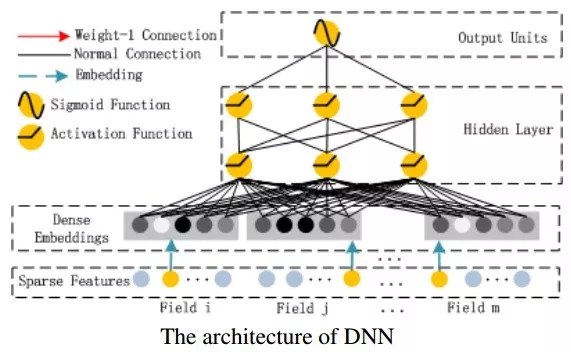
深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于CTR的输入一般是及其稀疏的。因此需要设计特定的网络结构,具体实现为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。
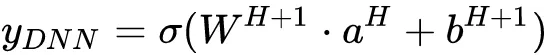
其中_H _是隐层的层数。
9. DIN
DIN是阿里17年的论文中提出的深度学习模型,该模型基于对用户历史行为数据的两个观察:1、多样性,一个用户可能对多种品类的东西感兴趣;2、部分对应,只有一部分的历史数据对目前的点击预测有帮助,比如系统向用户推荐泳镜时会与用户点击过的泳衣产生关联,但是跟用户买的书就关系不大。于是,DIN设计了一个attention结构,对用户的历史数据和待估算的广告之间部分匹配,从而得到一个权重值,用来进行embedding间的加权求和。
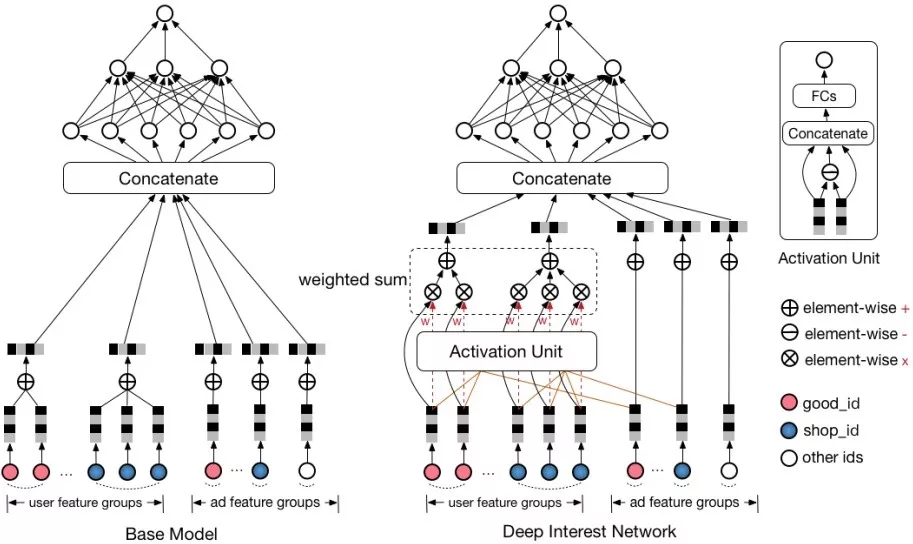
DIN模型的输入分为2个部分:用户特征和广告(商品)特征。用户特征由用户历史行为的不同实体ID序列组成。在对用户的表示计算上引入了attention network (也即图中的Activation Unit) 。DIN把用户特征、用户历史行为特征进行embedding操作,视为对用户兴趣的表示,之后通过attention network,对每个兴趣表示赋予不同的权值。这个权值是由用户的兴趣和待估算的广告进行匹配计算得到的,如此模型结构符合了之前的两个观察:用户兴趣的多峰分布以及部分对应。Attention network 的计算公式如下,
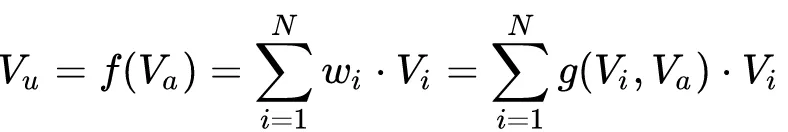
其中,
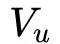 代表用户表示向量,
代表用户表示向量,
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%BB%E6%B5%81%E9%A2%84%E4%BC%B0%E6%A8%A1%E5%9E%8B%E7%9A%84%E6%BC%94%E5%8C%96%E5%8F%8A%E5%AF%B9%E6%AF%94/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


