为结构化数据注入深度学习的洪荒之力
近年来深度学习在 CV、NLP 等非结构化领域展现出超强的统治力,突破最高水平的算法层出不穷。深度学习在结构化和非结构化领域表现出来的巨大反差已成为热门话题,自从以 XGBoost、LightGBM 为代表的高性能集成树模型训练框架的问世,深度学习在结构化领域就一直没有超越配角的地位。到目前为止,Kaggle 结构化数据竞赛中,传统机器学习算法依然是最主要的赢家。
神经网络强大的表示学习能力真的在结构化数据上无法展现威力吗?近日由国内的数据科学平台领导厂商——九章云极发布的开源项目 DeepTables 正在打破这个局面。DeepTables(简称 DT)经过大量的测试验证,在使用相同数据训练模型的条件下,DT 在 70% 以上的测试数据集上超越 XGBoost 和 LightGBM,DT 团队后续会发布详细的测试报告。在 3 月 31 日刚刚结束的 Kaggle 竞赛 Categorical Feature Encoding Challenge II 中 DT 团队获得了第 1 名的成绩,其中 DT 的一个单模型得到第 3 名,这在 Kaggle 比赛动则用数十数百个模型 Ensemble 的标准动作下,单模型取得如此突出的成绩实属不易。
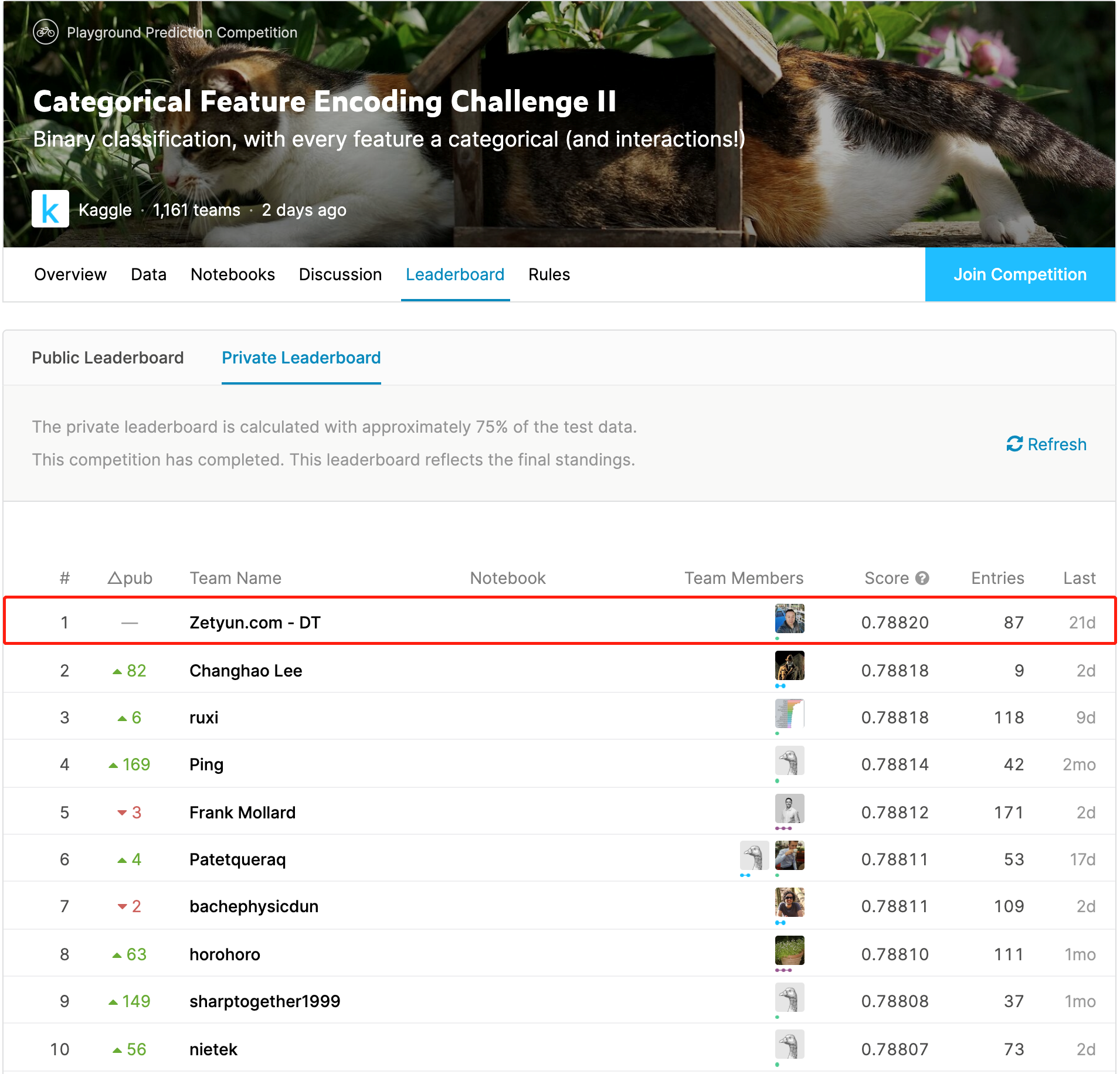
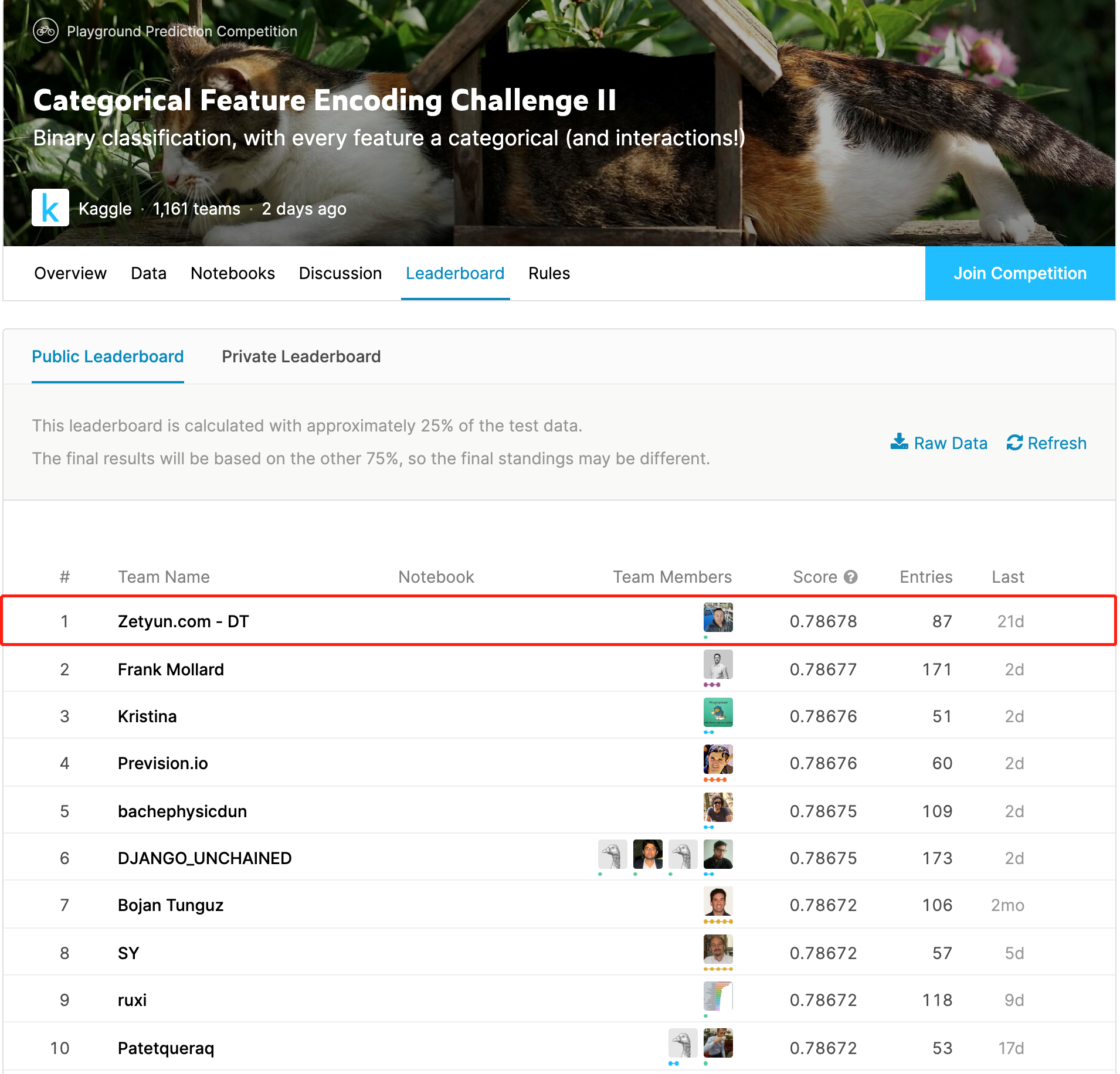
本届比赛来自全球的参赛队伍超过 1100 支,其中不乏 Bojan Tunguz, Sergey Yurgenson, KazAnova 这些 Kaggle 顶级大神的身影,Google 的 Auto Tables 也参加了本场比赛但排名在 300 以外,所以虽然是 Playground 类竞赛,但这个冠军的含金量依然不低,DeepTables 正在为深度学习正名。
实际近年来深度学习在结构化的一些细分领域里已经开始崭露头角,在 CTR 预测和推荐系统方面,神经网络算法利用其在高维稀疏特征上先进的表示学习能力逐步超越了传统机器学习算法。
◆ 从 2015 年 Google 公司的 Wide&Deep 网络开始,到 Deep&Cross、PNN、DeepFM、xDeepFM 这些模型不断刷新在公开数据集上的纪录。研究人员也在不断尝试将 CV、NLP 上的技术引入到结构化领域。
◆ 2019 年北京大学的研究团队提出的 AutoInt 网络应用了大名鼎鼎的 BERT 中 Multi-head Attention 思想,有效的提升了结构化数据自动特征生成和提取的效率,并且一定程度上解决了深度学习缺乏解释性的问题。
◆ 华为诺亚实验室提出的 FGCNN 在利用卷积神经网络的同时创新性的提出 Recombination Layer 将局部特征组合进一步重组,有效的避免了 CNN 过于关注局部特征交互的短板,FGCNN 在华为 AppStore 的推荐系统中大幅提升原有算法的表现。
以上成果确实足以让业界重拾深度学习在结构化数据上的信心,但目前这些成果主要在少数的互联网巨头企业中发挥价值,对于大多数企业和数据科学家来说只是看上去很美,想要应用到实际的建模工作中面临着不小的代价。
- 这些模型大多落在论文层面,部分论文虽然提供了用于验证模型的源码,但想把这些源码应用到实际业务上,代码改造的工作量和难度都不小。
- 结构化和非结构化数据之间最明显的区别是在结构化领域每一个数据集的语义空间和数值的物理含义都有所不同,同一个模型在不同数据集上的表现有时天差地别,常常需要同时评估各种不同模型才能找到最优方案,这也进一步放大了第 1 点中提到的工程代价。
- 上面提到的大部分模型重点解决的是高维稀疏的类别型特征的学习能力,对于连续型的数值特征关注有限,这个部分恰恰是 GBM 模型的杀手锏,因此遇到以连续型特征为主的数据集这�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%BA%E7%BB%93%E6%9E%84%E5%8C%96%E6%95%B0%E6%8D%AE%E6%B3%A8%E5%85%A5%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%9A%84%E6%B4%AA%E8%8D%92%E4%B9%8B%E5%8A%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


