轻松在本地运行Llama2、Gemma等多种大模型,无需GPU! -- 知识铺
该项目允许用户在本地轻松运行包括Llama2、Gemma在内的多种开源大模型,具有以下显著特点:
- 支持使用CPU,使得普通个人电脑也能运行这些大模型。
- 一键安装过程超级简单,同时支持Windows、Linux和Mac操作系统。
- 兼容多种大模型,如Llama 2、Gemma、通义千问以及LLaVA(图片识别)。
- 提供REST API服务,方便与其他应用程序集成。
- 拥有丰富的生态系统,围绕该项目已经开发了多种Web UI、桌面软件和SDK库等。以下是作者在本地离线环境下运行的实战效果展示。
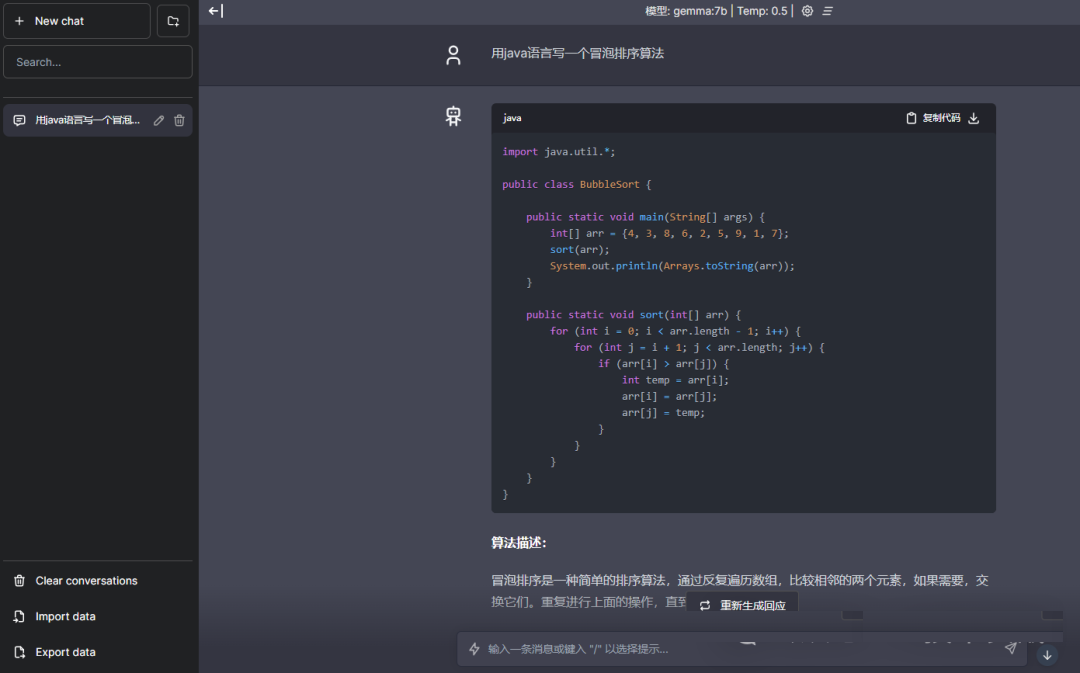
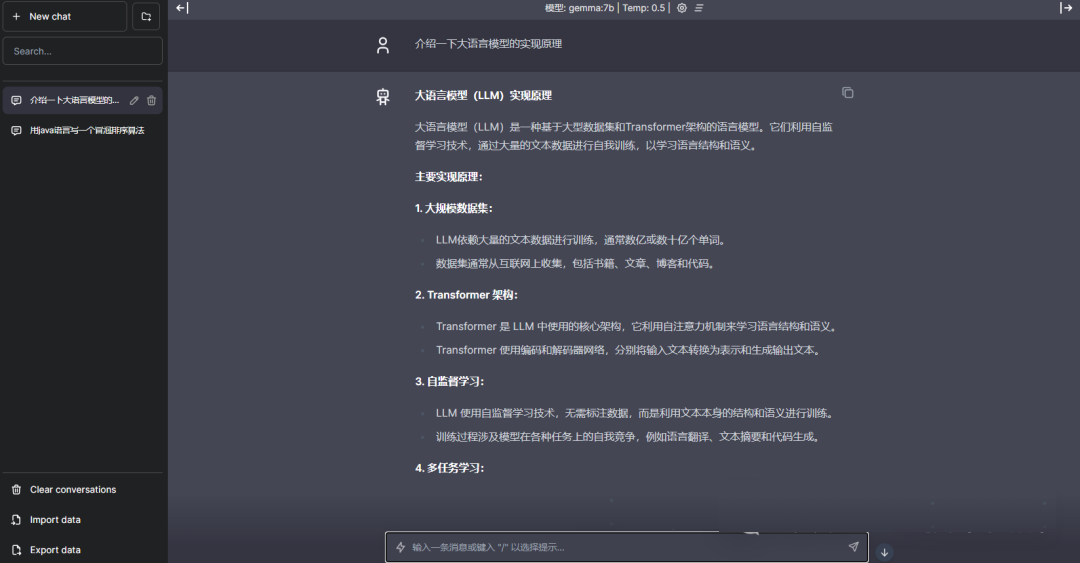
实操部署
下面跟着作者快速实现一个如上图所示的应用。
1.安装运行大模型
在项目的github主页下载windows版本。

下载后双击安装完成,在cmd中输入下面命令,一键运行Llama2模型(作者电脑16G内存,理论上8G也可以使用)。
等待直至出现以下界面,即成功运行。

在"Send a messsage"处输入问题,模型就可以回答了,至此已安装成功,是不是超级简单!

2.部署web界面
下面我们部署一个类似ChatGPT界面的web ui,运行以下docker命令。
<div id="code-lang-bash"><p><code data-highlighted="yes"><table><tbody><tr><td><pre>1
</pre></td><td><pre>docker run -p 3000:3000 ghcr.io/ivanfioravanti/chatbot-ollama:main</pre></td></tr></tbody></table></p></div>
如下图所示,一键部署成功。
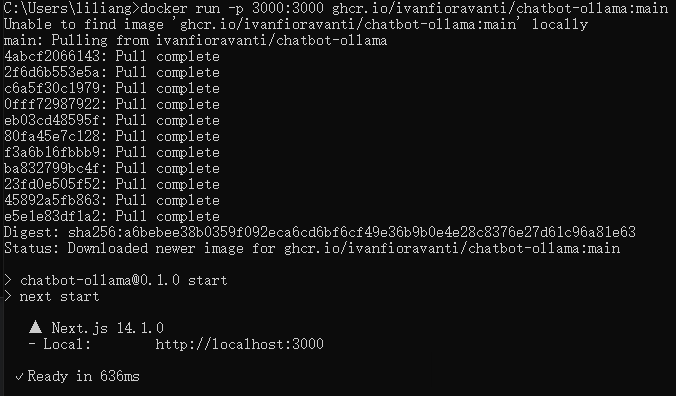
用浏览器打开http://localhost:3000,即可像使用ChatGPT一样使用自己的私有GPT了,重点是可以离线使用,数据更安全!
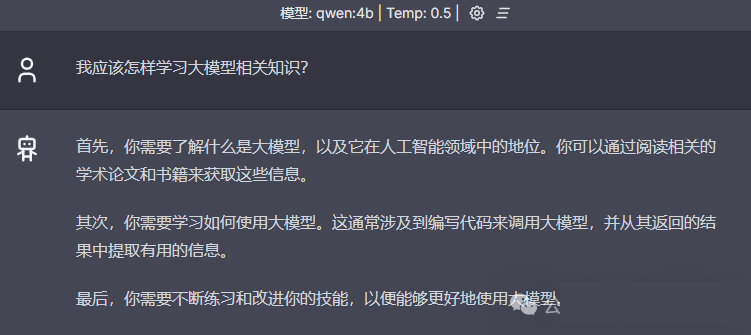
3.使用REST API
截图展示一下REST API的能力,更多参数请查阅官方文档。
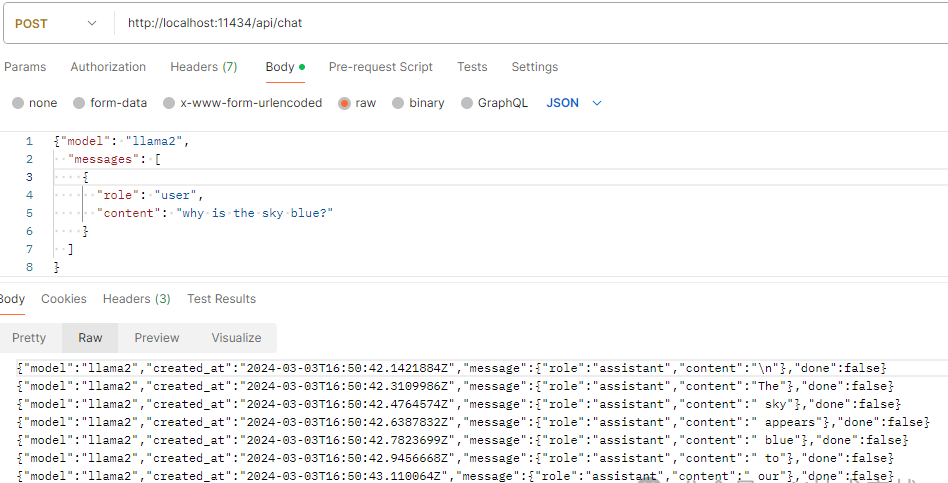
4.图片识别
根据官方文档,使用llava模型可以识别图片,下面是作者测试结果:

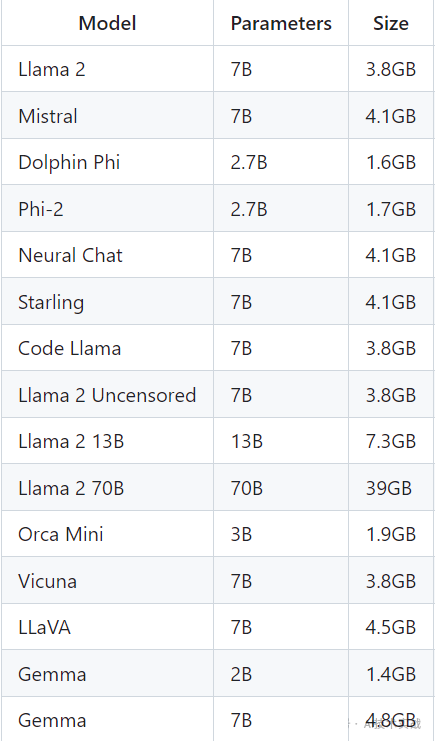
5.内存要求
支持多种模型,每种模型有多个参数,运行7B参数模型需要至少8G内存,运行13B参数模型需要至少16G内存,运行33B参数模型需要至少32G内存。以下是几种模型的参数与模型大小,更多模型可查阅官方文档。
更多功能请参考官方文档
开源地址
github地址 https://github.com/ollama/ollama
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/ai/post/20241218/%E8%BD%BB%E6%9D%BE%E5%9C%A8%E6%9C%AC%E5%9C%B0%E8%BF%90%E8%A1%8CLlama2Gemma%E7%AD%89%E5%A4%9A%E7%A7%8D%E5%A4%A7%E6%A8%A1%E5%9E%8B%E6%97%A0%E9%9C%80GPU--%E7%9F%A5%E8%AF%86%E9%93%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


