与索引设计
分享嘉宾: 毕杰山** ** 华为云 主任工程师
内容来源: HBase MeetUp《HBase RowKey与索引设计》
出品社区: DataFun
今天分享的内容主要是HBase RowKey与索引设计相关的一些技巧、原则和相关案例。将分以下四部分分析,第一部分简单介绍HBase基础知识,第二部分探讨合理的需求调研方法,第三部分是关于RowKey与索引设计的一些技巧、原则,第四部分是关于OpenTSDB/JanusGraph/GeoMesa典型案例的设计分享。

一、HBase基础
第一部分包括基础概念与数据模型介绍、快速浏览读写流程、介绍RowKey在读写流程中发挥的作用。
首先是基本概念介绍。
Table: 同传统数据库中的表是类似的,但他的不同之处在于它是基于SchemaLess的设计,比传统数据库表更加灵活。
Region : 将表横向切割成一个个子表,从而实现分布式的存储,子表在HBase中称作Region,它关联了数据的一个区间。
Column Family: HBase可以将一行数据分成不同列的集合,这些列的集合称为Column Family,不同的Column Family文件被存储在不同的路径中。
RegionServer: 指HBase里面数据服务的进程,每个Region必须要分到RegionServer上才能提供正常的读写服务。
MemStore: 用来在内存中缓存一定大小的数据,达到一定大小后批量写入到底层文件系统中。
HFile: HBase数据在底层分布式文件系统中的文件组织格式。
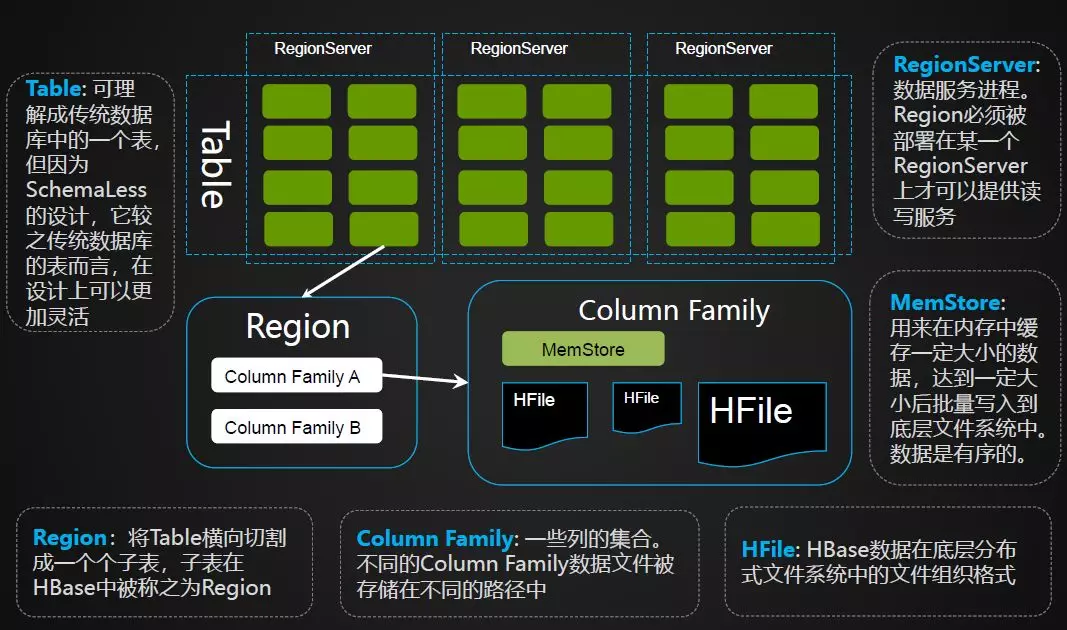
关于进程角色如下图,主要有ZooKeeper、Master、RegionServer等角色。Meta表的路由信息在ZooKeeper中;Master负责表管理操作,Region到各个RegionServer的分配以及RegionServer Failover的处理等;RegionServer提供数据读写服务。HBase的所有数据文件都存放在HDFS中。
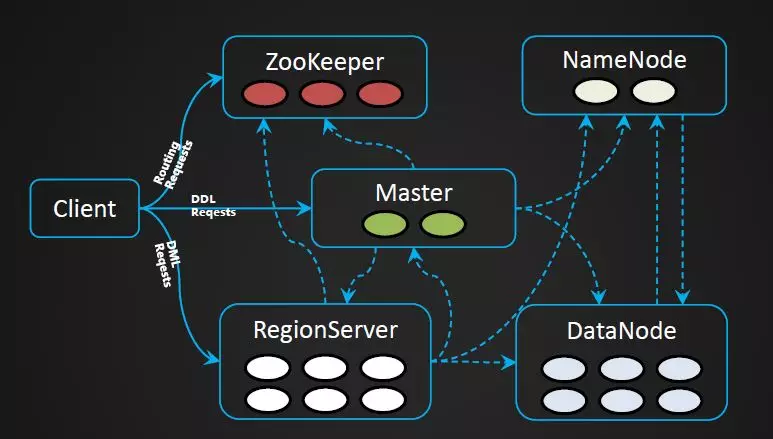
我们先来理解一下KeyValue的概念。在HBase中所存储的数据,是以KeyValue形式存在的。KeyValue拥有特定的组织结构,如下图所示。一个KeyValue可以理解成HBase表中的一个列,当一行存在多个列时,将包含多个KeyValue。同一行的KeyValue有可能存在于不同的文件中,但在读取的时候,将会按需合并在一起返回给客户端。用户写数据时,需要定义用户数据的RowKey,指定每一列所存放的Column Family,并且为其定义相应的Qualifier(列名),Value部分存放用户数据。HBase中每一行可拥有不同的KeyValues,这就是HBase Schema-Less的特点。
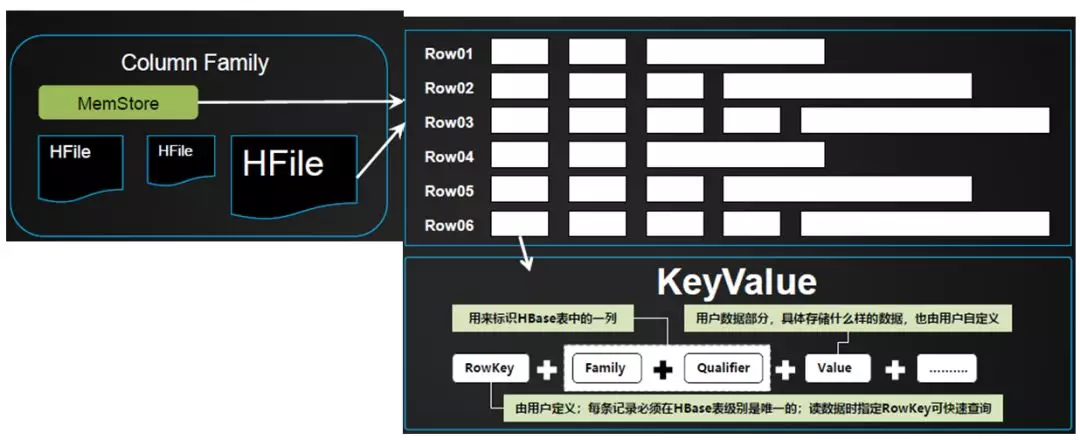
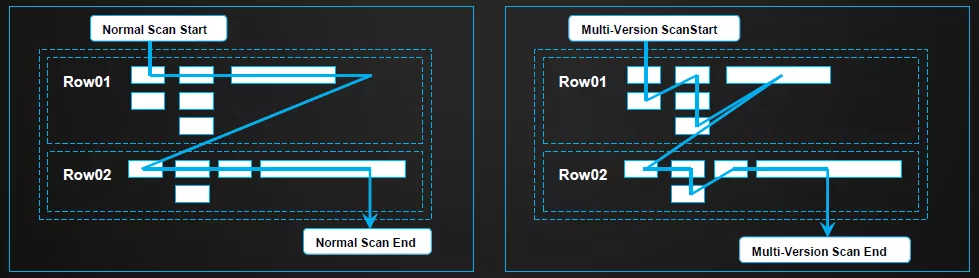
下面介绍KeyValue多版本。HBase中支持数据的多版本,通过带有不同时间戳的多个KeyValue版本来实现的。HBase所保存的版本数目是可配置的,默认存放3个版本。在普通的读取流程中,旧版本的数据是不可见的,但通过指定版本数或者版本号的读取,可以获取旧版本数据。下图是普通读取流程与多版本读取流程的对比。
用户数据存入到HBase表中时,需要进行Qualifier (KeyValue/Qualifier(KeyValue/列) 设计。一个最简单的设计是保持HBase的列与用户数据一致,如下图1的设计。这种,基本上与关系型数据库的设计是一致,但这种会带来较大冗余 (KeyValue结构化开销)。但HBase 基于KeyValue的接口,决定了这种设计可以是非常灵活的,例如我们也可以考虑为HBase的每一行只设置两个列,其中Name为一个列,其它内容合并到一个列中,如下图2所示。
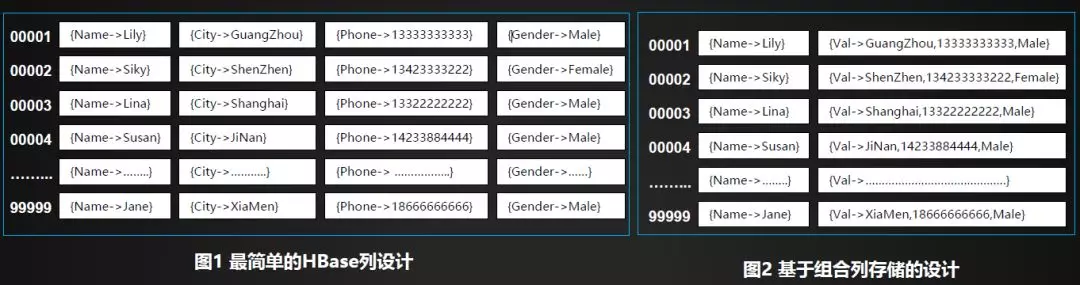
尽管我们在使用HBase表存放数据的时候,需要预先做好列设计。但这个设计仅仅由应用层感知,HBase并没有存放任何的Schema信息来描述这个设计。也就是说,应用层需要知道为每一表/每一行设计了什么样的列(KeyValue),然后在读取的时候做相应的解析。然HBase中并没有Schema信息,那么每一行中的列,也可以是任意添加的。如上图所示,绿色背景的KeyValue为后续增加的。
关于Column Family,前面提到它是列的集合。每个Column Family里面关联了一个MemStore,关联了多个HFile文件。当我们在选择是否要应用多个Column Family的时候,需要调研所读写应用的业务特点,有些数据可能会一起写入,有时候临时增加数据,此时可以考虑用两个Column Family。如下图所示,假设为表设置了两个列族,而且定义每一个列族中要存放的列:{Name}->Column Family-A,{City,Phone,Gender}->Column Family-B 不同列族的数据会被存储在不同的路径中。即设置多个列族时一行数据可能存在于两个路径中。整行读取的时候,需要将两个路径中的数据合并在一起才可以获取到完整的一行记录。但如果仅仅读取Name一列的话,只需要读取Column Family-A即可。
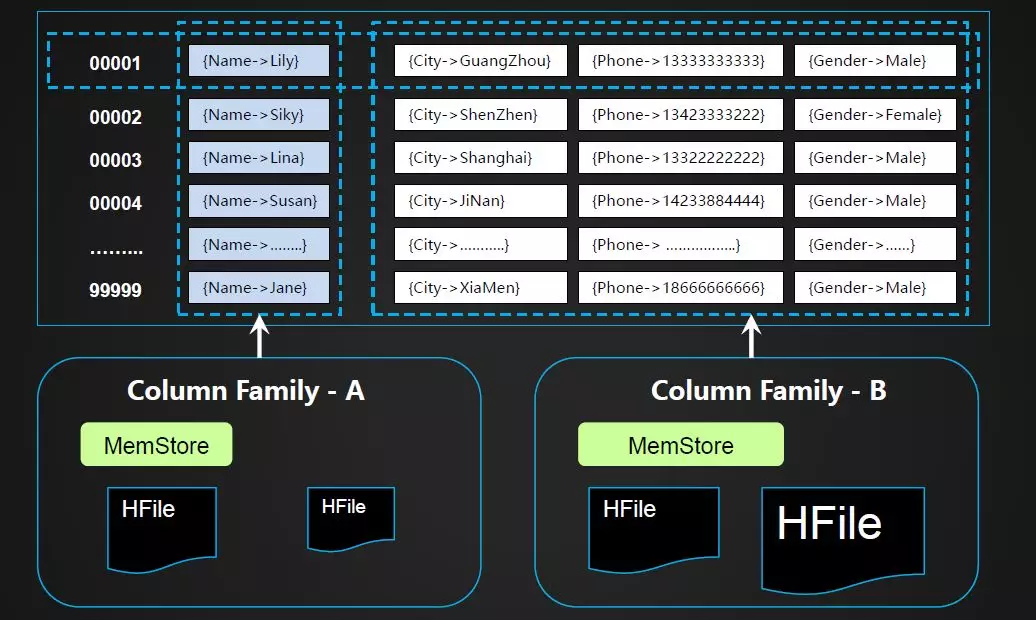
下图所示,读写数据的简单路由机制。一开始会先去ZooKeeper中获取Meta表的路由信息,然后在Meta中定位每条数据关联的用户Region路径。下面这部分是基于RowKey从Meta表定位关联Region方法,通过一个反向扫描的方式进行。
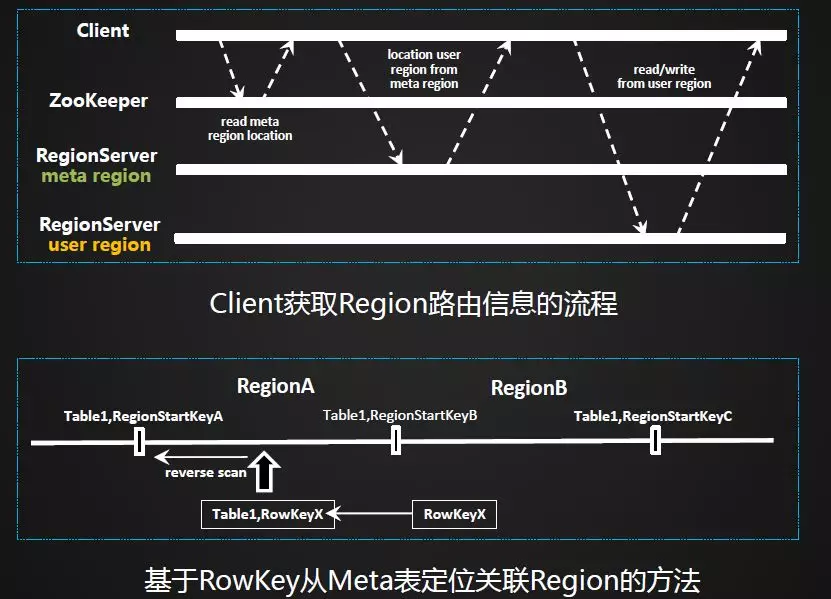
下面介绍一下写入流程。客户端通过发请求到RegionServer端,写入的时候会先写入WAL日志中,其次会将数据写入memstore内存,当数据达到一定大小后会flush成一个个的HFile文件,当文件达到一定数量后,通过compaction的操作合并成更大文件,这样数据读取会更快。
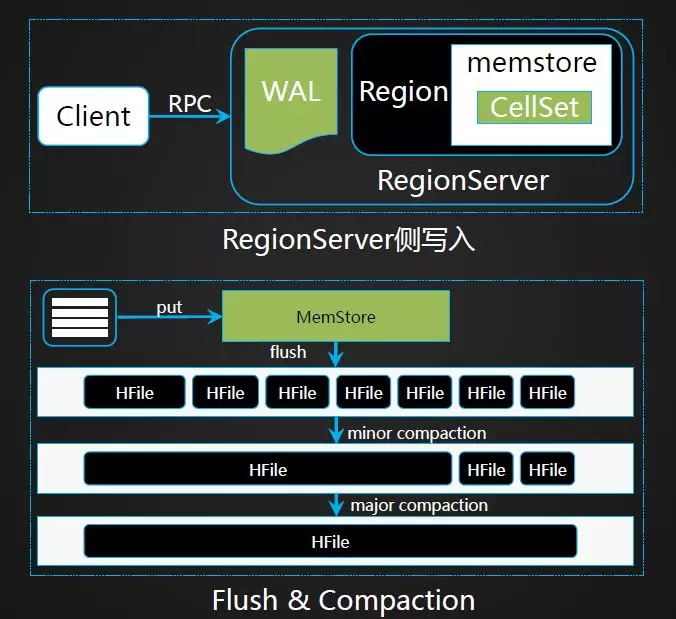
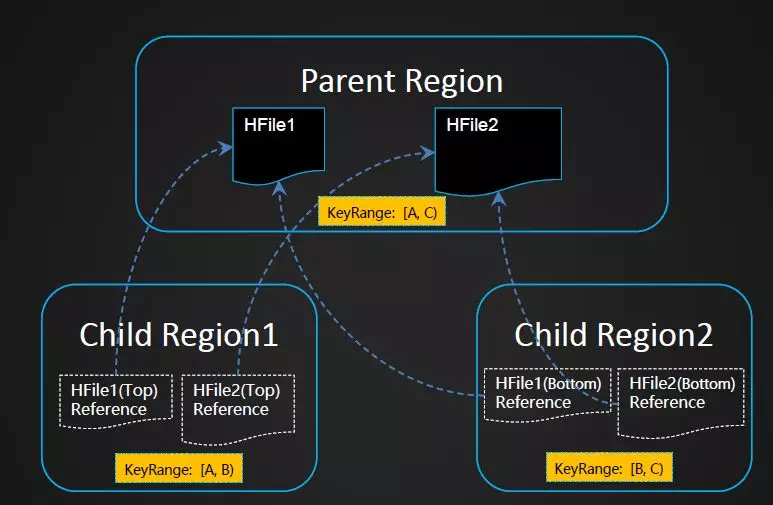
Region Split。有人可能会有疑问,分裂的时候需不需搬迁数据?当一个Region变的过大后,会触发Split操作,将一个Region分裂成两个子Region。Region Split过程并不会真正将父Region中的HFile数据搬到子Region目录中。Split过程仅是在子Region中创建了到父Region的HFile引用文件,子 Region1中的引用文件指向原HFile的上部,而子Region2的引用文件指向原HFile2的下部。数据的真正搬迁工作是在 Compaction过程完成的。
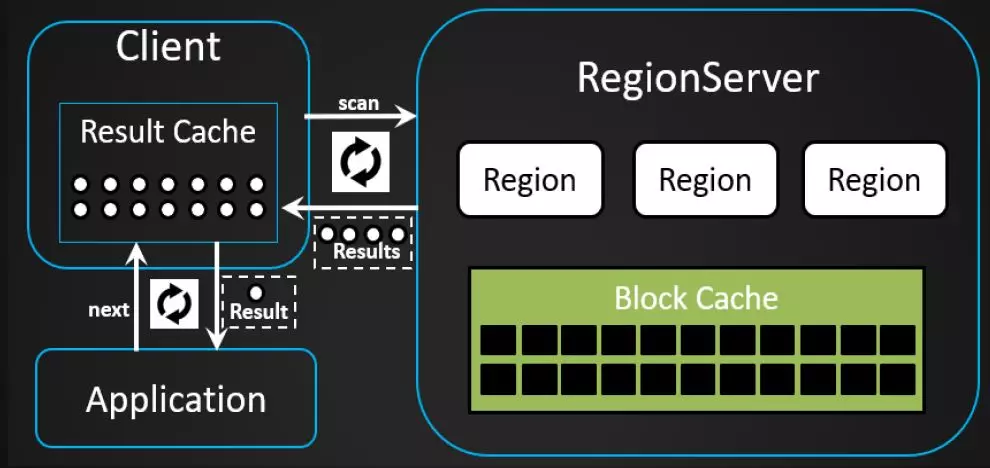
下面是读取流程。当进行读取时,客户端会先发送scan请求到RegionServer,打开scanner,然后调next请求获取一行数据,也可以将一批数据先放入Result的Cache中去,客户端不断迭代获取内容,scan每次获取多少行数据通常需要结合自己业务特点去获取合理的值。
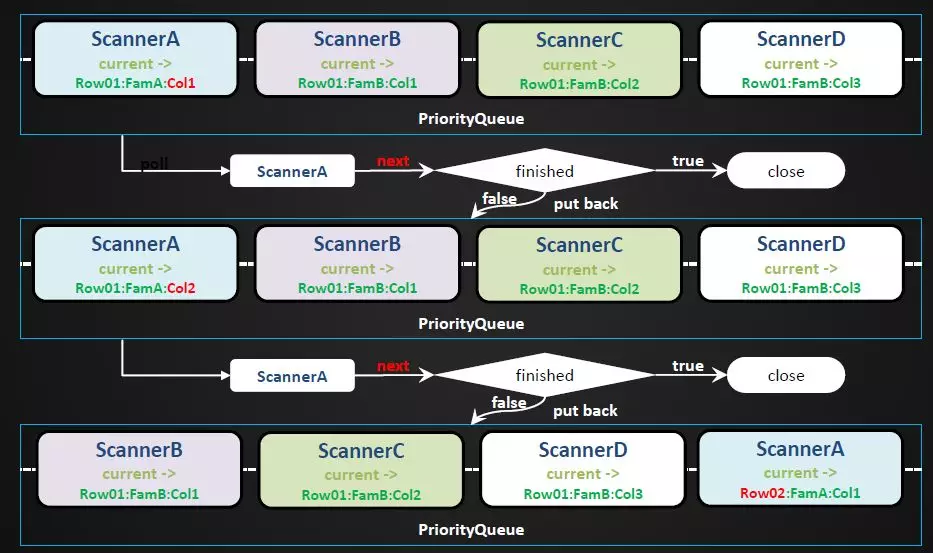
关于Scanner的抽象。由于数据一开始会先写入MemStore,当数据达到一定大小以后再Flush成底层文件,那么在读取的时候首先需要解决的问题是什么?因为数据可能存在于多个列族中,然后每个列族里又有内存里面的数据,还有些数据可能存在于多个文件中,那么应该如何读取呢?这里涉及到数据的抽象,这里将Region的读取会封装成ResultScanner对象,每个列族封装成StoreScanner对象,每个StoreScanner里面又有多个HFile、MemStore等。StoreScanner包含一个SegmentScanner和多个StoreFileScanner,这些Scanner会被组织在优先级队列里面,在Scan的时候一定会优先指定一个起始Key的值,Scanner在打开的时候会将指针定位到指定Key的位置,每个Scanner在打开的时候会对KeyValue 进行排序,然后放入一个优先级队列中。然后客户端每次通过Next请求驱动Scan的调用,Scanner Next请求调用如下图所示,用ScannerA-D表示上面提到的各种Scanner,当依次Next请求调用时,会判断哪个Scanner的数据是最小的。比如ScannerA先读,读取KeyValue数据,然后判断Scanner是否读取完毕,是否超出了Scan范围,假如没有读完会被再次丢回队列,重新排序,如此循环获取数据。
关于HFile的组织结构。HFile中数据按Block组织,一个Data Block的默认大小为64KB,Data Block中直接存储了KeyValue信息,最底层的Block是Leaf Index Block,Data Block的索引信息存储在Leaf Index Block中。而Leaf Index Block的信息存储在 Root Index中(不考虑Intermediate Index Block情形)。从Root Index Block到Leaf Index Block Leaf Index BlockLeaf Index Block Leaf Index Block Leaf Index BlockLeaf Index Block再到 Data Block,以及从 Data Block到用户数据 KeyValue的 数据组织,正是一种典型的B + Tree结构。
下面我们回顾一下RowKey在读写流程中发挥的作用:
读写数据时通过RowKey路由到对应的Region,MemStore中的数据按RowKey排序,HFile中的数据按RowKey排序。
RowKey的设计直接关乎Region的划分,我们如何划分Region?
首先通过分析业务读写吞吐量以及总的数据量信息,设定合理的Region数量目标,接下来预先定义RowKey的结构以及数据分布特点划分RowKey区间,然后按照设定的Split信息建表。
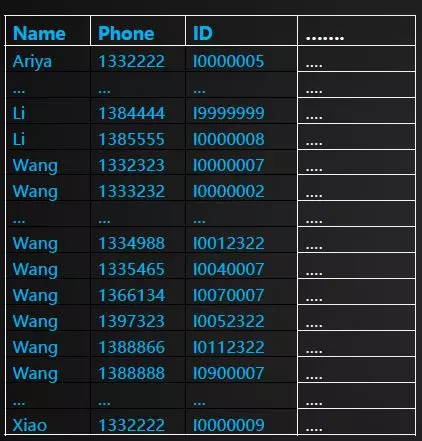
RowKey查询的局限性。根据下表信息,基于Name+Phone+ID构建RowKey。如果提供的查询条件能够尽可能丰富的描述RowKey的前缀信息,则查询时延越能得到保障。如下面几种组合条件场景:Name+Phone+ID、Name+Phone、Name。如果查询条件不能提供Name信息,则RowKey的前缀条件是无法确定的,此时只能通过全表扫描的方式来查找结果。一种业务模型的用户数据RowKey,只能采用单一结构设计。但事实上,查询场景可能是多维度的。例如在上面的场景基础上,还需要单独基于Phone列进行查询。这是HBase二级索引出现的背景。即二级索引是为了让HBase能够提供更多维度的查询能力。
注意:HBase原生并不支持二级索引方案,但基于HBase的KeyValue数据模型与API,可以轻易地构建出二级索引数据。Phoneix提供了两种索引方案,而一些大厂家也都提供了自己的二级索引实现。
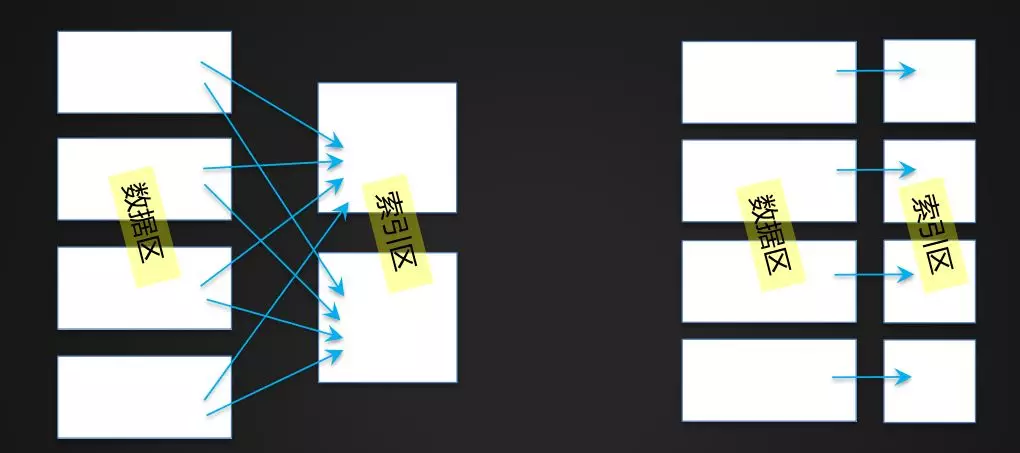
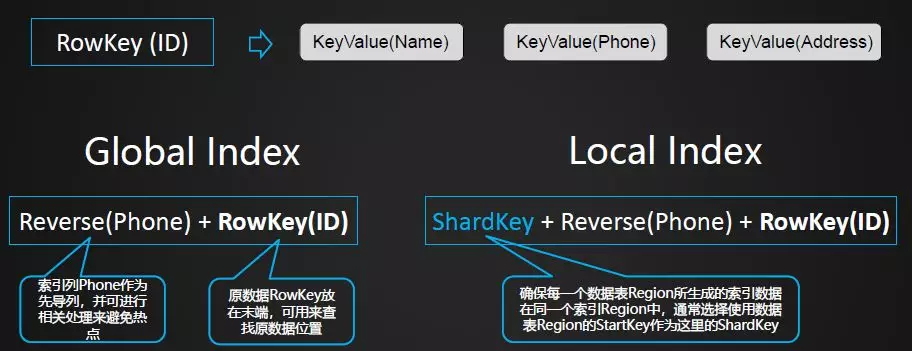
常见的两种二级索引。方案一全局索引(下右图)、方案二本地索引(下左图)。方案一优点:数据按索引字段全部排序,基于索引字段的小批次查询性能高。能够支持更大的查询并发数。方法的复杂度较低。缺点是:生成索引数据对实时写入的影响较大。方案二优点:每一个用户Region都拥有独立的索引数据,目前最佳的实践是将这部分索引数据存放于一个独立的列族中。方案缺点:按索引字段进行查询时,需要访问所有的索引Region,随着数据量和Region数目的不断增多,查询时延无保障,查询所支持的并发数也会降低。
二、合理的需求调研
这部分主要介绍一下在设计RowKey之前如何合理地调研,RowKey设计的目标是将数据合理地分配到每一个Region中,从而很好地满足业务的读写需求。索引设计目标是为HBase提供更多维度的查询能力,在实际应用中应该通过构建尽量少的索引,来满足更多的查询场景。
需求调研的关键维度有: 负载特点、查询场景、数据特点。
负载特点指的是读写TPS大小以及读写比重,数据负载均衡与高校读取时常是矛盾的,在重度轻写的大数据场景中,RowKey设计应该更侧重于如何高校读取,而在重写轻读的大数据场景中,在满足基本查询需求的前提下,应该更关注整体的吞吐量,这就对数据的负载均衡提出了很高的要求。
查询场景指需要支持哪些查询场景?时延要求?最高频的查询场景是什么?是否有其它维度的价值查询场景?频度?是否有组合字段场景?各个字段的匹配类型?
数据特点,涉及到的问题有:
1. 查询条件字段的离散度信息?字段离散度是指字段A的离散度等于字段A的可能枚举值数目除以数据总记录条数。
2. 查询条件字段的数据分布特点?数据分布影响RowKey的设计,更进一步影响如何合理的划分Region信息。
3. 数据生命周期?因为生命周期影响到一个表的一次Major Compaction发生时涉及到的最大数据量。
三、RowKey与索引设计
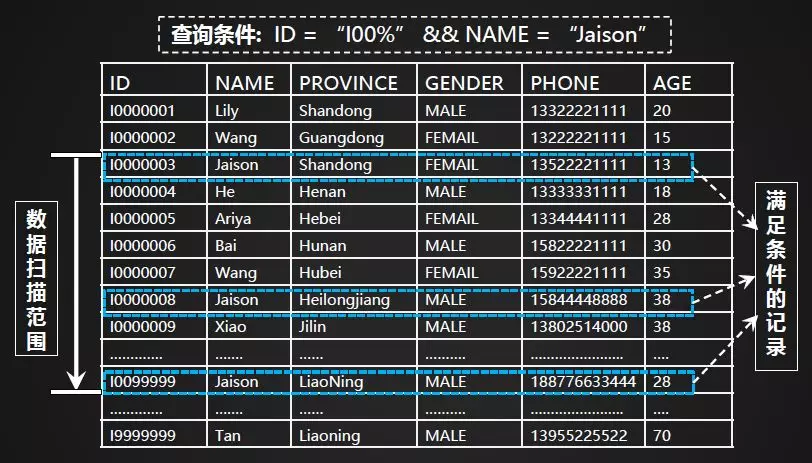
首先看一下影响查询性能的关键因素是什么?基于某一个索引/RowKey进行查询时,影响查询的关键因素在于是否将扫描的候选结果集限定在一个合理的范围内,如下图所示。知识点备注:直接影响数据扫描范围的查询条件,称之为查询驱动条件。而其它的能够起到过滤作用的查询条件,则称之为查询过滤条件。影响查询的关键因素在于如何合理的设置查询驱动条件。
RowKey字段的选取,遵循的基本原则是唯一性,RowKey必须能够唯一的识别一行数据。无论应用是什么样的负载特点,RowKey字段都应该参考最高频的查询场景。数据库通常都是以如何高效的读取和消费数据为目的,而不是数据存储本身。而后,结合具体的负载特点,再对选取的RowKey字段值进行改造,组合字段场景下需要重点考虑字段的顺序。
避免数据热点的方法:
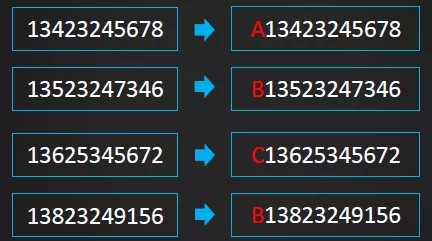
(1) Reversing
如果经初步设计出的RowKey在数据分布上不均匀,但RowKey尾部的数据却呈现出了良好的随机性,此时,可以考虑将RowKey的信息翻转,或者直接将尾部的bytes提前到RowKey的前部。

(2) Salting
Salting的原理是在原RowKey的前面添加固定长度的随机bytes,随机bytes能保障数据在所有Regions间的负载均衡。缺点:既然是随机bytes,基于原RowKey查询时无法获知随机bytes信息是什么,也就需要去各个可能的Regions中去查看。可见Salting对于读取是利空的。
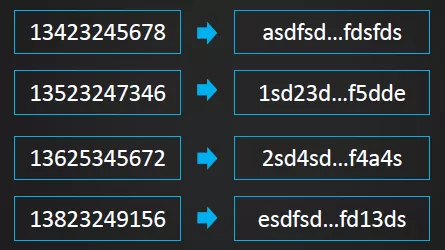
(3) Hashing
基于RowKey的完整或部分数据进行Hash,而后将Hashing后的值完整替换原RowKey或部分替换RowKey的前缀部分。缺点是与Reversing类似,Hashing也不利于Scan,因为打乱了原RowKey的自然顺序。
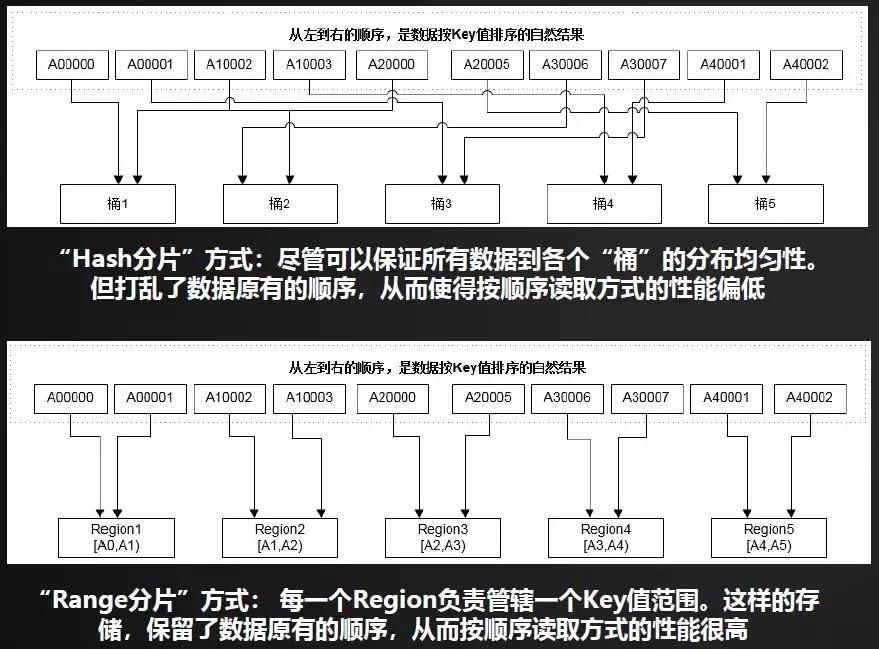
接下来介绍一个小的知识点,分布式数据库的常见数据分片方式。两种常见的基础数据分片方式有Hash分片、Range分片。原理与区别见下图,在实际应用中,两者还可以结合应用。HBase采用了基于RowKey分区的方式。
二级索引RowKey设计常见方法:
(1)无Schema模式
下图是常见设计思路,如果原数据RowKey中已经包含了索引列的信息,该设计容易导致数据冗余。
(2)有Schema模式
当原数据RowKey中的列与索引列有重叠时,该设计能避免一个列在索引列中被重复存储。但该设计需要事先支持Schema,也就是需要事先定义原数据的RowKey结构以及索引的结构信息。

二级索引字段的选取:
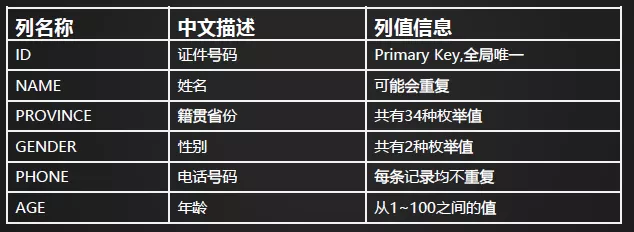
对所有的价值查询场景进行详细分析,基于确实能够缩小查询范围的一部分列来构建二级索引。即我们应该基于离散度较好的一些列来构建索引。如下图所示,字段ID,PHONE的离散度为1,基于这些字段构建索引是最佳的,而字段PROVINCE与GENDER,AGE的离散度较差,不适合用来构建二级索引。
组合索引适用场景/构建原则:
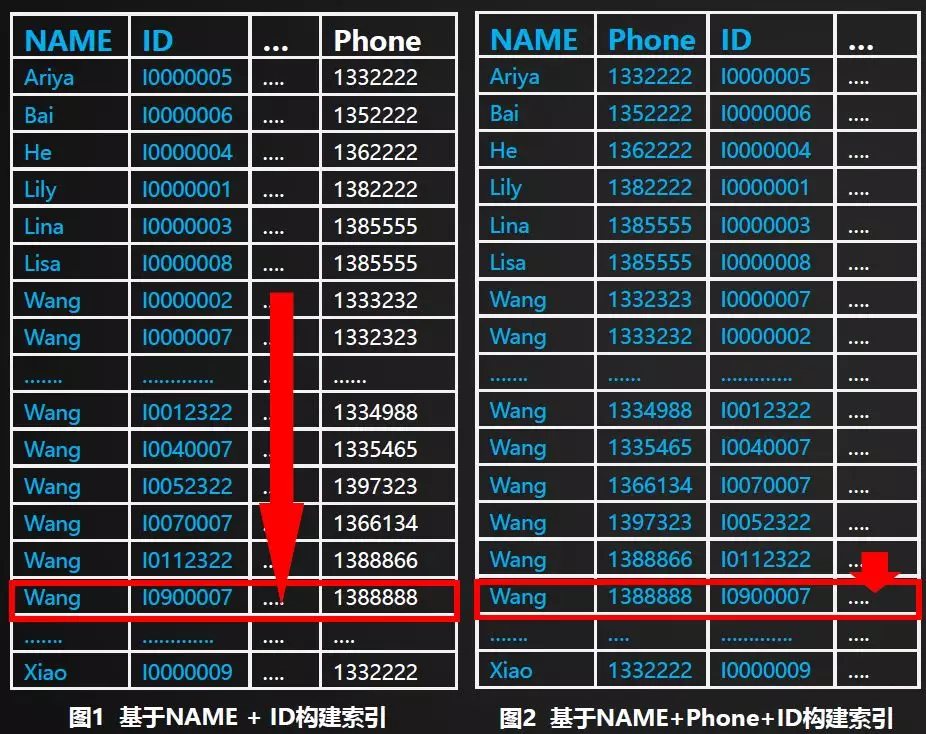
组合索引的创建,取决于对用户查询场景的详细分析。组合索引的确可极大的优化这些字段组合时的查询场景,但却会带来相对较大的数据膨胀。在不了解用户数据特点以及用户查询场景的情形下,盲目的构建组合索引,是要坚决避免的。举例如下图,假设查询条件为NAME=”Wang” && Phone=”1388888” 如果基于NAME构建索引,则依然可能需要扫描大量的数据,才可以找到一条目标记录,如下图1所示。如果基于NAME+Phone构建索引,则可以更精确地命中目标记录,如下图2所示。查询性能可大幅度提升。
组合索引中字段组合的顺序:
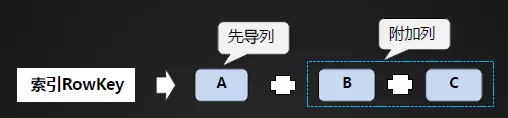
先导列的选取:
(1) 被选作先导列的列,一定是经常被用到的列;
(2) 应选择设置了EQUALS查询条件的列作为先导列;
(3) 先导列应该具备较好的离散度;
(4) 尽量不要重复选择其它索引的先导列作为本索引的先导列。
附加列的选取:
(1) 提供了EQUALS查询条件的列,应该放在前面部分;
(2) 由于列的组合顺序将会影响到数据的排序,我们也应该考虑业务场景关于排序的诉求;
(3) 几何各个列的离散度进一步分析,将这些组合之后,能否将数据限定在一个合理的范围之内?如果不能,需要结合查询场景设置更合理的组合列。
关于索引的其他建议:
1. 严格控制二级索引的数量。每一个索引所关联的数据总条数,与用户是1:1的。因此,在为一个用户表定义二级索引时,应该要考虑多个索引所带来的存储空间膨胀以及性能下降问题。建议在充分分析了各种查询场景的情况下,通过构尽量少索引来满足更多的查询场景。
2. Global Index。在高并发/小批次查询场景中更有利。查询一个Local Index时,需要去查看每一个Index Region才能获取到符合条件的完整结果集,这对高并发查询不利。但 Local Index对于并发分析场景却是有利的。
3. 全文检索需求可考虑与Elasticsearch/Solr对接。Elasticsearch/Solr是专业的索引引擎,但不适合作为数据主存系统,因此,将核心数据存放在HBase中,而通过ES/Solr构建全文索引能力,是一种常见的组合应用场景。
四、设计案例分享
关于OpenTSDB设计分析、JanusGraph设计分析、GeoMesa设计分析三个案例,将从数据模型、典型查询场景、RowKey设计三个方面介绍。
1. OpenTSDB
OpenTSDB数据模型如下图,一个Time Series可以理解成是一个数据源的一个指标按时间产生的指标数据序列,每一个指标称之为一个Data Point。OpenTSDB使用一个Metric Name以及一组Tags信息来唯一确定一个Time Series。每一条记录成为Data Point。
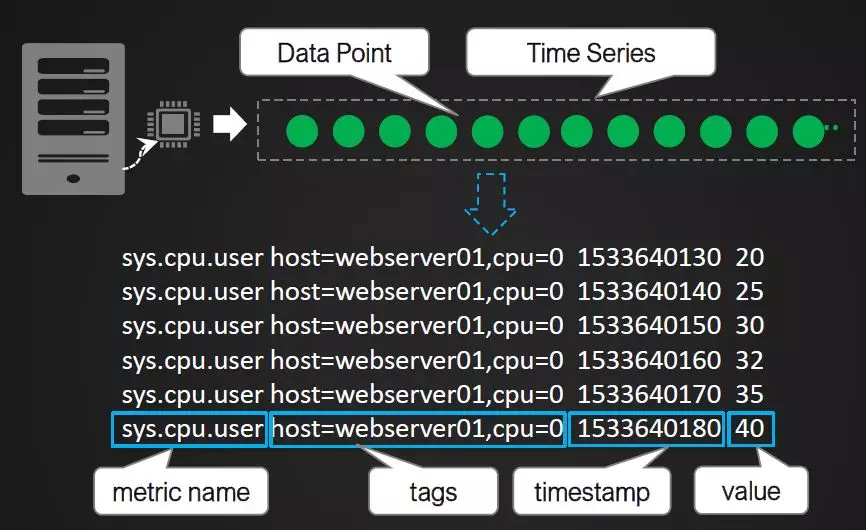
典型场景分析:给定Metric Name以及一组Tags信息,查询某时间范围的所有的Data Points;给定Metric Name以及一组Tags信息,查询某时间范围的聚合结果;给定Metric Name,查询所有相关Time Series在某时间范围的统计信息。
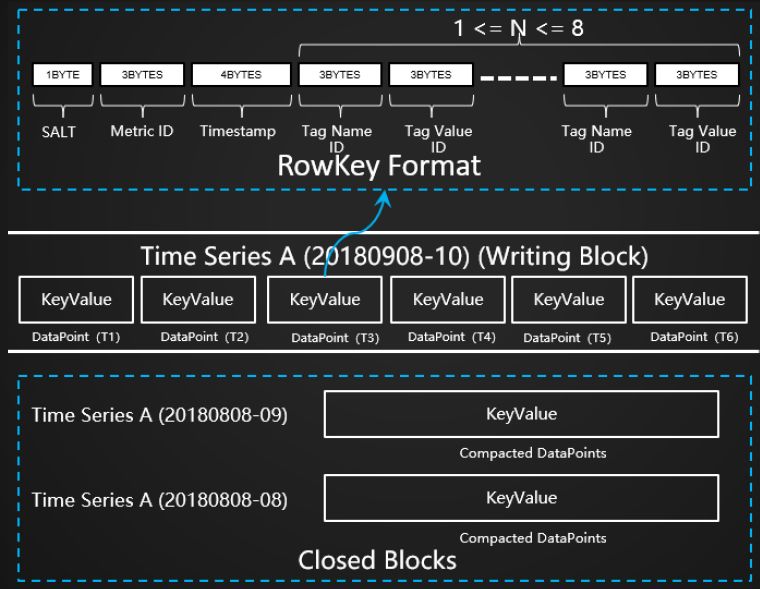
RowKey设计如下图,第一部分有一个SALT决定了数据的分片,第二部分是有关查询都会提供的Metric ID信息,其他包括Timestamp以及tags信息。
2. JanusGraph
JanusGraph—数据模型。主要包含两类数据:顶点(Vertex)和边(Edge)。顶点包含属性信息。边拥有EdgeLabel信息,EdgeLabel拥有Multiplicity属性,用来定义任意两个顶点之间具有统一EdgeLabel的边数量信息,以及定义任意一个顶点的出入度信息(入边数量与出边数量)。边也可以包�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%8E%E7%B4%A2%E5%BC%95%E8%AE%BE%E8%AE%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


