一个轻量级查询框架
Walrus
Introduction
walrus是一个轻量级olap查询框架。它支持多源异构数据源(hdfs,mysql,clickhouse,kylin,druid…),采用 apache spark 作为聚合计算引擎,在雪花模型 上通过json提供ETL建模和ad hoc数据查询服务。
Background
数据分析、ETL开发人员的日常工作可能有60%-80%(猜的)的时间在整合不同的数据源生成特定的数据报表,简单来说可能就是在写这样一条sql:
|
|
walrus的目标就是将这些重复工作配置化,最大限度的减少代码开发。
Architecture
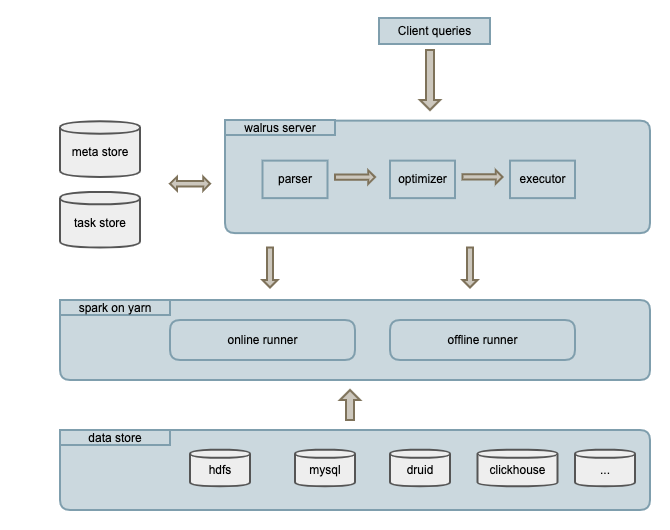
walrus 包含walrus_server、online_runner、offline_runner三个进程:
- walrus_server: spring boot web程序,处理用户元数据管理、任务查询等请求。
- online_runner: spark常驻进程。按需预先申请资源并缓存数据,实时监听、处理walrus_server的online task请求。当查询满足online数据时,任务会优先提交到online_runner。
- offline_runner: spark离线任务,由walrus_server通过本地(spark-submit)或者thrift api提交。
Features
- code-less: 配置化etl、ad hoc query,可以减少开发、分析等人员80%(拍脑袋得出的数字)左右的工作量。
- Heterogeneous data source integration: 异构数据源联合查询,高效整合各个数据源。
- High maintainability metadata management: 高可维护性元数据管理,数据口径、计算逻辑统一管理。
- High scalability: 所有节点无状态,支持水平扩展。
- High performance: 通过预缓存数据、合理切割任务、自定义查询计划重写(查询分支合并、数据倾斜优化…)等提供高性能查询服务。
Design
Execution
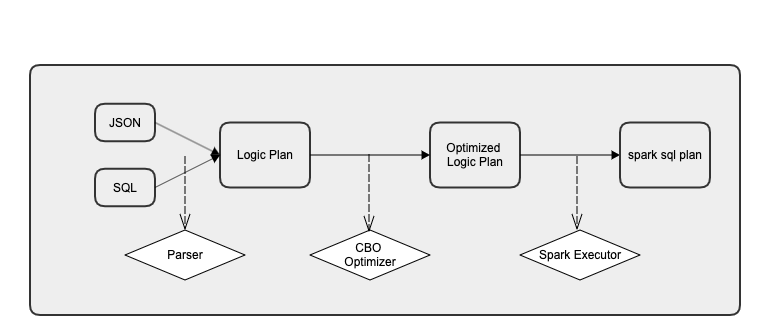
walrus 的执行过程:先解析查询成查询计划,对查询计划进行优化重写,最后翻译成spark sql树并提交到spark执行。
-
解析器(parser): 根据meta把query解析成查询计划。你也可以定制自己的 parser。
-
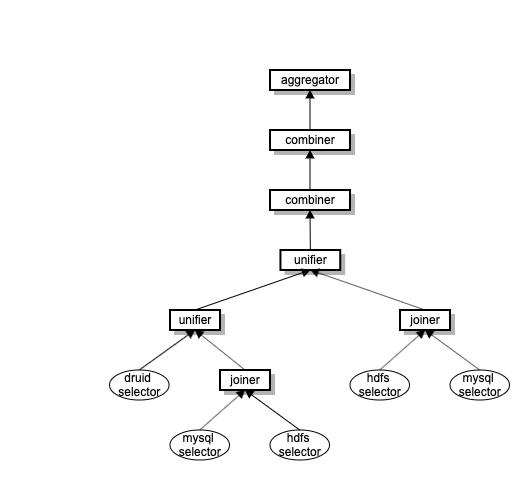
查询计划(Logic Plan): 一棵join+union的嵌套树:
-
优化器(optimizer): 对查询计划树进行重写,默认的有分区合并优化器、数据join倾斜优化器。您可以根据自身的业务数据特点添加自己的 optimizer。
Metadata
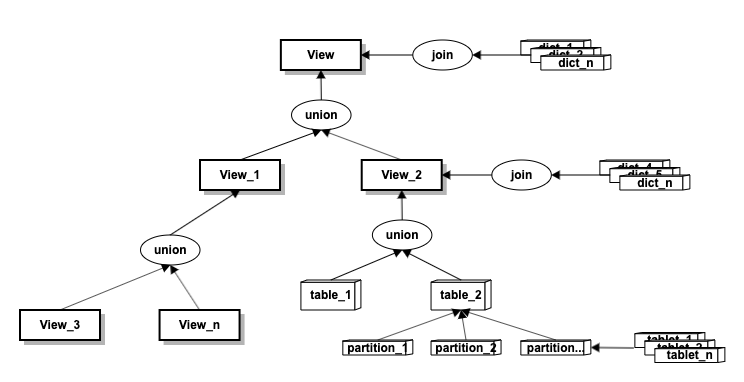
简单来说, Walrus metadata是对雪花模型的抽象。具体定义可参考 pb 文件。
- 视图(vieW) : 一棵join+union的嵌套树,可以做到对事实表和维度表的多层次自由组合。
-
事实表(table)、维度表(dict): 业务事实表和关联维度表。
-
分区(partition):事实表,维度表根据时间跨�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%80%E4%B8%AA%E8%BD%BB%E9%87%8F%E7%BA%A7%E6%9F%A5%E8%AF%A2%E6%A1%86%E6%9E%B6/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


