一次生产系统问题分析与排查总结

一次生产系统Full GC问题分析与排查总结
背景
最近某线上业务系统生产环境频频CPU使用率过低,频繁告警,通过重启可以缓解,但是过了一段时间又会继续预警,线上两个服务节点相继出现CPU资源紧张,导致服务器卡死不可用,通过告警信息可以看到以下问题:
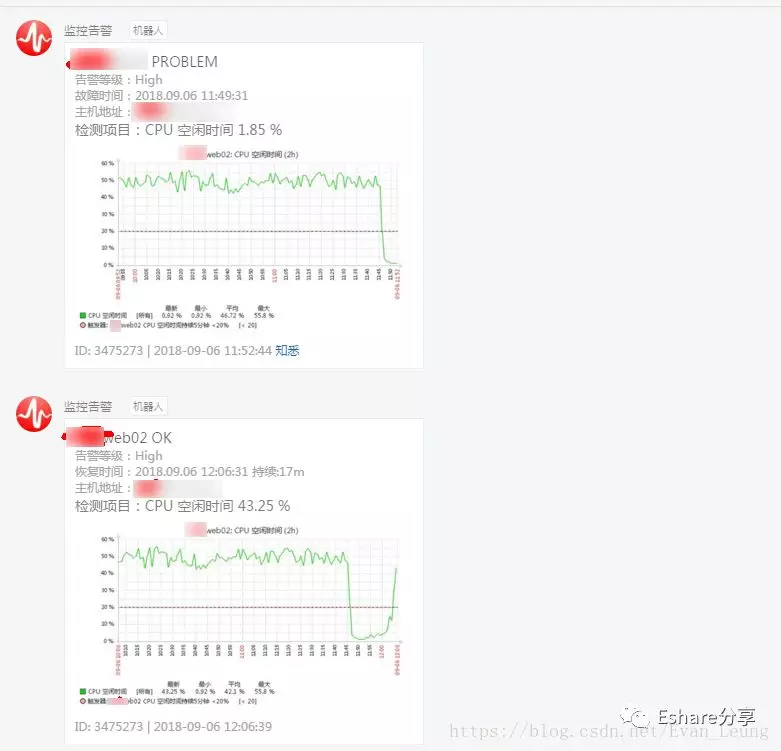
从上图可以看到,目前zabbix监控展示CPU空闲时间已经低于预警线,证明目前CPU资源占用过高,考虑到最近并没有特别开发任务上线,但是最近有发布过一个新的营销活动,有可能是因为突然用户量增长进一步凸显该问题。
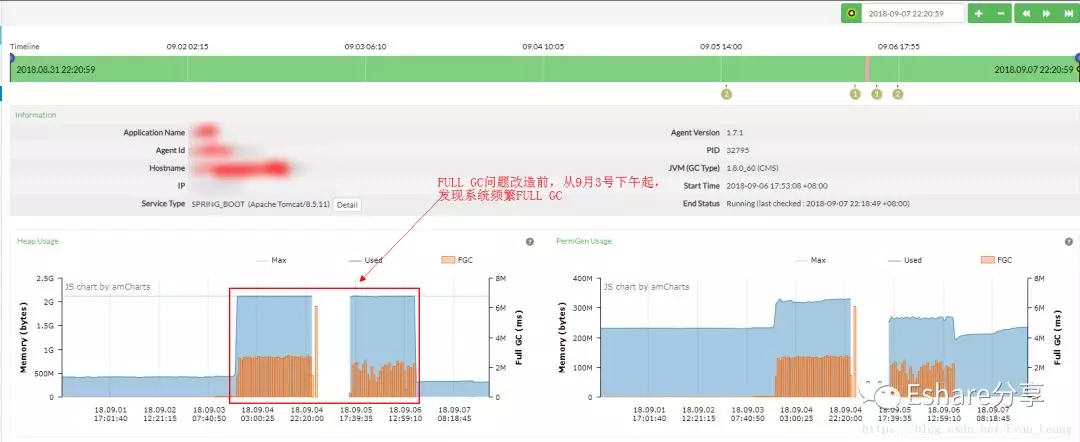
从Pinpoint APM监控工具看到,从9月3号下午开始,系统开始出现频繁full gc的情况,而刚好9月3号下午发布了一个新活动,基本可以断定这可能是用户量突然激增,凸显潜伏已久的系统问题,于是接下来方向就可以往full gc方向去排查,找出引起full gc的代码。
侦查思路
往FULL GC方向侦查,怀疑存在内存泄露
排查路线:
既然上面已经定位到是FULL GC问题,我们就可以用常用FULL C的手段去解决。在这次故障分析我们是利用MAT去做分析,主要对以下几点做排查:
-
程序是否内存泄露
-
程序中是否存在不合理的大对象占用
-
程序中部分对象产生内存是否可以优化
导出JVM dump文件和jstack线程日志,保留案发现场
因为公司不允许个人访问线上服务器,于是让运维同学在服务器出现故障时导出jvm dump文件和jstack线程日志,如果自己有权限去生产服务器的话,可以通过以下指令导出jvm dump文件
jmap -dump:format=b,file=文件名 [服务进程ID]
结合MAT分析工具,找出可疑对象
使用MAT前,先简单介绍下MAT的一些常用的指标和功能概念:
-
Shallow Heap指标:对象本身占用内存的大小,不包含对其他对象的引用,也就是对象头加成员变量(不是成员变量的值)的总和
-
Retained Heap指标:是该对象自己的shallow size,加上从该对象能直接或间接访问到对象的shallow size之和。换句话说,retained size是该对象被GC之后所能回收到内存的总和。
-
Histogram动作:列出每个类的实例数
-
Dominator Tree动作:列出
最大的对象以及它们保存的内容 -
Top Consumers动作: 按照类和包分组打印花费最高的实例
-
Duplicate Classes动作: 检测由多个类加载器加载的类
-
Leak Suspects报告: 包括泄密嫌疑人和系统概述
-
Top Components报告:列出大于总堆的1%的组件的报告
通过Leak Suspects排查内存泄露
在 Ecplise Memory Analyzer 导入JVM dump文件,点击工具栏上的 Leak Suspects 菜单项来生成内存泄露分析报告,也可以直接点击饼图下方的 Reports->Leak Suspects 链接来生成报告。如图:
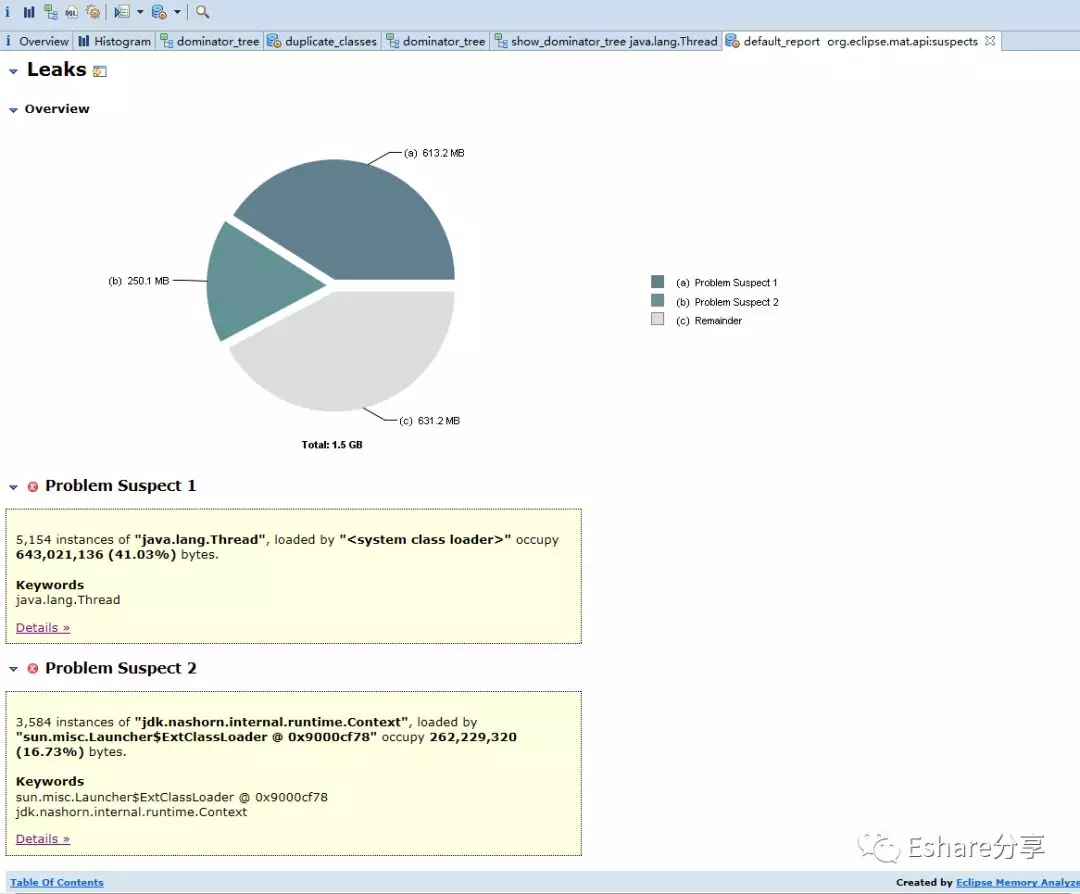
MAT工具分析了heap dump后在界面上非常直观的展示了一个饼图,该图深色区域被怀疑有内存泄漏,可以发现整个heap才1.5G内存,深色区域就占了57.76%。接下来是一个简短的描述,MAT告诉我们存在两个可疑问题
- Problem Suspect 1:告诉我们
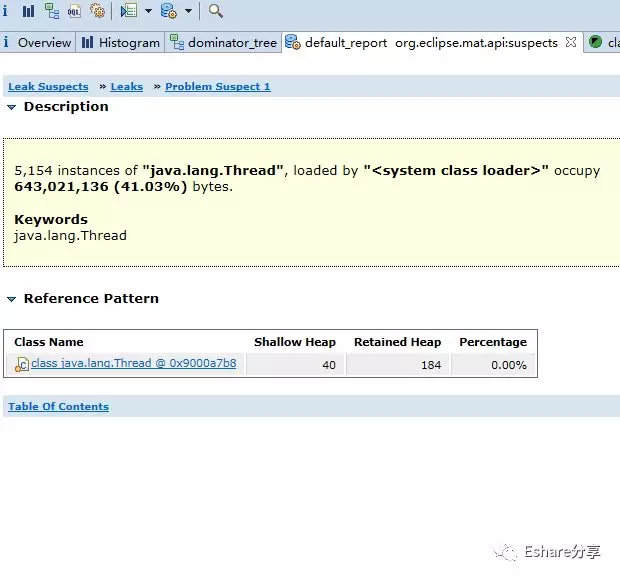
java.lang.Thread线程实例占用了大量内存,一共存在5154个实例,并且明确指出system class loader加载的java.lang.Thread实例占据了643,021,136 (41.03%)字节,并建议用关键字"java.lang.Thread"进行检查。所以,MAT通过简单的两句话就说明了问题所在,就算使用者没什么处理内存问题的经验。在下面还有一个"Details"链接,MAT给了一个参考类。如图:
- Problem Suspect 2: 告诉我们
jdk.nashorn.internal.runtime.Context线程实例占用了大量内存,并且明确指出sun.misc.Launcher$ExtClassLoader @ 0x9000cf78加载的jdk.nashorn.internal.runtime.Context实例占据了262,229,320 (16.73%)字节,并建议用关键字sun.misc.Launcher$ExtClassLoader @ 0x9000cf78 jdk.nashorn.internal.runtime.Context进行检查
通过Top Consumers定位大对象
点击Actions->Top Consumers ,查看大对象有哪些
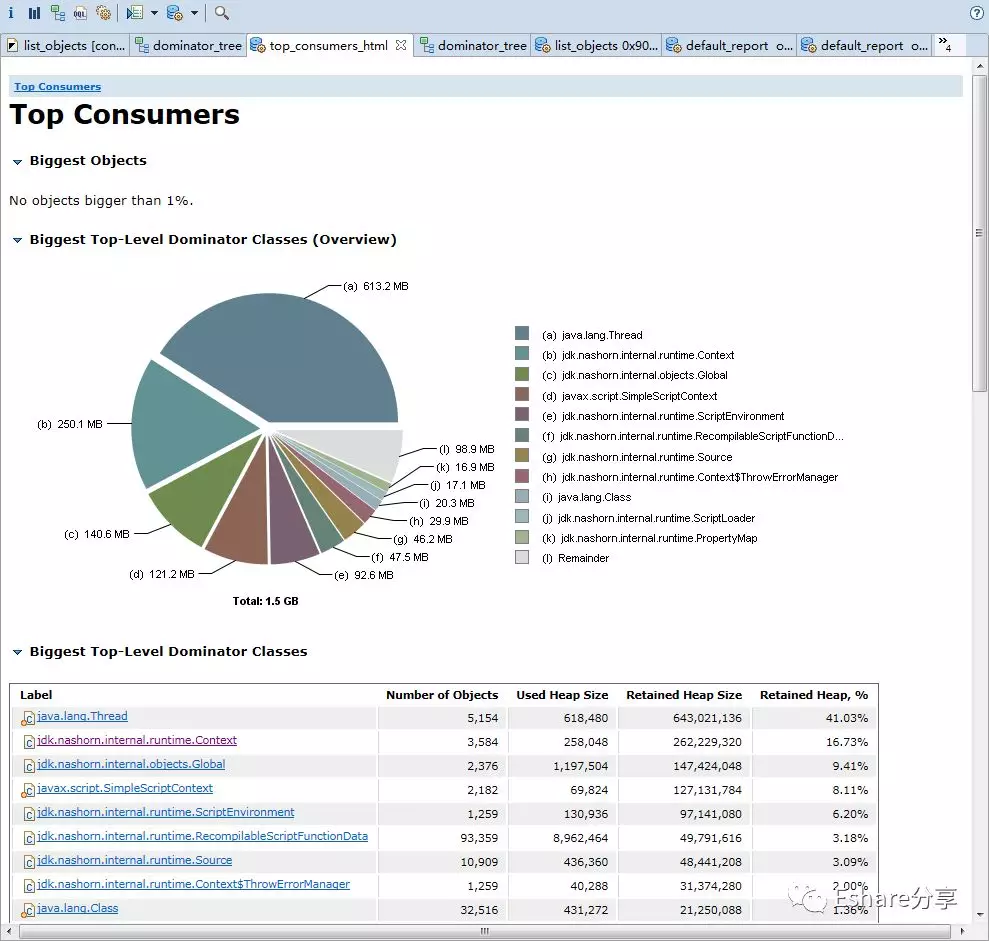
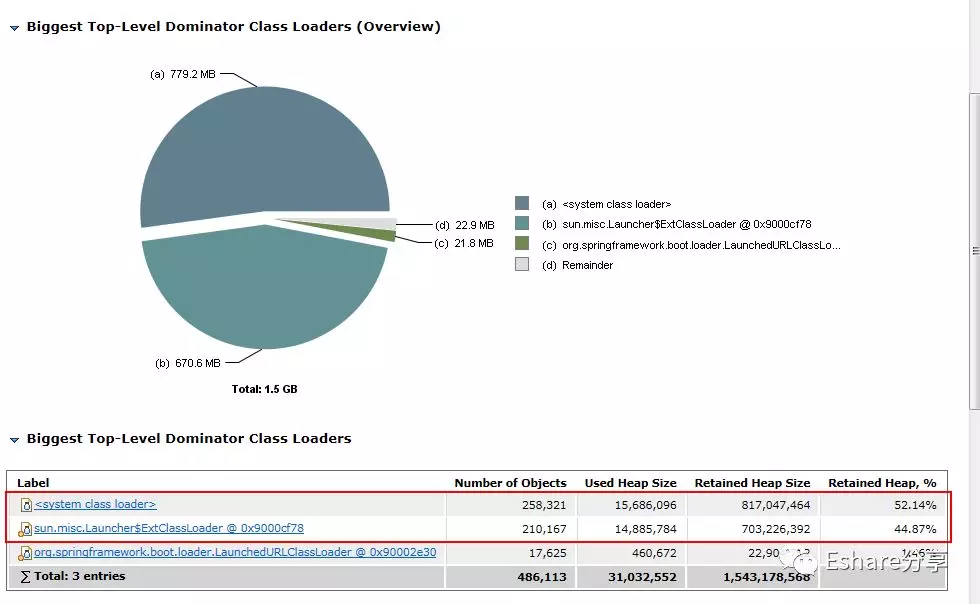
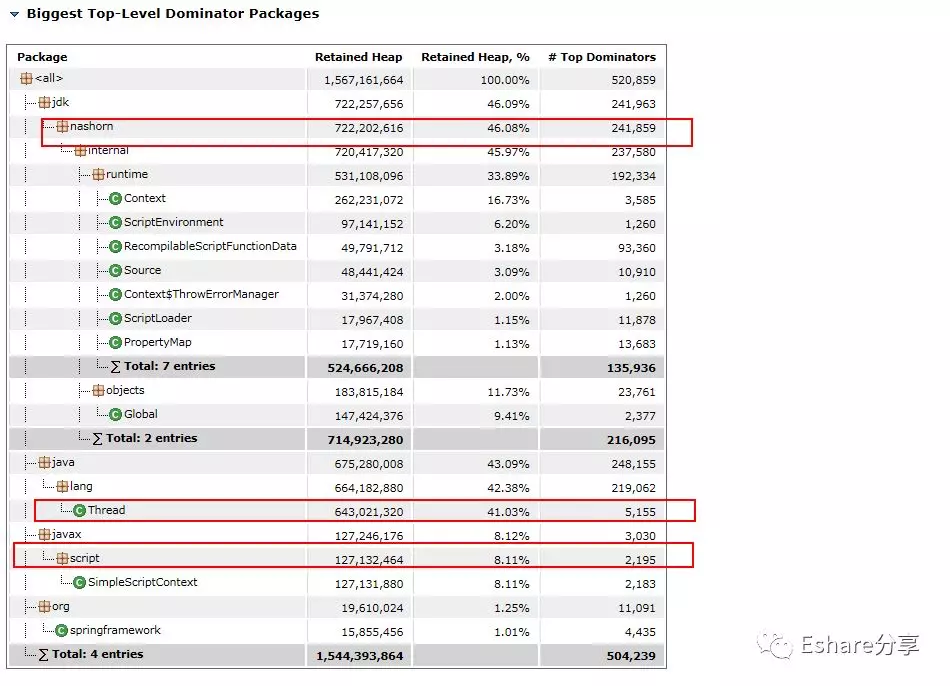
从上图可以看出, java.lang.Thread、 jdk.nashorn.* 和 javax.script.* 这些类实例占据了大部分内存
问题分析
从上面分析报告,可疑大胆推断以下结论:
-
大量
java.lang.Thread实例,明显不合理是线程使用不合理,怀疑有地方不断创建线程,没有使用线程池导致 -
大量
jdk.nashorn.internal._和javax.script._相关实例,而jdk.nashorn.*这个包是Nashorn JavaScript引擎的包,主要是nashorn用于在JVM上以原生方式运行动态的JavaScript代码来扩展Java的功能,javax.script包用于javascript与java交互操作。于是可以基本断定这是跟javascript脚本相关操作有关,应该是有地方不断创建javascript脚本相关对象没有被回收。
结合以上两点,推测应用程序线程和脚本操作部分出现问题,与该系统相关开发人员沟通,确实该系统是有大量javascript脚本操作,是通过Javascript脚本做一些特性开发,然后在在java调用执行。尝试使用包名 jdk.nashorn 查找运维导出的jstack线程日志,看看最接近的业务代码是什么
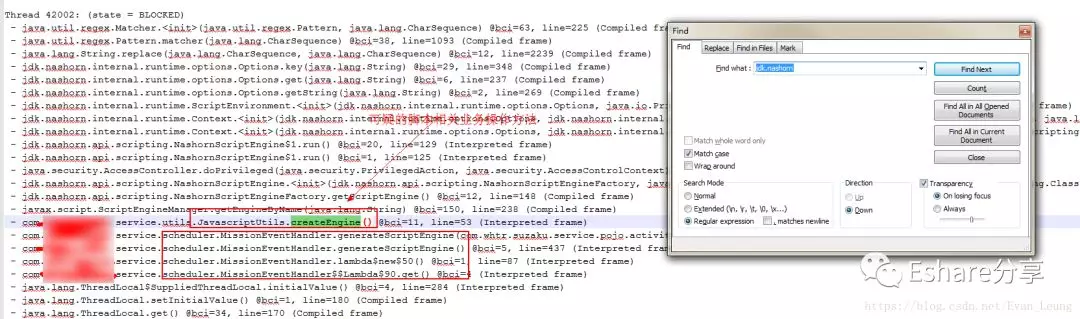
果然看到了线程日志里面找到了疑似线程操作的业务代码,通过查看源码,一步步查看调用链,发现了有个地方会每次实例初始化都会创建一份脚本引擎
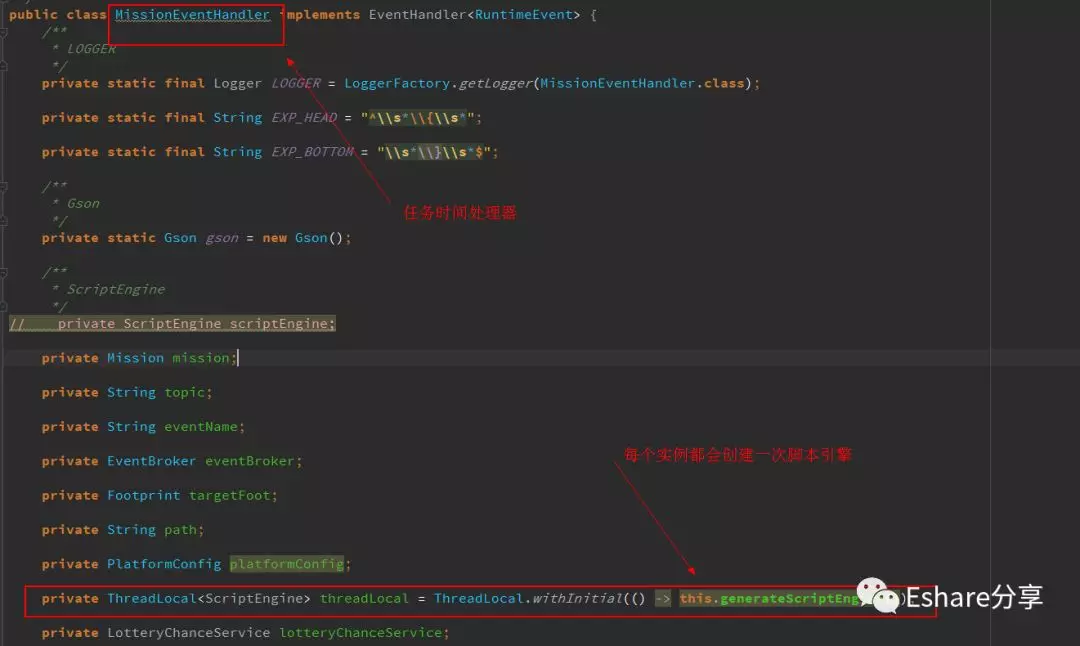
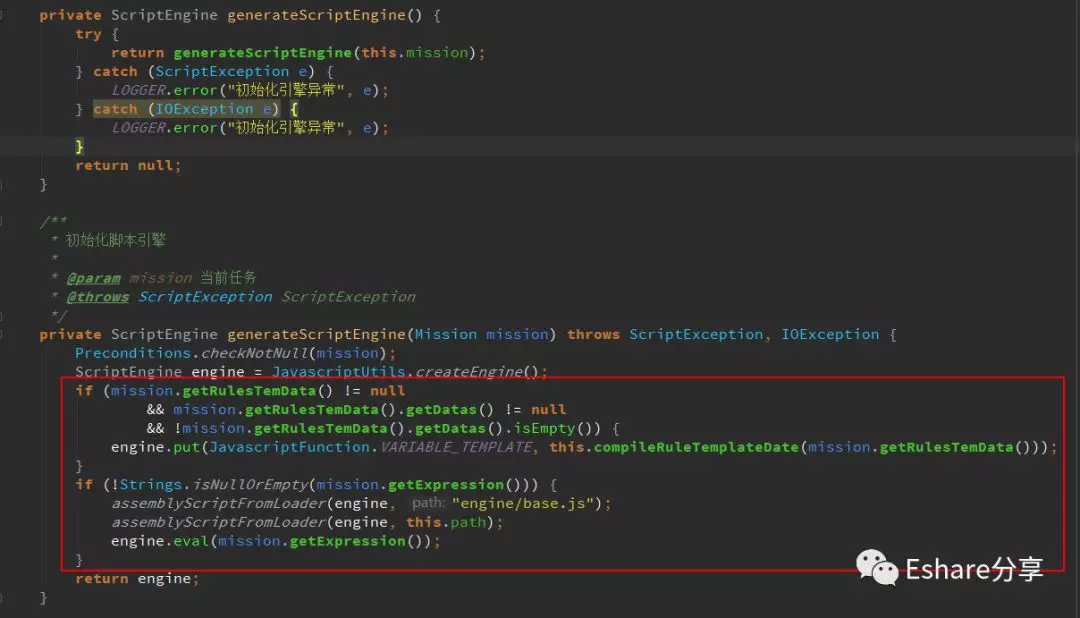
这段代码大概作用是把每个任务的规则脚本存放在脚本引擎,然后存放在 threadLocal 里,每个 MissionEventHandler 实例初始化都会创建一个 threadLocal 用于存放当前线程任务脚本,以防多线程操作同一个 MissionEventHandler 实例会引起脚本因并发被篡改问题。而经过沿着调用链查看源码了解,这些 MissionEventHandler 实例只会业务人员点击任务下线的时候才会进行销毁处理,那就是只要任务不下线,这些任务会一直存活在内存中。
但是只要 MissionEventHandler 实例数量控制好,应该是不会出现上述大量脚本相关实例引发频繁FULL GC问题,接下来我们的侦查方向就是查看 MissionEventHandler 实例创建源头,**是否系统存在批量创建该实例的代码?**继续沿着调用链查看源代码,发现了一个异步观察者类,它是用来通知消息事件的,以下是其中一个方法
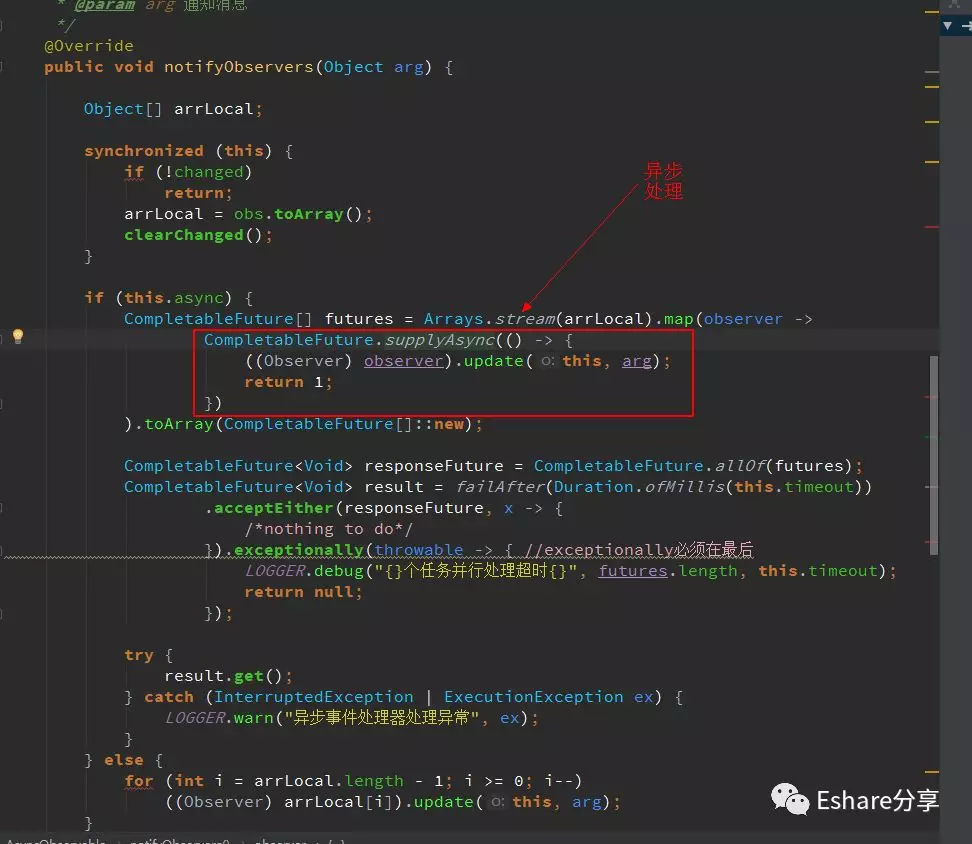
这里是使用了 CompletableFuture 的 supplyAsync(Supplier supplier) 方法进行异步处理,再进一步查看 supplyAsync 的源码
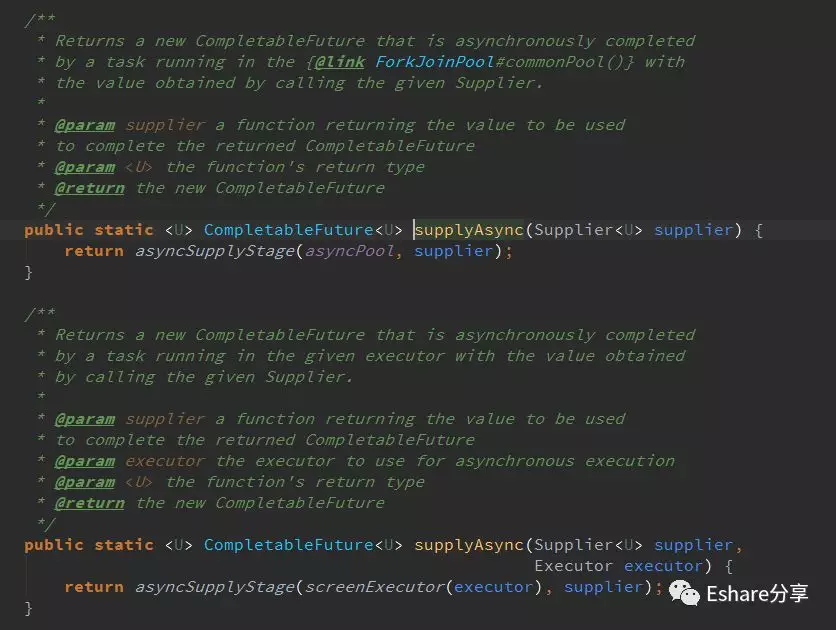
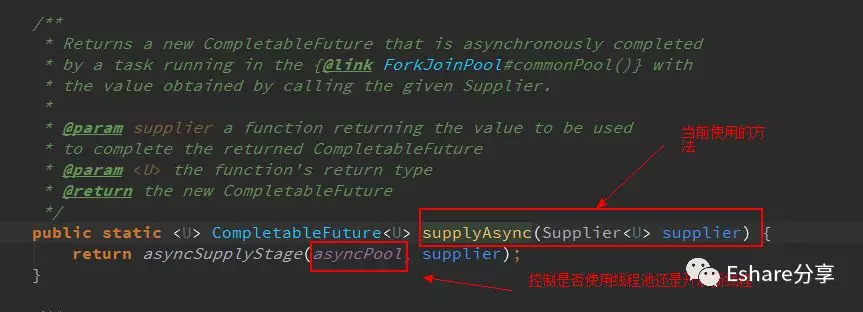
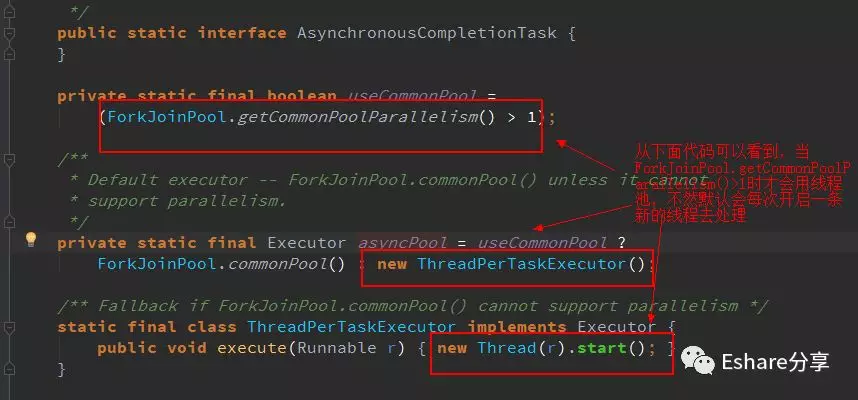
从上面代码可以看到, supplyAsync 有2个重载方法,当我们不指定线程池,它默认是调用第一个方法, ForkJoinPool.getCommonPoolParallelism() > 1 才会使用commonPool线程池,否则该方法默认会每次创建一条新的�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%80%E6%AC%A1%E7%94%9F%E4%BA%A7%E7%B3%BB%E7%BB%9F%E9%97%AE%E9%A2%98%E5%88%86%E6%9E%90%E4%B8%8E%E6%8E%92%E6%9F%A5%E6%80%BB%E7%BB%93/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


