为推荐系统生成高质量的文本解释基于互注意力机制的多任务学习模型
转自: 微软研究院AI头条
编者按:在个性化推荐系统中,如果能在提高推荐准确性的同时生成高质量的文本解释,将更容易获得用户的“芳心”。然而,现有方法通常将两者分开优化,或只优化其中一个目标。为了同时兼顾二者,微软亚洲研究院社会计算组结合认知科学的相关理论,提出了基于互注意力的多任务模型,并用充分的实验证明了模型的有效性。
近年来,个性化推荐系统极大地提升了用户遴选信息的效率。人们期望推荐系统能够掌握用户喜好,准确推荐用户感兴趣的商品。研究表明,在推荐的同时提供文字解释可以有效获得用户的信赖,增加推荐系统的说服力与满意度,因此推荐可解释性(explainability)成为新的研究热点。在之前的两篇文章( 《可解释推荐系统: 身怀绝技,一招击中用户心理》 及 《可解释推荐系统: 知其然,知其所以然》)中,我们探讨了可解释推荐的定义、目标、解释类型等,这篇文章中,我们将介绍我们的最新成果:高质量文本解释生成。
高质量文本解释生成在广泛的行业领域具有强大的应用前景,能够产生丰厚的经济和市场价值。比如在金融交易领域,市场上的潜在交易非常多,目前这类交易大多通过人工经纪方式促成。如果推荐算法准确且可以生成高度可解释的文本(如“出1个亿隔夜,买断质押皆可,中债AA以上,秒到,可拆分,走过路过不要错过”),就可以在极大程度上替代目前的人工判断,帮助挖掘用户的潜在交易对象,还有助于对交易员进行精确画像、促进对交易行为模式的理解、增加交易多样性等。
本研究由微软亚洲研究院与中国外汇交易中心合作完成。中国外汇交易中心是 微软亚洲研究院“创新汇” 成员,过去一年中,和微软亚洲研究院在金融交易智能辅助系统、金融交易知识图谱等方面开展了深入的合作。本研究中,我们关注可解释性中一个关键问题: 如何兼顾准确性和可解释性这两大要素,在生成高质量的文本解释的同时提高推荐准确性。现有方法通常将两者放在分开的两个步骤中单独优化,或是只优化其中一个目标,很大程度上限制了模型的表现。我们以两类应用最广泛的可解释推荐算法为例进行阐释。这两类可解释推荐算法为后处理(post-hoc)和嵌入式(embedded)。
后处理方法(图1(a))侧重于为已有的黑箱推荐模型提供解释。这类方法先优化模型准确性,再根据推荐结果生成解释。这样的方式丢失了推荐模型中包含的丰富信息,往往是通过预定义模板生成解释,既无法反映系统的真实推荐原因,也欠缺多样性,容易让用户觉得枯燥。
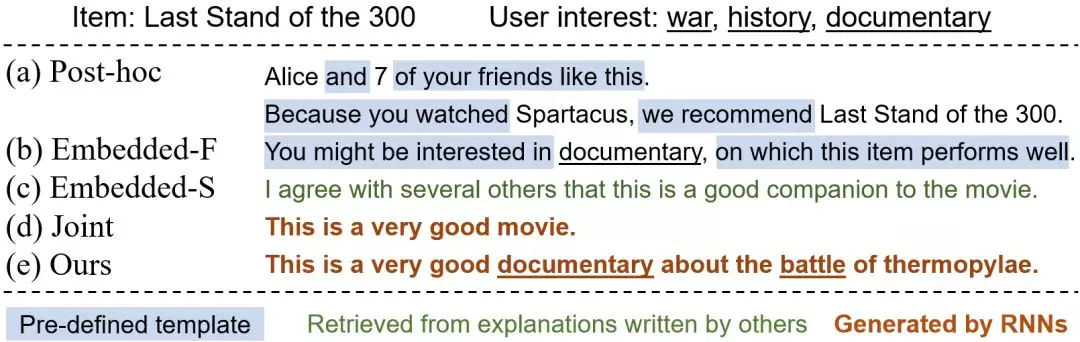
图1:不同的可解释推荐系统结果示例
嵌入式方法(图1(b)(c))将解释生成模块整合到推荐模型中,优化目标通常只考虑推荐准确性,解释由对提高推荐准确性最有效的重要特征或是句子构成。这种方法没有在优化目标中考虑可解释性,因此无法保证解释的质量及个性化程度。
那么,如何构建一个联合、统一的框架同时对推荐性和可解释性进行高效优化呢?一个直接的想法就是利用多任务学习。这是因为推荐与解释生成任务都需要对用户兴趣进行精细刻画,我们希望充分利用这两个任务之间的联系,使它们相互促进。
但是,简单地共享两个任务学习中所需的隐向量(比如用户隐向量和商品隐向量)进行多任务学习存在两个问题:一是这样的隐向量本身不包含直观的实际含义,不能在生成解释的时候给予显式约束,会使模型倾向于产生常见的套话(如图1(d)所示);二是简单的隐向量缺乏对用户与商品的深层次交互的学习,其表示能力不足,继而影响到推荐结果和解释生成。我们发现,解决这个问题的关键是要**对用户与商品之间的深层次交互进行显式、可解释的建模,并将建模结果作为约束直接影响解释生成和推荐结果。**这样不仅能够提高解释效果(如图1(e)所示),还可以促进推荐准确性的提高。
模型框架
受认知科学的相关启发,在IJCAI 2019上,我们提出了一种基于互注意力机制的多任务学习模型CAML。在认知科学中,人类进行信息处理的过程分为三个子阶段:(1)将输入信息进行编制、转换的编码阶段(encoding);(2) 选择编码信息中重要的片段并利用合适的形式(如网络)进行存储的存储阶段(storage);(3) 在实际任务中激活、解码存储的重要信息并依此做出决策的检索阶段(retrieval)。我们将认知科学中的三个阶段分别对应到框架中的三个子部分,设计了包含编码器(encoder)、选择器(selector)、解码器(decoder)三部分的多任务学习架构。其中编码器对应的是对输入信息进行编制、转换的编码阶段;选择器挑选对用户、商品都重要的概念作为推荐及解释任务的共有知识(cross knowledge),对应存储阶段;解码器利用共有知识分别进行推荐和解释生成,对应的是在实际任务中激活存储的重要信息并依此做出决策的检索阶段。
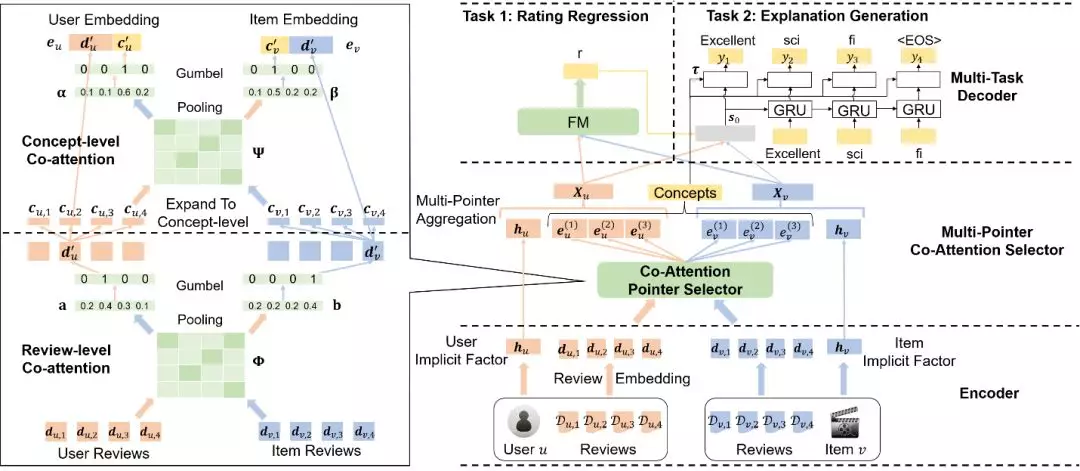
图2:基于互注意力的多任务学习模型 CAML
CAML 的模型框架如图2所示,模型需完成的具体任务是:给定用户u,商品v,以及用户与商品的历史点评信息,预测出用户对该商品的评分r,同时产生一条文字解释阐述用户喜欢或不喜欢该商品的原因。同时,为了提取历史点评中的重要信息及特征,我们利用 微软概念图谱(Microsoft Concept Graph) 筛选出点评中的重要概念词(concept)。下面我们对编码器、选择器、解码器分别进行具体介绍。
编码器 主要由两部分组成:(1)文字编码器将点评中的每个词编码为词向量,综合点评中的全部词向量,我们可以对该点评进行编码;(2)用户及商品隐表示编码器学习用户及商品的隐向量,用这些隐向量对其显式特征信息进行补充。
选择器 意在遴选对推荐与解释生成任务来说都很重要的点评以及概念,作为两个任务共有的知识。与强化学习方式相比,多指针互注意力网络能够更好地建模用户与商品的深层信息交互,拥有更好的学习效率及收敛性。受此启发,我们设计了一种层级的多指针互注意力选择器(multi-pointer co-attention selector),仅对重要信息进行保留。
具体地,每个指针(pointer)对应两层互注意力网络,分别选择一个用户或商品概念。我们以选择用户概念为例进行说明,选择商品概念可以以类似的方式进行。第一层互注意力网络,利用点评编码计算用户点评在商品历史点评中的相关程度。综合用户与商品各个点评之间的互注意力,模型便可在点评这一层面挑选出用户最重要的历史点评。由于选择过程中 argmax 函数不可导,难以进行梯度回传,我们采用近期研究工作中提出的 Gumbel Softmax 函数,在正向传播时使用硬性注意力,反向传播中仍保持软性注意力来保证梯度正常回传。在筛选出用户最重要的点评后,我们将点评展开到概念(concept)这一层次,利用第二层互注意力网络计算每个概念的作用,选择点评中最为重要的概念作为对用户点评信息的补充。
考虑到用户在进行评分或点评时可能参考多个历史点评,我们重复单指针选择器的操作,可得到多组点评与概念编码。我们利用非线性层将这些用户及商品编码进行整合,通过选择器获得基于互注意力的用户表示和商品表示,它们与用户及商品的隐向量共同组成了完整的用户及商品表示。
解码器 结合用户与商品表示,同时对推荐与解释生成进行优化。推荐任务中,我们使用因子分解机(Factorization machine)计算用户对商品的评分;解释生成中,我们利用循环神经网络 GRU 迭代地生成文字解释,预测的评分也作为输入信息以保持解释与评分的一致性。同时,我们结合选择器中挑出的重要概念词设计了新的代价函数,显式地激励模型生成包含概念词的文字解释,从而提升生成解释的质量及信息量。
综上,我们设计了基于互注意力机制的多任务学习模型,从更深层次刻画了用户与商品的信息交互,能够互补地学习对推荐及解释生成都有作用的历史信息。
实验结果
我们在亚马逊的电器、电影电视以及 Yelp 三个不同类型的公开数据集上对上述模型进行评测。我们采用常见的评价指标 Bleu 和 ROUGE 对生成解释的质量进行评测,将 CAML 与各种主流的解释生成模型进行对比,其结果如表1所示。在三个数据集上,CAML 的各个指标均超过了基准模型,其中 Bleu 得分在最优的基准算法的基础上均取得了14.6%以上的提升。
为了更好地说明 CAML 能够生成高质量的解释,我们还进行了人工评测,其结果如图3所示。与基准模型相比,我们生成的文本解释在流畅性和实用性上都取得了提升。生成的解释样例如表2所示。从表中可得知,我们生成的解释富有信息量,解释中包含的概念与用户的真实兴趣十分契合。这显示出我们设计的“编码器—选择器—解码器”架构和多指针互注意力选择器的有效性,以及建模深层次用户、商品交互和显式限制解释生成对提升解释生成�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%BA%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E7%94%9F%E6%88%90%E9%AB%98%E8%B4%A8%E9%87%8F%E7%9A%84%E6%96%87%E6%9C%AC%E8%A7%A3%E9%87%8A%E5%9F%BA%E4%BA%8E%E4%BA%92%E6%B3%A8%E6%84%8F%E5%8A%9B%E6%9C%BA%E5%88%B6%E7%9A%84%E5%A4%9A%E4%BB%BB%E5%8A%A1%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


