丁香园基于的向量召回应用
丁香园大数据NLP 丁香园大数据
背景
随着BERT,GNN等模型在NLP领域的发展,DNN类模型的语义提取能力又得到进一步提升,我们对文本语义向量也有了更高的期待,期望语义向量或其他模型特征向量可以在召回段发挥更大作用;约2019年初,我们就尝试在推荐业务中引入基于Faiss的向量召回,随后很快意识到,作为一个基础库,Faiss固然可以快速部署,但缺乏分布式方案,数据持久管理等问题令其无法应付大数据场景;Milvus很好的弥补了Faiss的不足,具体来说:分布式解决方案、数据持久化管理、丰富的SDK这些优势都是其他ANN库无法比拟的,另外Milvus的社区很活跃,意味着用户遇到的问题能很快被解决;因此在2020年,丁香园算法组选择Milvus作为向量索引组件,并首先用于社区论坛搜索场景。
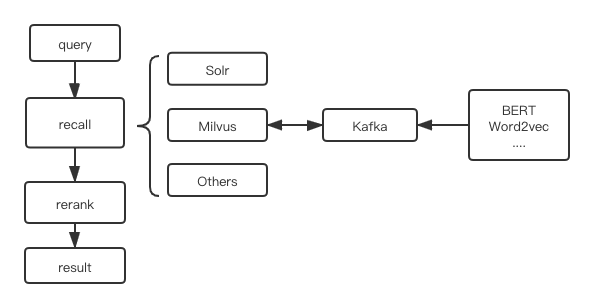
召回流程
搜索召回通常基于Solr/ES这类组件,核心是基于概率检索模型,通常是BM25算法的分词召回;对丁香园的社区搜索场景而言,用于需求的内容不仅包含专业知识,还有考试求职和新闻热点等内容需求,因此query往往描述模糊,中心点不明确;利用BM25不得不接受分词的损失,还需要维护优质的业务相关词典,同时还需要识别关键词的算法辅助;简言之,BM25很难应对模糊和复杂语义表达,因此我们尝试通过不同的文本向量化模型改善对关键词和语义的召回结果
向量模型
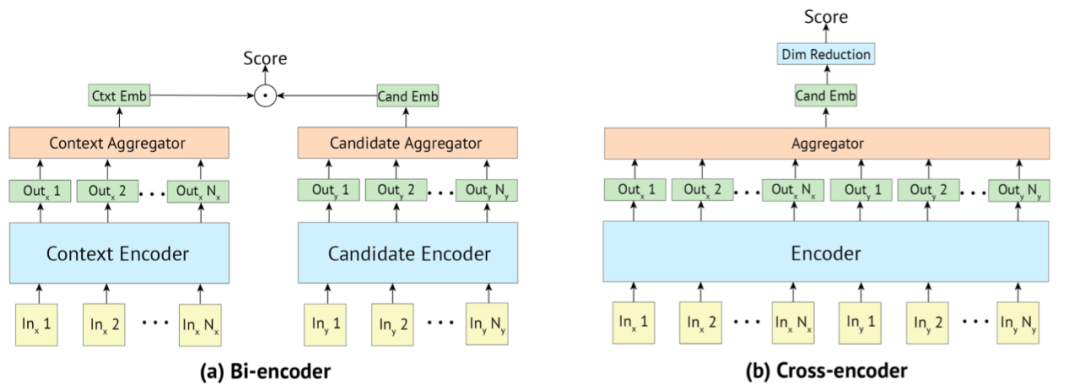
Bi-Encoder[1]
BERT是典型的Cross-Encoder模型,通过12层Multi-Head Attention捕捉全局信息,单句BERT的Bi-Encoder结构会有不小性能损失,但向量召回模型只能选择Bi-Encoder类的结构,将候选文档提前向量化存储,线上服务只计算query的向量
损失函数的选择和负采样策略显得尤为重要;这里我们也选择triplet loss,将负样本分为easy,middle,hard三部分,按2:2:1构造训练数据集
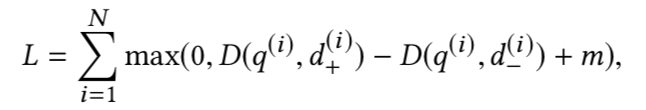
Spherical Embedding[2]
论坛中话题的分布是很不均衡的,包含专业关键词的内容往往不如话题性内容多,所以很难只靠BERT捕捉到这些关键词的语义;我们首先想到word2vec类模型,这篇Spherical Text Embedding可以同时学习文档向量和词向量,实测中对关键词与文档的捕捉效果也不错
传统的word2vec只关注了中心词和周围词的语义关系,忽视了与整篇文章的关系,实际上文章中最先产生的往往中心词/主题词,然后才产生周围词,因此作者提出词向量的生成过程,基于doc向量,先生成中心词向量tgt,再产生周围词向量src;具体的,生成中心词tgt时可以将文档向量doc视作分布空间的均值向量,同理生成src时tgt就是均值向量
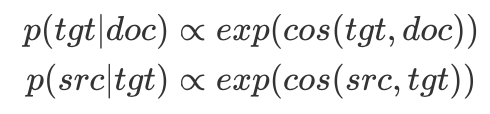
需要指出,这里的三类向量doc,tgt,src都属于von Mises-Fisher(vMF)分布,所以概率密度函数的具体形式,用于计算基于doc的联合概率分布
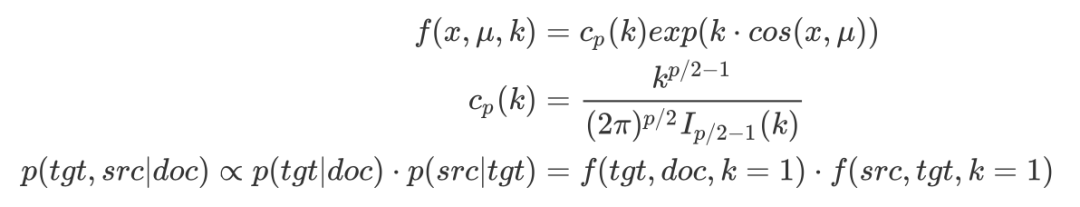
具体的训练思路与word2vec类似,通过max-margin loss最大化正负样本的距离
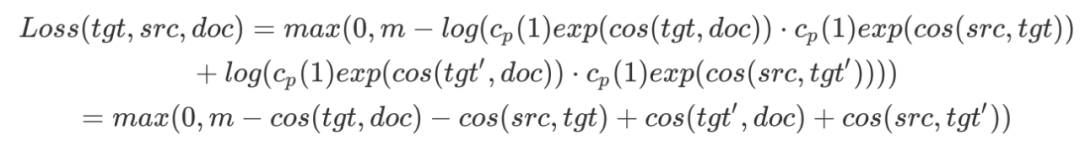
Knowledge Embedding[3]
更直接的关键词向量化方法是利用现有的图谱结构,通过TranE这样的实体关系表示模型,或者node2vec这类邻接图表示模型直接得到关键词向量,这里以ProNE为例;在之前有关GNN的文章中也介绍过,ProNE整体可分为两部分,第一部分对无向图结构的邻接矩阵做稀疏矩
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%81%E9%A6%99%E5%9B%AD%E5%9F%BA%E4%BA%8E%E7%9A%84%E5%90%91%E9%87%8F%E5%8F%AC%E5%9B%9E%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


