英伟达推出全模态理解模型 OmniVinci,刷新 SOTA 高出19.05分 --知识铺
英伟达研究团队今日发布了名为 OmniVinci 的全模态理解模型,该模型在关键的全模态理解基准测试中取得了惊人的成果,相较于现有顶尖模型高出19.05分。更为引人注目的是,OmniVinci 仅使用了1/6的训练数据,展现出卓越的数据效率和性能。
OmniVinci 的目标是创建一个能够同时理解视觉、音频和文本的全能 AI 系统,使机器能够像人类一样通过多种感官感知并理解复杂的世界。为了实现这一目标,英伟达团队采取了创新的架构设计和数据管理策略,通过一个统一的全模态潜在空间,将不同感官的信息融合在一起,实现了跨模态的理解和推理。

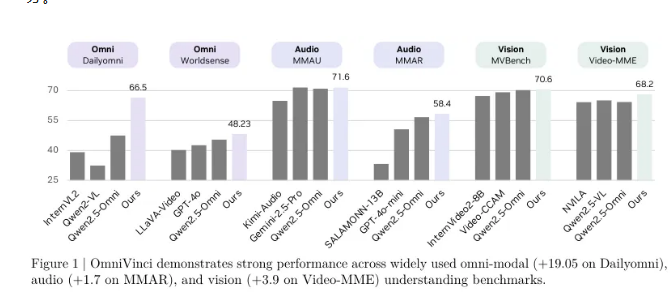
在 Dailyomni 基准测试中,OmniVinci 的表现超过了 Qwen2.5-Omni,其在音频理解的 MMAR 测试中高出1.7分,在视觉理解的 Video-MME 测试中高出3.9分。使用的训练 Token 仅为0.2万亿,而 Qwen2.5-Omni 的训练量为1.2万亿,显示出 OmniVinci 的训练效率是其6倍。
该模型的核心创新在于全模态对齐机制,包括 OmniAlignNet 模块、时间嵌入分组(TEG)和约束旋转时间嵌入(CRTE)三项技术。OmniAlignNet 利用视觉和音频信号之间的互补性,加强了两者的学习与对齐。而 TEG 则通过将视觉和音频信息按时间分组,有效编码了时间关系。CRTE 则进一步解决了时间对齐问题,确保模型能够理解事件的绝对时间信息。
研究团队采用了两阶段的训练方法,首先进行模态特定训练,随后进行全模态联合训练,以逐步提升模型的全模态理解能力。在隐式全模态学习方面,研究者们通过现有的视频问答数据集,进一步提高了模型对音视频的联合理解能力。
OmniVinci 的问世标志着英伟达在多模态 AI 领域的重要突破,预计将在各类应用中推动 AI 技术的发展,助力更智能的系统和服务的出现。该模型的开源发布,也将为全球的研究人员和开发者提供新的机遇,推动 AI 在实际应用中的进一步探索与创新。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/ai002/post/20251029/%E8%8B%B1%E4%BC%9F%E8%BE%BE%E6%8E%A8%E5%87%BA%E5%85%A8%E6%A8%A1%E6%80%81%E7%90%86%E8%A7%A3%E6%A8%A1%E5%9E%8B-OmniVinci%E5%88%B7%E6%96%B0-SOTA-%E9%AB%98%E5%87%BA19.05%E5%88%86/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


